
GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器无须root_GG修改器修改不了的内容,赶快来一起来看看吧。
垃圾回收,需要先找出什么是垃圾,之后才能谈回收问题,一些方法
引用计数在 C++ 和 Rust 之类的语言中比较常用,Java 中用的是 Tracing 的方式,遍历对象间的引用。那么从哪开始遍历呢?这些遍历的起始点称为 GC Root,在 Java 中有这么一些:
上面的 GC Roots 没列全,非专业做 GC 的话其实也没必要掌握。关键需要了解 GC Root 代表的就是我们“确定”还在用的引用,比如方法里创建了一个 HashMap,方法还返回前都“确定”还会用到,就认为是 Root(这里说得不准确,可能 new 出的对象就没人用,但从算法角度还是认为它是 Root)。
有了 GC Root,要如何扫描呢?Java 里用的是三色算法。三色算法是一个“逻辑算法”,本质上就是是树/森林的遍历,但为了方便描述和讨论,把遍历过程中的节点细化成三个状态:
每次迭代都会将 Grey 引用的 White 对象标成 Grey,并将 Grey 对象标记成 Black,直到没有 Grey 对象为止。标记之后一个对象最终只会是 Black 或者 White,其中所有可达的对象最终都会是 Black,如下例:
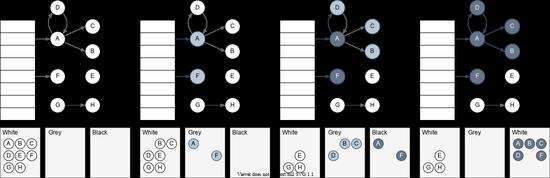
这里并没的说明 Grey 对象的遍历顺序,所以实际上实现成宽搜或深搜都是可以的。
上节说考虑的是“什么是垃圾”的问题,标识出了垃圾对象,下一步是如何“回收”。通常有 Sweep/Compact/Copy 三种处理方式,直观上理解是这样的:
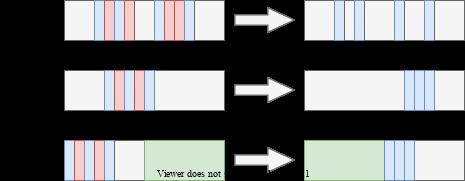
三种方法有各自的优势,需要使用方自己做权衡。这里引用 R 大的帖子 总结如下:
|
Mark-Sweep |
Mark-Compact |
Mark-Copy |
|
|
速度 |
中等 |
最慢 |
最快 |
|
空间开销 |
少(但有碎片) |
少(无碎片) |
通常需要活动对象的 2 倍(无碎片) |
|
移动对象? |
否 |
是 |
是 |
这几种方法都有使用。如 CMS 最后的 S 代表的就是 Sweep;传统的 Serial GC 和 Parallel GC,包括新的 G1、Shenandoah、ZGC 都可以理解成是 Compact;而 Serial, Parallel, CMS 的 Young GC 都用的是 Copy。
如果接触过 GC,会知道 GC 最让人头疼的是 Stop-the-World 停顿,GC 算法的一些阶段会把用户线程的执行完全暂定,造成不可预期的停顿。我们希望这个时间尽可能短甚至完全去除。GC 的“效率”跟多方面因素有关,比如活动对象(active object)越多,Marking 需要遍历的节点越多,越耗时;比如内存越大,Sweep 清理垃圾时需要遍历的区域越大,耗时越长;等等。于是人们在想怎么“偷懒”来提升效率。
分代假设就是这样一个发现/假设:
从对象存活时间和对象数量的视角来看,分代假设就是这样的(原图):

当然这个假设不一定符合实际,比如 LRU 缓存,越老的对象越可能被淘汰。不过多数应用还是符合这个假设的。于是如果将对象按时间分成年轻代和老年代,我们就可以偷懒了:
于是在分代假设下,传统的 GC 流程变成了这样(原图):
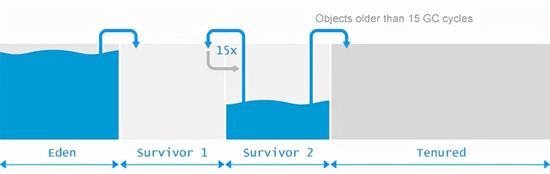
