GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于怎样获取gg修改器root_怎么下GG修改器的内容,赶快来一起来看看吧。
你好呀,我是可乐。
先前,我为大家分享过G1垃圾回收器的前置基础知识,不知道有没有小伙伴还记得呀?不知道的小伙伴可以看我先前的文章哦!
今天的我们来点硬核的吧,总结下有关G1收集器大概的知识点吧,一起来看下吧!
我们平时在学习一个新技术时,一定要保持着一颗怀疑和好奇的心。这是我们程序员要做到的一点。
这里我说下,jvm团队设计出G1收集器,就是为了取代CMS收集器的,虽然CMS收集器也还不错,但是,在很多场景下还是有诸多问题的,缺陷暴露无遗了。
首先,我们来看下官方对其定义是怎么样的。
The Garbage First or G1 garbage collector is available in Java 7 and is designed to be the long term replacement for the CMS collector. The G1 collector is a parallel, concurrent, and pacting low-pause garbage collector that has quite a different layout from the other garbage collectors described previously. However, detailed discussion is beyond the scope of this OBE.
默认大家英文水平和我一样,没啥太大的问题好吧,哈哈哈!
OK,大家是否看到我加粗的一段英文,这里翻译过来就是,G1收集器是CMS收集器的长期替代品。
整个翻译过来是:“Garbage First 或 G1 垃圾收集器在 Java 7 中可用,旨在成为 CMS 收集器的长期替代品。G1 收集器是一个并行、并发和增量压缩的低暂停垃圾收集器,它的布局与前面描述的其他垃圾收集器有很大不同。但是,详细讨论超出了本 OBE 的范围。”
好啦,我们用自己的话再说下G1吧!
G1收集器是一款在server端运行的垃圾收集器,专门针对于拥有多核处理器和大内存的机器,在JDK 7u4版本发行时被正式推出,在JDK9中更被指定为官方GC收集器。它满足高吞吐量的同时满足GC停顿的时间尽可能短。G1收集器专门针对以下应用场景设计。
G1 (Garbage First)从英文名就可以得知,G1 是以垃圾优先的。
G1 是一款并行、基于Region的内存布局的并发收集器,把堆内存分割成很多不相关的区域(region)(理论上是不连续的),使用不同的Region 来表示新生代(再细分)和老年代。
正是因为这种方式的侧重点在于回收垃圾最大量的区间(Region),所以我们给它取了个名字叫:Garbage First 垃圾优先。
G1 有计划地避免在整个Java堆中进行全区域的垃圾收集,它是跟踪各个Region 里面的垃圾堆积的价值大小, (回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region。
G1 收集器主要是针对配备多核CPU及大容量内存的机器,因此在服务器配置越好的情况下,G1的 垃圾回收就越表现得越好!
G1 能以高概率满足GC停顿时间的同时,还具备高吞吐量的性能特征,采用标记整理算法避免堆空间的冗余问题。在jdk9官方已经默认使用G1收集器了。
先说下优点吧!
停顿时间模型意思是能够支持指定在一个长度为M毫秒的时间片段内,消耗在垃圾收集器上的时间大概率不超过N毫秒这样的目标,这几乎已经是实时Java(RTSJ)的中软实时垃圾收集器特征了。
由于G1收集器采用分区模型,所以G1可以只选取部分区域进行内存回收,这样缩小了回收的范围,因此对于全局停顿情况的发生也能得到较好的控制。G1跟踪各个Region 里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region。
那么再看下缺点有哪些吧?
1、如果停顿时间过短的话,可能导致每次选出的回收集只占堆内存很小一部分,收集器收集的速度逐渐跟不上分配器的分配速度,进而导致垃圾慢慢堆积,最终造成堆空间占满,引发Full GC 反而降低性能。
2、G1 无论是在垃圾收集产生的内存占用还是程序运行时的额外执行负载都要比CMS要高。
3、小内存的情况下使用CMS收集器,大内存的情况下可以使用G1收集器。G1收集器6GB以上。
G1 收集器回收过程大致分为三个环节:
1、年轻代GC(Yong GC)
2、新生代和并发标记过程(Concurrent Marking)
3、混合回收(Mixed GC)
GC 线程先执行新生代GC的垃圾回收,接着是新生代GC并发标记过程,最后走混合回收,进行整个垃圾回收过程。
注意:一个region分区只能输入一个角色,可能是eden区、S区、老年代O区的其中一个。空白的地方表示未使用的分配的内存。还有个H区,其表示存放巨型对象,这一点需要格外注意下,因为我在图中没有标出。
后面我们将详细讲述,为什么G1 要设计出H区,其作用又是什么?
