
GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于root后不能用gg修改器_不root能用gg修改器吗的内容,赶快来一起来看看吧。
这里不做赘述,仅截图展示,更多详情参考文档:https://docs.nebula-.cn/nebula-spark-connector/ 2。
|
名称 |
值 |
推荐 |
|
本地磁盘 SSD |
2 T |
至少 2 T |
|
CPU |
16 C * 4 |
128 C |
|
内存 |
128 GB |
128 G |
|
名称 |
版本号 |
|
Nebula Graph |
3.0.0 |
|
Nebula Spark Connector |
3.0.0 |
|
Hadoop |
2.7.2U17-10 |
|
Spark |
2.4.5U5 |
|
名称 |
值 |
|
数据量 |
200 G |
|
实体 Vertext |
9.3 亿 |
|
关系 Edge |
9.7 亿 |
大体也就三部曲:
以下操作使用的 root,非 root 就加个 sudo 执行即可。
执行下面命令:
wget https://os-cdn.nebula-.cn/package/3.0.0/nebula-graph-3.0.0.el7.x86_64.rpm
wget https://oss-cdn.nebula-.cn/package/3.0.0/nebula-graph-3.0.0.el7.x86_64.rpm.sha256sum.txt
rpm -ivh nebula-graph-3.0.0.el7.x86_64.rpm
注:默认安装路径:/usr/local/nebula/,务必保证所在磁盘空间充足。
sed -i ’s?--meta_server_addrs=127.0.0.1:9559?--meta_server_addrs=172.16.8.15:9559,172.16.8.176:9559,172.16.10.149:9559?g’ *.conf
sed -i ’s?--local_ip=127.0.0.1?--local_ip=172.16.10.149?g’ *.conf
sed -i ’s?--meta_server_addrs=127.0.0.1:9559?--meta_server_addrs=172.16.8.15:9559,172.16.8.176:9559,172.16.10.149:9559?g’ *.conf
sed -i ’s?--local_ip=127.0.0.1?--local_ip=172.16.8.15?g’ *.conf
sed -i ’s?--meta_server_addrs=127.0.0.1:9559?--meta_server_addrs=172.16.8.15:9559,172.16.8.176:9559,172.16.10.149:9559?g’ *.conf
sed -i ’s?--local_ip=127.0.0.1?--local_ip=172.16.8.176?g’ *.conf
注:ip 地址是内网地址,用来集群间通信。
启动之后,增加 Storage 服务:
ADD HOSTS 172.x.x.15:9779,172.1x.x.176:9779,172.x.1x.149:9779;
注:增加 Storage 服务为 v3.x 版本以上所需操作,如果你使用的是 v2.x 可忽略本步骤。
/usr/local/nebula/scripts/nebula.service start all
上述命令启动服务,执行下面命令检查服务是否启动成功:
ps aux|grep nebula
结果如下 3 个服务进程:
/usr/local/nebula/bin/nebula-metad --flagfile /usr/local/nebula/etc/nebula-metad.conf
/usr/local/nebula/bin/nebula-graphd --flagfile /usr/local/nebula/etc/nebula-graphd.conf
/usr/local/nebula/bin/nebula-storaged --flagfile /usr/local/nebula/etc/nebula-storaged.conf
注:如果少于 3 个,就多执行几次 /usr/local/nebula/scripts/nebula.service start all,再不行就 restart。
我选择的是 Nebula Graph Studio,访问:http://n01v:7001 即可使用 Studio(注:这里是我自己的网络环境,读者不可访问)
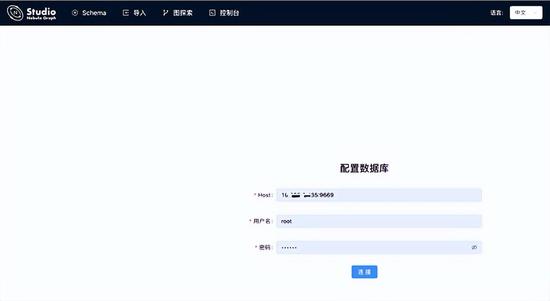
这里可以阅读下官方文档的常用 nGQL 命令:https://docs.nebula-.cn/3.0.1/2.quick-start/4.nebula-graph-crud
注册 Nebula 集群:
ADD HOSTS 172.x.x.121:9779, 172.16.11.218:9779,172.16.12.12:9779;
列出所有节点,查看 STATUS 列是否为 ONLINE,可通过 SHOW HOSTS; 或 SHOW HOSTS META;。
创建 Space,等价于传统数据库 database:
CREATE SPACE mylove (partition_num = 15, replica_factor = 3, vid_type = FIXED_STRING(256));//分区数推荐为节点数的5倍关系,副本数为基数,一般设置为3,vid如果为string类型,长度尽量够用就行,否则占用磁盘空间太多。
创建 Tag,等价于实体 Vertex:
CREATE TAG entity (name string NULL, version string NULL);
创建 Edge,等价于关系 Edge:
CREATE EDGE relation (name string NULL);
查询时,务必添加 LIMIT,否则容易查死库:
match (v) return v limit 100;
这里可以参考 2 份资料:
附上 NebulaSparkWriterExample 的示例代码:
.facebook.thrift.protocol.TCompactProtocol
.vesoft.nebula.connector.{
NebulaConnectionConfig,
WriteMode,