新对象从 Eden 区分配,Young GC 时存活的进 Survivor 区,Survivor 区有两个,相互做 Copy 操作。在 Survivor 区存活了 15 次 GC 的,就移动到 Old/Tenured 区。Young GC 时会忽略 Tenured 区。
前面提到了 GC 最让人头疼的是 STW 停顿,分代策略让我们频繁做 Young GC,少量做 Full GC,但真的做 Full GC 时停顿时间还是非常大,于是人们想到了并发。CMS 中的 CM 指的是 Concurrent Mark 即是“并发标记”。而 Shenandoah GC 和 ZGC 又实现了“回收”的并发。
开始前要注意的是“并发”和“并行”在 GC 里的概念是不一样的,可以这么去区分:
如早期的 Parallel GC 本质上就是“并行”而不是“并发”,GC 过程还是 STW 的。虽然仅一字之差,“并发”会带来非常多的问题,新的 GC 算法也用了许多解决方案,但这些方案都是有代价的。
前面提到 Java 里会用三色算法来遍历堆中的引用关系,算法假设引用关系在遍历期间不变,如果变化了会怎么样呢?主要有两个场景:新增对象和引用修改。
第一个问题是新增对象:在标记期间新增的对象通过旧的 GC Roots 可能不可达,标记结束后可能还是 White,会被认为是垃圾而被错误释放。
第二个问题是:标记期间应用线程修改引用会影响正确性。
其中一些修改不会造成错误,只是会影响回收效率。如断开 Black1 -> Black2 引用, Black2 最终应该被释放,但不释放 Black2 不会造成程序错误。但如果修改同时满足下面两个条件则会影响正确性:
条件一和条件二的共同结果是,标记过程会遗漏这个 White 对象,因为通过 Grey 对象不可达,且 Black 对象不会被二次扫描。于是 GC 结束后它会被释放,但它同时还被 Black 对象引用着,程序会出错。
并发标记算法如何解决这两个问题?
Incremental update 的想法是破坏条件一。标记期间记录增加的每个 Black -> White 引用中的 White 对象,把它标记为 Grey。对于标记期间新增的对象,则需要在标记结束前重新扫描一次 GC Roots 做 Marking。
在实现上,就需要去“监听” Black -> White 引用的创建。以 CMS 为例:
在标记过程中新增的 Black -> White 的引用,都可以在 Card Table 中找到。于是要保证标记的正确性,只需要在标记结束前从 Card Table 中找到 foo -> bar 的引用,再用三色算法遍历一下 bar 及其引用即可。当然还需要再重新扫描 GC Roots 处理新增的对象。
实现细节上,Card Table 里并不会像 HashMap 一样记录一个 A -> B 的映射,这样存储访问的效率都很低。Card Table 是一个 bitmap,先将内存按 512B 分成一个个区域,称为 Card,每个 Card 对应 bitmap 里的一位。bitmap 置 1 代表对应 Card 中包含需要重新扫描的对象。在标记结束前找到为 dirty 的 Card,重新扫描其中的(所有)对象及其引用。
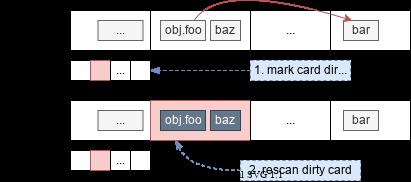
Snapshot At The Beginning(SATB) 的想法则是破坏条件二,在标记开始之前做快照,快照之后新增的对象都不处理,认为是 Black;当要删除旧的引用(换句话说,在新的赋值 obj.foo = bar 生效之前),记录旧的引用,这样在标记结束前再扫描这些旧的引用即可,这样原先的 Grey -> White 的引用虽然断开了,但 White 对象依旧可以扫到。以 G1 为例:
最终的操作与 Incremental Update 类似,在标记结束前,重新扫描 RSet 里记录的指针,也会有额外的操作把 [TAMS, Top] 之间的对象标记成 Black。
实现细节上,G1 将内存分成了多个 Region。每个 Region 有自己的一个 RSet,这点与 Card Table 不同,它是全局的。RSet 的结构如下:
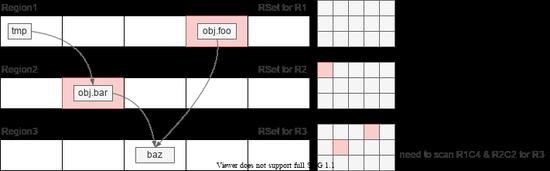
当然,RSet 的具体实现和上图不太一样,如一般用 HashMap 来存储;但如果 region 里的 card 数过多就会退化成 bitmap;引用的 region 过多,则 region 也会用 bitmap 来存储。细节上也有很多优化,比如 barrier 的更新是先记录到一个 Thread Local 的队列上,异步更新到 RSet 中的。
不管是在 CMS 和 G1 里,并发的内容主要还是以 Marking 为主,Copy/Compact 还是 STW 的。如 CMS 的 Young GC Copy,G1 的 Evacuation Compact,都是 STW 的。为了追求接近硬实时的效果,Shenandoah GC 和 ZGC 都尝试将“回收”阶段并发化,减少 Copy/Compact 的 STW 停顿时间。而正如并发标记里会需要处理新对象和并发修改的问题,并发 Copy/Compact 也会遇到不少问题。
Copy/Compact 的过程,需要先将对象复制到新的位置,再修改所有该对象的引用,指向新的地址。在 STW 的方案下,过程如下(摘自 https://shipilev.net/talks/javazone-Sep2018-shenandoah.pdf ):
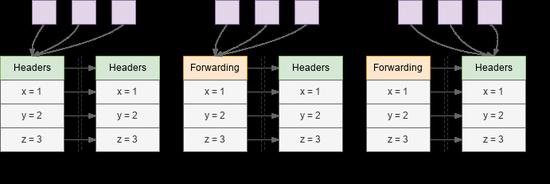
但允许并发时,会出现不同线程对不同副本做读写的问题,此时应该保留哪个副本?
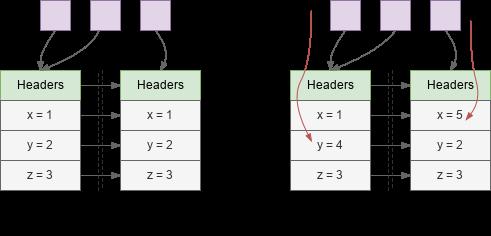
并发回收算法的核心也就在于怎么解决 Copy 期间多线程对两个副本的同步。下面会介绍 Shenadoah GC 和 ZGC 的做法,它们都会用到 load barrier 来修正并发情况下应用线程的读操作。
Shenandoah GC 对这个问题的解法是:为每个对象都增加一个 Forwarding 指针,在 Copy/Compact 过程中,通过 CAS 来更新这个指针指向新的副本,期间指向该对象的指针的读写,都要经过 Forwarding 找到正确的对象,如下图所示。
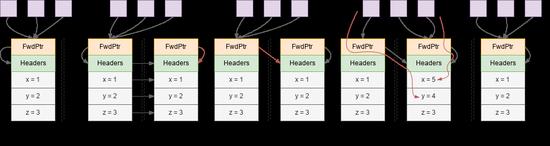
这个方案的有效性本身并不难理解。技术上,这个方案需要拦截所有的对读写操作,让它通过 FwdPtr 完成。Shenandoah GC 通过 Write Barrier + Load Barrier 来完成。
一个小细节:在执行 Write 操作时,Write Barrier 如果发现当前处于并发 Copy 阶段,但对象还没有被 Copy,则 Write Barrier 会执行 Copy 操作,否则写到旧的副本里也没有意义。但读操作时并不会主动做 Copy 的动作。
这个算法的难点在于实现和优化。Shenandoah 中做了许多额外的处理:例如在更多地方增加 barrier,比如 == 、compareAndSwap等操作;例如去除对 NULL 检查的 Barrier,把 barrier 放在循环外来提高性能。
另外 Brooks Pointer 中的 Brooks 是人名,Rodney A. Brooks 在 1984 年为 Lisp 发明的。