OK,今天我们一起来看下G1垃圾收集器啊,先带大家看一张图,认知下其分区原理吧。
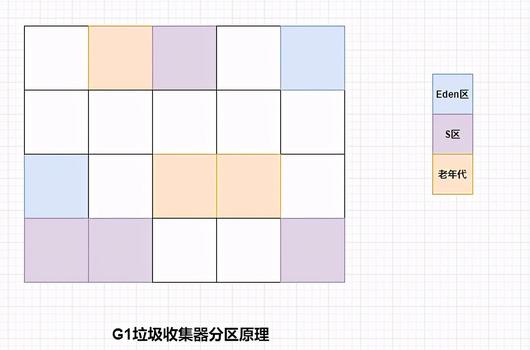
1、首先整堆大概被分为2000块,每块大小在1MB-32MB左右
2、图中的白色区域表示为没有分配的内存
3、逻辑上也会分为Eden区、Survior、Old区,但是大小不固定
这里,我们简单用语言描述下其原理,G1收集器,它将整个Java堆划分成2048个大小相同的独立Region块,每个Region块的大小根据堆空间的实际大小而定,整体被控制在1MB到32MB之间,且为2的N次幂,即1MB, 2MB, 4MB, 8MB, 1 6MB, 32MB。
可以通过一 XX:G1HeapRegionSize设定。所有的Region大小相同,且在JVM生命周期内不会被改变。
G1虽然还保留了新生代和老年代的概念,但新生代和老年代不再是物理隔离了,它们都是一部分Region (不需要连续)的集合,可以通过Region的动态分配方式实现逻辑上的连续。
是否还记得上面我提到的问题?G1收集器为什么要设计H区(存放巨型对象)?
我们想一下,这个H区,是不是用来专门存放大的对象?这样做有什么好处?这样的设计可以更好地进行垃圾回收吗?
不着急的,我们带着上面的疑问,一步一步探索下。
G1收集器的Region中有一块特殊的H区,专门用来存储大对象。G1认为只要大小超过了一个Region容量一半的对象即可判断为大对象,而对那些超过了整个Region容量的巨型对象,将会被存放到N个连续的H区中,特殊对待,G1多数行为都把H区当做为老年代的一部分来进行看待。
在先前的收集器中,如果一个大对象直接放入到老年代中,而触发老年代GC不是很频繁,万一该大对象不是非常频繁使用,那岂不是非常浪费堆内存。
为了解决这个棘手的问题,G1的H区就诞生了,你再试想,如果一个H区都装不了巨型对象的情况下,则会存放到N个连续的H区中。
那有同学思考比较快,就问了,那如果还没有足够的空间存储巨型对象咋办呢?这种情况,就有可能触发FullGC了。
G1收集器整个回收过程大致可以划分为以下四个步骤:
1、初始标记(Initial Marking):仅仅标记下GC Roots链上能直接关联到的对象,且修改TAMS的值,使下一阶段的用户线程并发运行时,能够正确地在可用的Region中分配对象。注意,该阶段是需要STW的,但耗时很短暂,而且是借用进行Minor GC时同步完成的,所以该阶段实际并没有多大的影响。
2、并发标记(Concurrent Marking):
从GC Root链上开始对整堆对象进行可达性分析,递归扫描整个堆里的对象图,找出要回收的对象,该阶段耗时较长的,但可与用户线程并发执行。当对象图扫描完成以后,还要重新处理SATB记录下在并发时有引用改动的对象。
3、最终标记(Final Markin):
对用户线程做另一个短暂的暂停,用于处理并发阶段结束后任遗留的最后少量的SATB记录。
4、筛选回收(Live Data Counting and Evacuation):
负责更新Region的统计数据,对各个Region区域的回收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划,可以自由选择任意多个Region构成回收集,然后把决定回收的那一部分Region的存活对象复制到空的Region中,最后清理掉整个旧的Region的全部空间。需要注意的是,这里的操作涉及到对象的移动,必须是暂停用户线程的,由多条收集器线程并行完成的。
如果还是觉得不是很清楚的同学,我在这里画了一张图,可以辅助参考下哦!
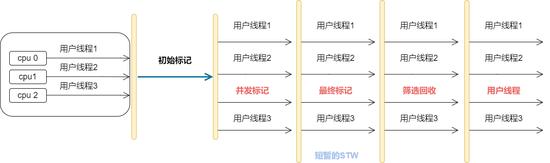
G1收集器回收过程
OK,我们一起来看下G1的一些“组件”吧!
写屏障(Store Barrier),是指在赋值操作的前后,加入一些处理,记录赋值的操作。
这里是否联想到Spring Aop的实现方式啊?