WriteNebulaEdgeConfig,
WriteNebulaVertexConfig
}
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.slf4j.LoggerFactory
object NebulaSparkWriter {
private val LOG = LoggerFactory.getLogger(this.getClass)
var ip = ""
def main(args: Array[String]): Unit = {
val part = args(0)
ip = args(1)
val sparkConf = new SparkConf
sparkConf
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array[Class[_]](classOf[TCompactProtocol]))
val spark = SparkSession
.builder()
.master("local")
.config(sparkConf)
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
if("1".equalsIgnoreCase(part)) writeVertex(spark)
if("2".equalsIgnoreCase(part)) writeEdge(spark)
spark.close()
}
def getNebulaConnectionConfig(): NebulaConnectionConfig = {
val config =
NebulaConnectionConfig
.builder()
.withMetaAddress(ip + ":9559")
.withGraphAddress(ip + ":9669")
.withTimeout(Integer.MAX_VALUE)
.withConenctionRetry(5)
.build()
config
}
def writeVertex(spark: SparkSession): Unit = {
LOG.info("start to write nebula vertices: 1 entity")
val df = spark.read.option("sep", " ").csv("/home/2022/project/origin_file/csv/tag/entity/").toDF("id", "name", "version")
val config = getNebulaConnectionConfig()
val nebulaWriteVertexConfig: WriteNebulaVertexConfig = WriteNebulaVertexConfig
.builder()
.withSpace("mywtt")
.withTag("entity")
.withVidField("id")
.withVidAsProp(false)
.withUser("root")
.withPasswd("nebula")
.withBatch(1800)
.build()
df.coalesce(1400).write.nebula(config, nebulaWriteVertexConfig).writeVertices()
}
def writeEdge(spark: SparkSession): Unit = {
LOG.info("start to write nebula edges: 2 entityRel")
val df = spark.read.option("sep", " ").csv("/home/2022/project/origin_file/csv/out/rel/relation/").toDF("src", "dst", "name")
val config = getNebulaConnectionConfig()
val nebulaWriteEdgeConfig: WriteNebulaEdgeConfig = WriteNebulaEdgeConfig
.builder()
.withSpace("mywtt")
.withEdge("relation")
.withSrcIdField("src")
.withDstIdField("dst")
.withSrcAsProperty(false)
.withDstAsProperty(false)
.withUser("root")
.withPasswd("nebula")
.withBatch(1800)
.build()
df.coalesce(1400).write.nebula(config, nebulaWriteEdgeConfig).writeEdges()
}
}
这里讲解一些函数项:
nohup spark-submit --master yarn --deploy-mode client --.xxx.nebula.connector.NebulaSparkWriter --conf spark.dynamicAllocation.enabled=false --conf spark.executor.memoryOverhead=10g --conf spark.blacklist.enabled=false --conf spark.default.parallelism=1000 --driver-memory 10G --executor-memory 12G --executor-cores 4 --num-executors 180 ./example-3.0-SNAPSHOT.jar > run-csv-nebula.log 2>&1 &
Total DISK READ : 26.61 K/s | Total DISK WRITE : 383.77 M/s
Actual DISK READ: 26.61 K/s | Actual DISK WRITE: 431.75 M/s
top - 16:03:01 up 8 days, 28 min, 1 user, load average: 6.16, 6.53, 4.58
Tasks: 205 total, 1 running, 204 sleeping, 0 stopped, 0 zombie
%Cpu(s): 28.3 us, 14.2 sy, 0.0 ni, 56.0 id, 0.6 wa, 0.0 hi, 0.4 si, 0.5 st
