GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于GG修改器免root原理_Gg修改器免root怎么使用的内容,赶快来一起来看看吧。
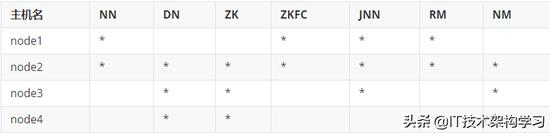
一、虚拟机配置
虚拟机规划
二、Hadoop 高可用(HA)实现(QJM)
1、node1主机上修改配置文件
[root@node1 ~]# vi /opt/hadoop/etc/hadoop/core-site.xml
#修改为如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop-full/</value>
</property>
</configuration>
[root@node1 hadoop]# vi /opt/hadoop/etc/hadoop/hdfs-site.xml
#修改内容为如下:
<configuration>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/hadoop-full/journalnode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
2、分发配置文件至node2,node3,node4
[root@node1 ~]#cd /opt/hadoop/etc/hadoop/
[root@hadoop ~]# scp core-site.xml hdfs-site.xml node2:/`pwd`
[root@hadoop ~]# scp core-site.xml hdfs-site.xml node3:/`pwd`
[root@hadoop ~]# scp core-site.xml hdfs-site.xml node4:/`pwd`
3、启动journalnode
[root@node1 ~]# hadoop-daemon.sh start journalnode
[root@node2 ~]# hadoop-daemon.sh start journalnode
[root@node3 ~]# hadoop-daemon.sh start journalnode
4、HDFS Namenode数据同步
[root@node1 ~]# hdfs namenode -format
2020-01-27 11:09:37,394 mon.Storage: Storage directory /hadoop-full/dfs/name has been successfully formatted.
[root@node1 ~]# hadoop-daemon.sh start namenode
[root@node1 ~]#hdfs namenode -initializeSharedEdits
[root@node1 ~]#hadoop-daemon.sh start namenode
[root@node2 ~]# hdfs namenode -bootstrapStandby
[root@node2 ~]#hadoop-daemon.sh start namenode
5、启动datanode节点
[root@node2 ~]#hadoop-daemon.sh start datanode
[root@node3 ~]# hadoop-daemon.sh start datanode
[root@node4 ~]# hadoop-daemon.sh start datanode
6、提升namenode节点为active状态
hdfs haadmin -transitionToActive nn1
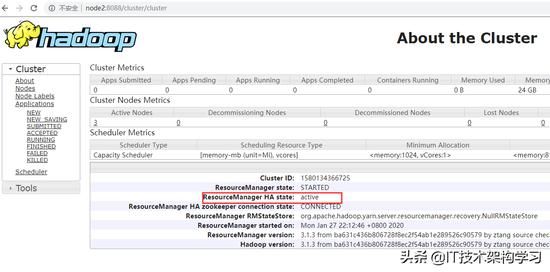
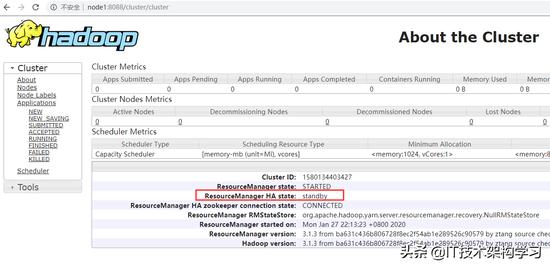
7、验证
[root@node1 ~]# jps
2948 Jps
1829 NameNode
2013 JournalNode
[root@node2 ~]# jps
2029 Jps
1455 NameNode
1519 DataNode
1599 JournalNode
[root@node3 ~]# jps
1335 Jps
1195 DataNode
1275 JournalNode
[root@node4 ~]# jps
997 Jps
967 DataNode
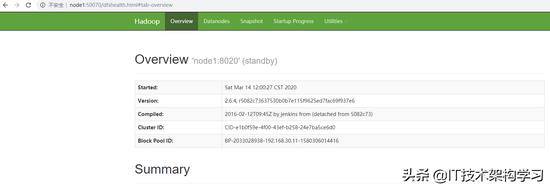
集群启动
8、命令行操作HA集群
[root@node1 ~]#hdfs haadmin -getServiceState nn1
设置namenode为active节点
[root@node1 ~]#hdfs haadmin -transitionToStandby nn1
[root@node1 ~]#hdfs haadmin -failover nn1 nn2
三、Zookeeper安装配置
1、修改主机hosts文件
[root@node2 conf]# vi /etc/hosts
#添加如下内容
127.0.0.1 localhost
2、上传zookeeper安装包到node2上
3、解压安装包到指定目录
[root@node2 ~]# tar -zxvf zookeeper-3.4.6.tar.gz -C /opt/
4、重命名目录
[root@node2 ~]# mv /opt/zookeeper-3.4.6/ /opt/zookeeper
5、修改配置文件
[root@node2 ~]#cd /opt/zookeeper/conf/
[root@node2 conf]#cp zoo_sample.cfg zoo.cfg
[root@node2 conf]#vi zoo.cfg
#12行修改为如下内容
dataDir=/hadoop-full/zookeeper
#文件末尾添加如下内容
server.1=node2:2888:3888
server.2=node3:2888:3888
server.3=node4:2888:3888
5、添加环境变量
[root@node2 ~]# vi /etc/profile.d/hadoop.sh
#修改为如下内容
export JAVA_HOME=/opt/jdk
export HADOOP_HOME=/opt/hadoop
export ZOOKEEPER_HOME=/opt/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$ZOOKEEPER_HOME/bin