我觉得写屏障的原理和AOP原理差不多的,都是在其前后做一些特殊的处理。
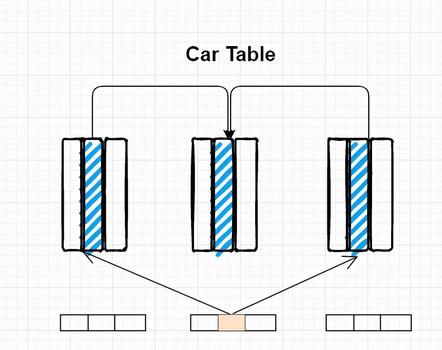
Rset即Remembered Set ,在一个region中可能会引入到其他的region,为了避免不需要的全局扫描,使用CarTable记录每个Region区域相互引用的关系。
CSet (Collect Set) 指每次GC暂停回收的一系列目标分区。在任意一次收集器中,CSet 所有分区都会被释放,内部存活的对象都会被转移到分配的空闲分区中。
因此无论是年轻代收集,还是混合收集,工作的机制都是一致的。年轻代收集CSet只容纳年轻代分区,而混合收集会通过启发式算法,在老年代候选回收分区中,筛选出回收收益最高的分区添加到CSet中。
候选老年代分区的CSet准入条件,可以通过活跃度阈值-XX:G1MixedGCLiveThresholdPercent(默认85%)进行设置,从而拦截那些回收开销巨大的对象;同时,每次混合收集可以包含候选老年代分区,可根据CSet对堆的总大小占比-XX:G1OldCSetRegionThresholdPercent(默认10%)设置数量上限。
当新生代eden区内存满的时候,G1年轻代收集器会采用并行多线程的方式清理堆内存垃圾,这时候会暂停所有用户的线程,让新生代存活的对象会拷贝到S区或者老年代中,和我们在以前所学习的新生代收集器原理基本相同。
在新生代进行垃圾回收时,进行GC Root初始化标记与CMS实现原理基本相同,老年代达到堆内存空间阈值时,会实现并发标记(不会STW),jvm配置参数如下:
-XX:InitiatingHeapOccupancyPercen=45%
在使用再次标记(修正的时候)的时候,G1中采用了比CMS更快的初始快照算法:snapshot一at一the一beginning (SATB)。
这里引入一个知识点,三色标记法
简单介绍下三色标记法吧。
白:未被标记的对象
灰:对象被标记了,但是它的field还没有被标记
黑:对象被标记了,且它的所有field也被标记完了
区别:
1、CMS收集器中,漏标使用的增量更新
2、G1收集器中,漏标采用的是快照搜索(SATB)算法
好啦,今天的文章内容就到这里啦,如果你觉得文章对你有帮助或有用的话,请不要忘了,给我点赞、收藏和转发哦!您的支持,将是我继续创作的巨大动力,感谢啦!
以上就是关于怎样获取gg修改器root_怎么下GG修改器的全部内容,感谢大家的浏览观看,如果你喜欢本站的文章可以CTRL+D收藏哦。

gg修改器修改中文内容,GG修改器助力中文内容创作的利器 大小:7.01MB10,135人安装 无论是从事网络写作还是游戏玩家,都深知一个事实,那就是修改器对于中文内容创作来……
下载
外国gg游戏修改器,掌握外国GG游戏的利器外国GG游戏修改器 大小:5.47MB9,779人安装 对于外国GG游戏爱好者来说,找到一款适当的游戏修改器是非常重要的,可以帮助你获得……
下载
免root用gg修改器_免root怎么使用GG修改器 大小:18.14MB10,816人安装 大家好,今天小编为大家分享关于免root用gg修改器_免root怎么使用GG修改器的内容,……
下载
gg修改器教程中文版,GG修改器教程中文版:给游戏掌控权 大小:7.28MB9,500人安装 对于喜欢玩游戏的人来说,游戏中总是有一些让人不满意的地方,比如游戏画面不清晰、……
下载
最新版gg修改器8.78,最新版gg修改器8.78:一款神奇的游戏辅助工具 大小:3.55MB9,718人安装 最新版gg修改器8.78是近年来备受欢迎的一款游戏辅助工具,其强大的功能和稳定的性能……
下载
无需root版的gg修改器,无需Root版的GG修改器,助你玩转游戏 大小:15.65MB9,353人安装 对于热爱游戏的玩家来说,游戏内的道具和金币永远都不够。而一些游戏的难度也让人束……
下载
gg修改器怎么免root防闪,什么是gg修改器 大小:19.19MB9,227人安装 gg修改器是一款可以修改手机游戏的工具,通过该工具可以修改游戏的一些数据,比如金……
下载
gg修改器获取不了root,GG修改器,给你不一样的游戏体验 大小:12.90MB9,701人安装 你是否曾为游戏中的繁琐操作而烦恼?是否曾为游戏中的流程繁琐而感到无聊?GG修改器……
下载
gg修改器下载无root,为什么gg修改器下载无root非常适合玩家? 大小:16.75MB9,749人安装 如果你是玩家,你可能知道修改器的重要性。但是,一些修改器需要你的设备root才能使……
下载
最新版的gg修改器在哪里,最新版的GG修改器在哪里? 大小:15.98MB9,450人安装 想必很多游戏玩家都知道GG修改器,在游戏中使用GG修改器可以获得很多优势,让游戏变……
下载