KiB Mem : 13186284+total, 1135004 free, 31321240 used, 99406592 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 99641296 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
27979 root 20 0 39.071g 0.026t 9936 S 564.6 20.8 83:22.03 nebula-storaged
27920 root 20 0 2187476 804036 7672 S 128.2 0.6 17:13.75 nebula-graphd
27875 root 20 0 6484644 1.990g 8588 S 58.5 1.6 14:14.22 nebula-metad
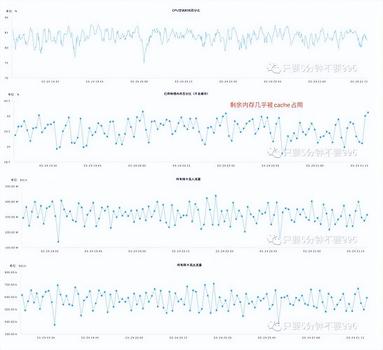
这里我修改了 nebula-storaged.conf 配置项:
# 一个批处理操作的默认保留字节
--rocksdb_batch_size=4096
# BlockBasedTable中使用的默认块缓存大小
# 单位为 MB. 服务器内存128G,一般设置为三分之一
--rocksdb_block_cache=44024
############## rocksdb Options ##############
--rocksdb_disable_wal=true
# rocksdb DBOptions在json中,每个option的名称和值都是一个字符串,如:“option_name”:“option_value”,逗号分隔
--rocksdb_db_options={"max_pactions":"3","max_background_jobs":"3"}
# rocksdb ColumnFamilyOptions在json中,每个option的名称和值都是字符串,如:“option_name”:“option_value”,逗号分隔
--rocksdb_column_family_options={"disable_pactions":"false","write_buffer_size":"67108864","max_write_buffer_number":"4","max_bytes_for_level_base":"268435456"}
# rocksdb BlockBasedTableOptions在json中,每个选项的名称和值都是字符串,如:“option_name”:“option_value”,逗号分隔
--rocksdb_block_based_table_options={"block_size":"8192"}
# 每个请求最大的处理器数量
--max_handlers_per_req=10
# 集群间心跳间隔时间
--heartbeat_interval_secs=10
--raft_rpc_timeout_ms=5000
--raft_heartbeat_interval_secs=10
--wal_ttl=14400
# 批量大小最大值
--max_batch_size=1800
# 参数配置减小内存应用
--enable_partitioned_index_filter=true
# 数据在最底层存储层间接做了过滤,生产环境防止遇到查到超级节点的困扰
--max_edge_returned_per_vertex=10000
ulimit -c unlimited
ulimit -n 130000
sysctl -w net.ipv4.tcp_slow_start_after_idle=0
sysctl -w net.core.somaxconn=2048
sysctl -w net.ipv4.tcp_max_syn_backlog=2048
sysctl -w net.core.netdev_max_backlog=3000
sysctl -w kernel.core_uses_pid=1
SUBMIT JOB STATS;
SHOW JOB ${ID}
SHOW STATS;
[root@node02 nebula]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 50G 2.2G 48G 5% /
/dev/sdb1 2.0T 283G 1.6T 16% /usr/local/nebula
tmpfs 13G 0 13G 0% /run/user/62056
MATCH (v:entity) WHERE v.entity.name == ’Lifespan’ RETURN v;
执行时间消耗 0.002558 (s)
MATCH (v1:entity)-[e:propertiesRel]->(v2:attribute) WHERE id(v1) == ’70da43c5e46f56c634547c7aded3639aa8a1565975303218e2a92af677a7ee3a’ RETURN v2 limit 100;
执行时间消耗 0.003571 (s)
MATCH p=(v1:entity)-[e:propertiesRel*1..2]->(v2) WHERE id(v1) == ’70da43c5e46f56c634547c7aded3639aa8a1565975303218e2a92af677a7ee3a’ RETURN p;
执行时间消耗 0.005143 (s)
FETCH PROP ON propertiesRel ’70da43c5e46f56c634547c7aded3639aa8a1565975303218e2a92af677a7ee3a’ -> ’0000002d2e88d7ba6659db83893dedf3b8678f3f80de4ffe3f8683694b63a256’ YIELD properties(edge);
执行时间消耗 0.001304 (s)
match p=(v:entity{name:"张三"})-[e:entityRel|propertiesRel*1]->(v2) return p;
执行时间消耗 0.02986 (s)
match p=(v:entity{name:"张三"})-[e:entityRel|propertiesRel*2]->(v2) return p;
执行时间消耗 执行时间消耗 0.07937 (s)
