GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于用gg修改器必须root吗_gg修改器免root吗?的内容,赶快来一起来看看吧。
一般来说缓存的更新有两种情况:
对于一个更新操作简单来说,就是先去各级缓存进行删除,然后更新数据库。这个操作有一个比较大的问题,在对缓存删除完之后,有一个读请求,这个时候由于缓存被删除所以直接会读库,读操作的数据是老的并且会被加载进入缓存当中,后续读请求全部访问的老数据。
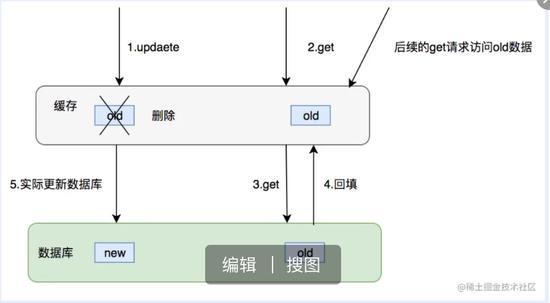
对缓存的操作不论成功失败都不能阻塞我们对数据库的操作,那么很多时候删除缓存可以用异步的操作,但是先删除缓存不能很好的适用于这个场景。
先删除缓存也有一个好处是,如果对数据库操作失败了,那么由于先删除的缓存,最多只是造成Cache Miss。
如果我们使用更新数据库,再删除缓存就能避免上面的问题。但是同样的引入了新的问题,试想一下有一个数据此时是没有缓存的,所以查询请求会直接落库,更新操作在查询请求之后,但是更新操作删除数据库操作在查询完之后回填缓存之前,就会导致我们缓存中和数据库出现缓存不一致。
为什么我们这种情况有问题,很多公司包括Facebook还会选择呢?因为要触发这个条件比较苛刻。
对比上面4.1的问题来说这种问题的概率很低,况且我们有超时机制保底所以基本能满足我们的需求。如果真的需要追求完美,可以使用二阶段提交,但是其成本和收益一般来说不成正比。
当然还有个问题是如果我们删除失败了,缓存的数据就会和数据库的数据不一致,那么我们就只能靠过期超时来进行兜底。对此我们可以进行优化,如果删除失败的话 我们不能影响主流程那么我们可以将其放入队列后续进行异步删除。
大家一听到缓存有哪些注意事项,肯定首先想到的是缓存穿透,缓存击穿,缓存雪崩这三个挖坑的小能手,这里简单介绍一下他们具体是什么以及应对的方法。
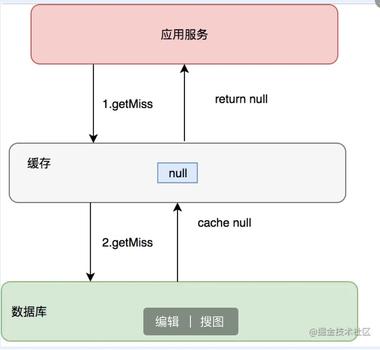
缓存穿透是指查询的数据在数据库是没有的,那么在缓存中自然也没有,所以,在缓存中查不到就会去数据库取查询,这样的请求一多,那么我们的数据库的压力自然会增大。
为了避免这个问题,可以采取下面两个手段:
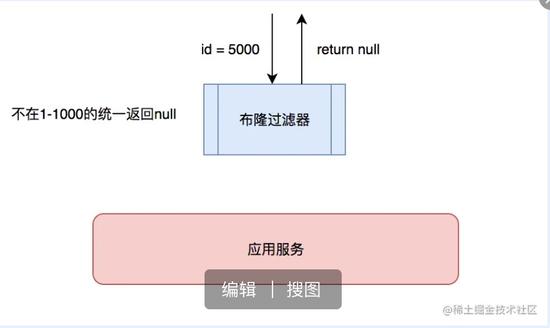
2. 制定一些规则过滤一些不可能存在的数据,小数据用BitMap,大数据可以用布隆过滤器,比如你的订单ID 明显是在一个范围1-1000,如果不是1-1000之内的数据那其实可以直接给过滤掉。
对于某些key设置了过期时间,但是其是热点数据,如果某个key失效,可能大量的请求打过来,缓存未命中,然后去数据库访问,此时数据库访问量会急剧增加。
为了避免这个问题,我们可以采取下面的两个手段:
缓存雪崩是指缓存不可用或者大量缓存由于超时时间相同在同一时间段失效,大量请求直接访问数据库,数据库压力过大导致系统雪崩。