[root@node2 ~]# source /etc/profile
6、创建工作目录
[root@node2 ~]# mkdir -p /hadoop-full/zookeeper
[root@node2 ~]# echo 1 >/hadoop-full/zookeeper/myid
7、分发文件
[root@node2 conf]# scp /etc/hosts node3:/etc/hosts
[root@node2 conf]# scp /etc/hosts node4:/etc/hosts
[root@node2 ~]# scp /etc/profile.d/hadoop.sh node3:/etc/profile.d/
[root@node2 ~]# scp /etc/profile.d/hadoop.sh node4:/etc/profile.d/
[root@node3 ~]# source /etc/profile
[root@node4 ~]# source /etc/profile
[root@node2 ~]# scp -r /opt/zookeeper node3:/opt/
[root@node2 ~]# scp -r /opt/zookeeper node4:/opt/
[root@node2 ~]# scp -r /hadoop-full/zookeeper node3:/hadoop-full/
[root@node2 ~]# scp -r /hadoop-full/zookeeper node4:/hadoop-full/
8、修改myid文件
[root@node3 ~]# echo 2 >/hadoop-full/zookeeper/myid
[root@node4 ~]# echo 3 >/hadoop-full/zookeeper/myid
9、启动服务
[root@node2 ~]# zkServer.sh start
[root@node3 ~]# zkServer.sh start
[root@node4 ~]# zkServer.sh start
10、查看状态
[root@node2 opt]# zkServer.sh status
JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@node3 ~]# zkServer.sh status
JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[root@node4 ~]# zkServer.sh status
JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: follower
五、Zookeeper实现Hadoop Namenode HA故障自动切换
1、node1主机上修改配置文件
[root@node1 ~]# vi /opt/hadoop/etc/hadoop/core-site.xml
#原有内容上添加为如下内容:
<configuration>
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>
[root@node1 hadoop]# vi /opt/hadoop/etc/hadoop/hdfs-site.xml
#原有内容上添加为如下内容:
<configuration>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
2、分发配置文件至node2,node3,node4
[root@node1 ~]#cd /opt/hadoop/etc/hadoop/
[root@hadoop ~]# scp core-site.xml hdfs-site.xml node2:/`pwd`
[root@hadoop ~]# scp core-site.xml hdfs-site.xml node3:/`pwd`
[root@hadoop ~]# scp core-site.xml hdfs-site.xml node4:/`pwd`
3、zookeeper FailerController格式化
[root@node1 ~]# hdfs zkfc -formatZK
2020-01-27 11:26:40,326 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK
4、namenode节点安装psmisc(ZKFC主机)
[root@node1 ~]#yum install psmisc -y
[root@node2 ~]#yum install psmisc -y
5、node2免密登录node2设置
[root@node2 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:21X44T83NPr3k/FabLoSGZZDCoGck1ncNiowoLJGlr0 root@node2
The key’s randomart image is:
+---[RSA 2048]----+
| .. . Boo |
| .o o B o + .. |
|o+ . o . + +..o |
|+. . . . . =+ . |
|.. E .S ..+oo |
|. o .o o+.|
| . . o oX|
| . .**|
| .++=|
+----[SHA256]-----+
[root@node2 ~]# cd ~/.ssh/
[root@node2 .ssh]# ssh-copy-id node1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host ’node1 (192.168.30.11)’ can’t be established.
ECDSA key fingerprint is SHA256:/V6z9w2ts2Ei8dgcKAlJCGozcmoeWNSNyctvHWjdoJk.
ECDSA key fingerprint is MD5:09:41:c7:ad:2b:65:77:6f:eb:af:77:be:8f:e3:1f:15.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node1’s password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh ’node1’"
and check to make sure that only the key(s) you wanted were added.