一个 A->B 的引用有两个参与者,引用方 A 和被引用方 B。Shenandoah 是在被引用方 B 中增加 Forwarding Pointer 来屏蔽底层的 Copy 的动作。而 ZGC 则是在引用方 A 处动手,具体有这么几个机制:
如果画成图,大概是这样:
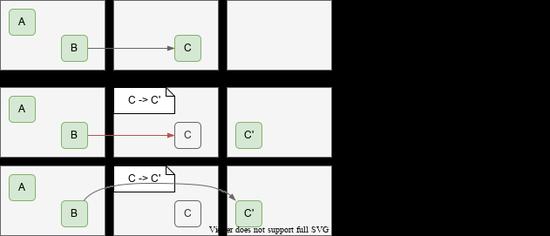
相比于 Brooks Pointer,这个算法会更受限,比如无法支持 32 位的机器,不能开启指针压缩等等。
先假设这样一个情形,如果我们看 GC 的日志,记录 GC 开始结束,(虚构)画出下面这张图:
图中 2 的位置,我们发现应用程序的 TPS 和响应时间都变差了,但看了下 GC 的日志发现每次 GC 的停顿时间都很短,可能会觉得 GC 没有问题。但如果仔细观察,会发现 GC 变得频繁了,而 GC 是消耗 CPU 时间的,更频繁的 GC 意味着应用线程能用的时间也更少了,因此会造成 TPS 和响应时间变差的情况。
除了 GC 带来的停顿之外,要意识到 GC 是有代价的:
一般 GC 算法保证的停顿的时间越短,则消耗的 CPU 越大,换言之吞吐越小。没有通用的最优的 GC 算法,根据应用程序的不同和愿意付出的代价来选择 GC 算法吧。
文章中粗浅地讨论了 Java GC 算法中的几个方面:
以上就是关于gg修改器无须root_GG修改器修改不了的全部内容,感谢大家的浏览观看,如果你喜欢本站的文章可以CTRL+D收藏哦。

gg游戏修改器 百度网盘, 为什么我选择使用gg游戏修改器 大小:10.28MB9,543人安装 玩游戏已经成为了现代社会中很重要的娱乐活动之一,但是,当我们碰到难以通过、剧情……
下载
gg修改器安卓11免root_GG修改器安卓10 大小:3.81MB10,696人安装 大家好,今天小编为大家分享关于gg修改器安卓11免root_GG修改器安卓10的内容,赶快……
下载
GG修改器安卓下载,GG修改器下载最新版 大小:17.28MB10,869人安装 GG修改器安卓版是一款实用的游戏辅助工具,此版本在原版的基础上免除了root权限,还……
下载
华为gg修改器怎么下免root_华为gg修改器修改无效 大小:5.99MB10,840人安装 大家好,今天小编为大家分享关于华为gg修改器怎么下免root_华为gg修改器修改无效的……
下载
gg修改器在哪下手机版中文,什么是GG修改器? 大小:9.27MB9,895人安装 GG修改器是一款功能强大的手机游戏辅助工具,通过修改游戏内的参数和数据来实现加速……
下载
GG修改器一拳超人,一拳超人gg修改器脚本 大小:13.91MB10,890人安装 GG修改器教程(以少女咖啡枪为例) 1.1 设置内存范围 选择内存范围改为图一图二 有用……
下载
gg修改器中文官方文档_gg中文版修改器 大小:5.19MB10,902人安装 大家好,今天小编为大家分享关于gg修改器中文官方文档_gg中文版修改器的内容,赶快……
下载
gg修改器怎么root,掌握GG修改器是Android手机的必备技能 大小:16.22MB9,347人安装 随着科技的不断进步,手机已经成为了现代人生活中不可或缺的一部分。作为手机用户,……
下载
gg官方最新修改器,GG官方最新修改器:让游戏更加美妙 大小:9.85MB9,721人安装 作为一名游戏爱好者,大家都不想遇到卡顿、掉帧等情况。然而,这些情况在游戏中时有……
下载
gg修改器如何给root权限_gg修改器为什么要root权限 大小:10.01MB10,739人安装 大家好,今天小编为大家分享关于gg修改器如何给root权限_gg修改器为什么要root权限……
下载