为了避免这个问题,我们采取下面的手段:
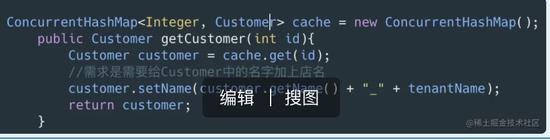
缓存污染一般出现在我们使用本地缓存中,可以想象,在本地缓存中如果你获得了缓存,但是你接下来修改了这个数据,但是这个数据并没有更新在数据库,这样就造成了缓存污染:
上面的代码就造成了缓存污染,通过id获取Customer,但是需求需要修改Customer的名字,所以开发人员直接在取出来的对象中直接修改,这个Customer对象就会被污染,其他线程取出这个数据就是错误的数据。
要想避免这个问题需要开发人员从编码上注意,并且代码必须经过严格的review,以及全方位的回归测试,才能从一定程度上解决这个问题。
序列化是很多人都不注意的一个问题,很多人忽略了序列化的问题,上线之后马上报出一下奇怪的错误异常,造成了不必要的损失,最后一排查都是序列化的问题。列举几个序列化常见的问题:
//jdk 7
class A{
int a;
int b;
}
//jdk 8
class A{
int b;
int a;
}
复制代码
序列化的问题必须得到重视,解决的办法有如下几点:
对于大量使用本地缓存的应用,由于涉及到缓存淘汰,那么GC问题必定是常事。如果出现GC较多,STW时间较长,那么必定会影响服务可用性。这一块给出下面几点建议:
很多人对于缓存的监控也比较忽略,基本上线之后如果不报错然后就默认他就生效了。但是存在这个问题,很多人由于经验不足,有可能设置了不恰当的过期时间,或者不恰当的缓存大小导致缓存命中率不高,让缓存就成为了代码中的一个装饰品。所以对于缓存各种指标的监控,也比较重要,通过其不同的指标数据,我们可以对缓存的参数进行优化,从而让缓存达到最优化:
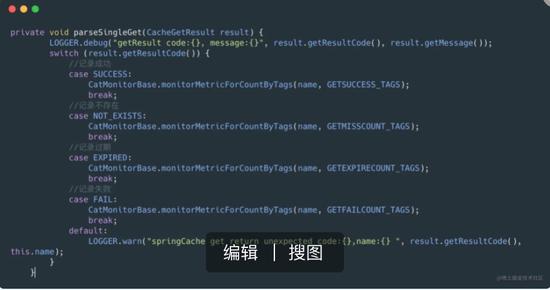
上面的代码中用来记录get操作的,通过Cat记录了获取缓存成功,缓存不存在,缓存过期,缓存失败(获取缓存时如果抛出异常,则叫失败),通过这些指标,我们就能统计出命中率,我们调整过期时间和大小的时候就可以参考这些指标进行优化。
一个好的剑客没有一把好剑怎么行呢?如果要使用好缓存,一个好的框架也必不可少。在最开始使用的时候大家使用缓存都用一些util,把缓存的逻辑写在业务逻辑中:
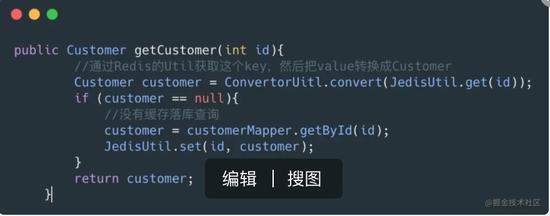
上面的代码把缓存的逻辑耦合在业务逻辑当中,如果我们要增加成多级缓存那就需要修改我们的业务逻辑,不符合开闭原则,所以引入一个好的框架是不错的选择。
推荐大家使用JetCache这款开源框架,其实现了Java缓存规范JSR107并且支持自动刷新等高级功能。笔者参考JetCache结合Spring Cache, 监控框架Cat以及美团的熔断限流框架Rhino实现了一套自有的缓存框架,让操作缓存,打点监控,熔断降级,业务人员无需关心。上面的代码可以优化成:

对于一些监控数据也能轻松从大盘上看到:
想要真正的使用好一个缓存,必须要掌握很多的知识,并不是看几个Redis原理分析,就能把Redis缓存用得炉火纯青。对于不同场景,缓存有各自不同的用法,同样的不同的缓存也有自己的调优策略,进程内缓存你需要关注的是他的淘汰算法和GC调优,以及要避免缓存污染等。分布式缓存你需要关注的是他的高可用,如果其不可用了如何进行降级,以及一些序列化的问题。一个好的框架也是必不可少的,对其如果使用得当再加上上面介绍的经验,相信能让你很好的驾驭住这头野马——缓存。
以上就是关于用gg修改器必须root吗_gg修改器免root吗?的全部内容,感谢大家的浏览观看,如果你喜欢本站的文章可以CTRL+D收藏哦。
gg修改器最新版官方汉化,GG修改器最新版官方汉化,打游戏无压力 大小:16.19MB9,719人安装 玩游戏是许多人日常娱乐的方式,但有些游戏可能需要大量的时间和精力才能达到期望的……
下载
gg无需root游戏修改器,GG无需root游戏修改器,玩游戏就是这么方便 大小:12.46MB9,781人安装 如果你是一名游戏玩家,那么你肯定知道游戏修改器的存在。游戏修改器可以让你轻松地……
下载
纵横免ROOT框架(gg修改器)下载v1.0 安卓版,gg修改器免root框架下载及其使用 大小:4.58MB10,948人安装 如果有一天,你穿上西服,成为别人的新郎,我闭口不提,以往的疯狂。如果有一天,我……
下载
gg修改器免root框_gg修改器免root使用教程 大小:17.94MB10,654人安装 大家好,今天小编为大家分享关于gg修改器免root框_gg修改器免root使用教程的内容,……
下载
最新官网gg修改器, 前言:最新官网gg修改器 大小:10.79MB9,758人安装 作为一名游戏爱好者,我们总是不断地尝试着不同的游戏,并在不断地努力中成长。虽然……
下载
gg修改器下载,GG修改器怎么改代码 大小:8.77MB10,831人安装 功能全且非常厉害的全能修改器工具,为您带来免费的辅助工具,担心会封号的玩家可以……
下载
gg修改器专用免root的框架_GG修改器免root框架在哪 大小:18.60MB10,621人安装 大家好,今天小编为大家分享关于gg修改器专用免root的框架_GG修改器免root框架在哪……
下载
gg修改器中文版怎么下载_gg修改器下载中文怎么用? 大小:16.60MB10,782人安装 大家好,今天小编为大家分享关于gg修改器中文版怎么下载_gg修改器下载中文怎么用?的……
下载
GG修改器中文苹果版,GG修改器中文苹果版自由修改游戏 大小:11.89MB9,593人安装 现今游戏产业越来越繁荣,玩家对于游戏的期待也越来越高。出于对游戏深厚的热爱,许……
下载
方舟gg修改器免root,方舟gg修改器免root让游戏更有趣 大小:9.10MB9,434人安装 随着游戏的不断发展,越来越多的玩家开始追求个性化的游戏体验。而方舟gg修改器免ro……
下载