[root@node2 .ssh]# ssh node1
6、启动集群
[root@node1 hadoop]# start-dfs.sh
7、验证:
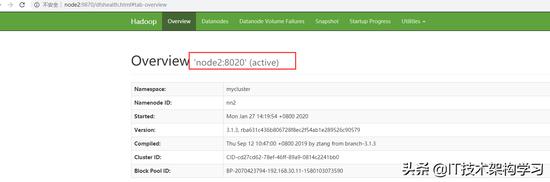
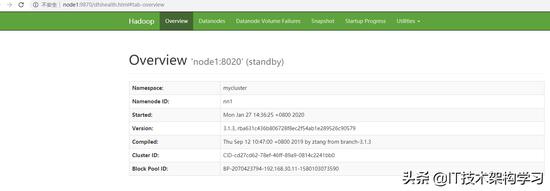
六、ResourceManager HA 配置
1、修改mapred-site.xml
[root@node1 hadoop]# vi /opt/hadoop/etc/hadoop/mapred-site.xml
#修改为如下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2、修改yarn-site.xml
[root@node1 hadoop]# vi /opt/hadoop/etc/hadoop/yarn-site.xml
#修改为如下内容
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启日志聚合 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- 配置yarn为高可用 -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 集群的唯一标识 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>cl uster1</value>
</property>
<property>
<!-- ResourceManager ID -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>yarn.resourcemanager.zk-address</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>
3、把修改得配置文件分发到node2,node3,node4主机中
[root@node1 hadoop]# cd /opt/hadoop/etc/hadoop/
[root@node1 hadoop]# scp hadoop-env.sh mapred-site.xml yarn-site.xml node2:/`pwd`
[root@node1 hadoop]# scp hadoop-env.sh mapred-site.xml yarn-site.xml node3:/`pwd`
[root@node1 hadoop]# scp hadoop-env.sh mapred-site.xml yarn-site.xml node4:/`pwd`
4、启动服务
[root@node1 hadoop]# start-yarn.sh
[root@node2 ~]# yarn-daemon.sh start resourcemanager
最后说明,因为本环境搭建考虑的每个人的技术基础,所以把每个环节拆开部署,让大家能看懂其中的原理,后期熟练掌握的话可以合并步骤进行配置,有问题也可以留言或者私信我都可以。
以上就是关于GG修改器免root原理_Gg修改器免root怎么使用的全部内容,感谢大家的浏览观看,如果你喜欢本站的文章可以CTRL+D收藏哦。
gg修改器小米root权限_小米怎么给gg修改器root权限 大小:18.52MB12,785人安装 大家好,今天小编为大家分享关于gg修改器小米root权限_小米怎么给gg修改器root权限……
下载
gg修改器免root如何安装_如何使用gg修改器免root 大小:12.23MB12,756人安装 大家好,今天小编为大家分享关于gg修改器免root如何安装_如何使用gg修改器免root的……
下载
gg修改器中文版咋用,gg修改器中文版使用方法 大小:12.18MB11,870人安装 如果你是一个游戏玩家,那么你一定听说过gg修改器。gg修改器是一款针对Android游戏……
下载
gg修改器免root没病毒的,GG修改器免root没病毒的神器 大小:17.34MB11,765人安装 GG修改器免root没病毒,是一款专门针对安卓游戏进行修改的软件。它能够帮助用户实现……
下载
gg游戏修改器修改同人游戏, gg游戏修改器:神器般的同人游戏修改利器 大小:12.26MB11,959人安装 作为一个玩家,你是否曾经因为某些同人游戏的设定或剧情让你不满?或者是游戏进度……
下载
gg修改器免root版的网址_gg修改器最新版免root 大小:14.81MB12,762人安装 大家好,今天小编为大家分享关于gg修改器免root版的网址_gg修改器最新版免root的内……
下载
gg修改器root工具,GG修改器ROOT工具Android游戏爱好者的福音 大小:17.43MB11,834人安装 在游戏爱好者中,GG修改器ROOT工具也许是众人皆知、而又深受喜爱的一款应用。这款工……
下载
gg修改器免root版怎样用_GG修改器免ROOT版 大小:3.50MB12,865人安装 大家好,今天小编为大家分享关于gg修改器免root版怎样用_GG修改器免ROOT版的内容,……
下载
gg修改器没root如何使用,解锁你的游戏潜力使用GG修改器没root也有办法 大小:17.32MB11,479人安装 如果你是一位游戏爱好者,就一定会遇到某些游戏中的瓶颈,这时候就需要一个强大的辅……
下载
正版的最新gg修改器,正版的最新gg修改器,你值得拥有 大小:10.36MB11,683人安装 对于喜欢游戏的玩家而言,修改器是一个非常有用的工具。在众多的修改器中,最新的gg……
下载