match p=(v:entity{name:"张三"})-[e:entityRel|propertiesRel*3]->(v2) return p;
执行时间消耗 0.269 (s)
match p=(v:entity{name:"张三"})-[e:entityRel|propertiesRel*4]->(v2) return p;
执行时间消耗 3.524859 (s)
match p=(v:entity{name:"张三"})-[e:entityRel|propertiesRel*1..2]->(v2) return p;
执行时间消耗 0.072367 (s)
match p=(v:entity{name:"张三"})-[e:entityRel|propertiesRel*1..3]->(v2) return p;
执行时间消耗 0.279011 (s)
match p=(v:entity{name:"张三"})-[e:entityRel|propertiesRel*1..4]->(v2) return p;
执行时间消耗 3.728018 (s)
FIND SHORTEST PATH WITH PROP FROM "70da43c5e46f56c634547c7aded3639aa8a1565975303218e2a92af677a7ee3a" TO "0000002d2e88d7ba6659db83893dedf3b8678f3f80de4ffe3f8683694b63a256" OVER * BIDIRECT YIELD path AS p;
执行时间消耗 0.003096 (s)
FIND ALL PATH FROM "70da43c5e46f56c634547c7aded3639aa8a1565975303218e2a92af677a7ee3a" TO "0000002d2e88d7ba6659db83893dedf3b8678f3f80de4ffe3f8683694b63a256" OVER * WHERE propertiesRel.name is not EMPTY or propertiesRel.name >=0 YIELD path AS p;
执行时间消耗 0.003656 (s)
Caused by: java.lang.NoSuchMethodError: com.mon.base.atch.createStarted()Lcom/mon/base/atch;
经排查发现依赖的一个模块使用 guava 版本 22.0,而 Spark 集群自带 14.0,导致冲突,而无法正常工作。运行在 Spark 集群上的任务,Spark 加载 guava 包优先级高于自己的包。
我们依赖的包使用到 guava 版本 22.0 中比较新的方法,而在 14.0 版本还没有这样的方法。在不能修改对方代码的前提下,有如下方案:
这里采用了第二种方式,利用 Maven 插件 shade(链接:https://maven.apache.org/plugins/maven-shade-plugin/ 1)重命名包解决问题。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<relocations>
<relocation>
<pattern&.mon</pattern>
<shadedPattern>my_mon</shadedPattern>
</relocation>
</relocations>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/maven/**</exclude>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
Blacklisting behavior can be configured via spark.blacklist.*.
spark.blacklist.enabled,默认值 false。如果这个参数这为 true,那么 Spark 将不再会往黑名单里面的执行器调度任务。黑名单算法可以由其他 spark.blacklist 配置选项进一步控制,详情参见下面的介绍。
欢迎到 Nebula 论坛与作者讨论交流:https://discuss.nebula-.cn
以上就是关于root后不能用gg修改器_不root能用gg修改器吗的全部内容,感谢大家的浏览观看,如果你喜欢本站的文章可以CTRL+D收藏哦。

详情gg修改器中文版,详情GG修改器中文版优秀的游戏外挂修改工具 大小:11.09MB9,204人安装 随着游戏市场的不断发展,越来越多的玩家开始寻求更多的游戏体验。然而,一些游戏的……
下载
gg修改器9.90中文版, gg修改器9.90中文版:革新游戏世界的神器 大小:6.13MB9,840人安装 随着游戏的日益普及,越来越多的玩家开始寻求一些辅助工具,以优化游戏体验,加快升……
下载
如何操作最新版本的gg修改器,如何操作最新版本的gg修改器 大小:8.30MB9,887人安装 GG修改器是一款优秀的游戏修改工具,它可以将一些游戏内部数据进行修改,从而让玩家……
下载
gg助手修改器下载中文,GG助手修改器下载中文,从此畅玩游戏更简单! 大小:10.69MB9,398人安装 作为一名游戏爱好者,我们都深知修改器对于游戏的重要性。碰到一些无法克服的难关或……
下载
gg修改器中文官网ios_gg修改器中文官网下载 大小:3.84MB10,699人安装 大家好,今天小编为大家分享关于gg修改器中文官网ios_gg修改器中文官网下载的内容,……
下载
最新版gg修改器怎么修改, 简介 大小:8.65MB9,665人安装 最新版gg修改器是一款非常强大的游戏辅助工具,它具有丰富的功能和易于使用的界面……
下载
gg游戏修改器怎么修改主宰,用GG游戏修改器修改主宰?这简直是太easy了! 大小:15.55MB9,941人安装 GG游戏修改器是广大游戏玩家最喜爱的游戏修改软件之一。它不仅能为玩家提供众多的游……
下载
gg修改器无root模式下_无root怎么使用gg修改器 大小:6.88MB10,583人安装 大家好,今天小编为大家分享关于gg修改器无root模式下_无root怎么使用gg修改器的内……
下载
gg修改器虚拟空间root_gg修改器虚拟空间游戏闪退 大小:19.12MB10,758人安装 大家好,今天小编为大家分享关于gg修改器虚拟空间root_gg修改器虚拟空间游戏闪退的……
下载
GG修改器怎么切换简体中文_gg修改器设置中文 大小:18.38MB10,789人安装 大家好,今天小编为大家分享关于GG修改器怎么切换简体中文_gg修改器设置中文的内容……
下载