GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg游戏修改器如何加速游戏_gg修改器怎么加速游戏时间的内容,赶快来一起来看看吧。

Machine learning ( ML )越来越多地用于各个行业。欺诈检测、需求感知和信贷承销是特定用例的几个示例。
这些机器学习模型做出影响日常生活的决策。因此,模型预测必须公平、无偏见、无歧视。在透明度和信任至关重要的高风险应用程序中,准确的预测至关重要。
确保 AI 公平性的一种方法是分析从机器学习模型获得的预测。这暴露了差异,并提供了采取纠正措施诊断和纠正根本原因的机会。
Explainable AI (XAI) 是一个负责任的人工智能领域,致力于研究解释机器学习模型如何进行预测的技术。这些解释是人类可以理解的,使所有利益相关者能够理解模型的输出并做出必要的决策。SHAP 是一种在工业中广泛使用的评估和解释模型预测的技术。
这篇文章解释了如何训练 XGBoost 模型,如何使用 CPU 和 GPU 在 Python 中实现 SHAP 技术,最后比较两者的结果。在文章结束时,您应该能够回答以下问题:
可解释性与可译性
在人工智能和机器学习的背景下,区分可解释性和可译性很有帮助。这些术语具有不同的含义,但经常互换使用。
在开创性的论文Psychological Foundations of Explainability and Interpretability in Artificial Intelligence 中,美国国家标准与技术研究院( NIST )的研究人员提出了以下解释性和可解释性的定义:
可解释性
可解释性是一种低级、详细的心理表征,旨在描述一些复杂的过程。解释描述了一些模型机制或输出是如何产生的。
可译性
可解释性是一种高层次、有意义的心理表征,它将刺激情境化,并利用人类背景知识。可解释的模型应该为用户提供数据点或模型输出在上下文中的含义的描述。
此外,根据 Explanation in Artificial Intelligence: Insights from the Social Sciences , 可解释性是指人类能够理解和信任 ML 模型预测的程度。
解释方法概述
特定于型号
后 hoc
这篇文章主要关注 SHAP ,一种解释模型预测的事后技术。
使用 SHAP 技术解释模型
SHAP 是 SHapley Additive Explanations 的缩写。它是最常用的事后解释技术之一。SHAP 利用合作博弈理论 的概念分解预测,以衡量每个特征对预测的影响。
Shapley 值定义为特征值在所有可能的特征联盟中的平均边际贡献。沙普利价值观是一种起源于经济学和博弈论的技术,它根据参与者对总收益的贡献,为联盟中的参与者分配公平的报酬。将其转化为机器学习场景意味着根据特征对模型预测的贡献来为模型中的特征分配重要性。
SHAP unifies 使用 Shapley 值生成准确的局部特征重要性值的几种方法,然后可以对这些值进行聚合以获得全局解释。SHAP 值解释了具有特定值的给定特征对模型预测的影响,与我们在该特征采用某个基线值时所做的预测相比。基线值是模型在没有任何特征值信息的情况下预测的值。
SHAP 是用于计算特征属性的最广泛的事后解释技术之一。它不依赖于模型,可以作为一种局部和全局特征属性技术使用,并有可靠的经济学理论支持。此外,基于树的模型的 SHAP 变体大大减少了计算时间,从而帮助用户快速从模型中获得见解。
以下部分提供了如何使用 SHAP 技术的示例。
步骤 1 :训练 XGBoost 模型并计算 SHAP 值
安装
pip install shap
or
conda install -c conda-forge shap
SHAP 本身也受到流行算法(如 LightGBM 和 XGBoost )以及几个 R 包的支持。
设置环境
import numpy as np
import pandas as pd
# Visualization Libraries
import matplotlib.pyplot as plt
%matplotlib inline
## Machine learning packages
from sklearn.model_selection import train_test_split
import xgboost as xgb
## Model Interpretation package
import shap
shap.initjs()
# Ensuring Reproducibility
SEED = 12345
# Ignoring the warnings
import warnings
warnings.filterwarnings(action = "ignore")
数据集
shap 库附带了一些常用的数据集,包括下面使用的成人收入数据集的预处理版本。
图 1.从 shap 库访问数据集
X,y = shap.datasets.adult()
X_view,y_view = shap.datasets.adult(display=True)
X_view.head()
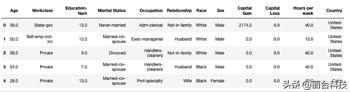
表 1.显示数据集前五行的 DataFrame
如上所示,数据集由各种预测变量(如年龄、工作级别和教育程度)以及一个目标变量组成。如果一个人年收入> 5 万美元,目标变量为 True;如果年收入为≤$ 50 公里。在确保数据集经过预处理和清理后,继续进行模型训练。
训练 XGBoost 模型
XGBoost 在表格数据集方面表现出色,在机器学习社区中非常流行。首先,将数据集拆分为训练集和验证集。
# create a train/test split
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=7)
接下来,根据 5K 助推回合的训练数据训练 XGBoost 模型。
# read in the split dataset into an optimized data structure called Dmatrix required by XGBoost
dtrain = xgb.DMatrix(X_train, label=y_train)
dvalid = xgb.DMatrix(X_valid, label=y_valid)
%%time
# Feed the model the global bias
base_score = np.mean(y_train)
#Set hyperparameters for model training
params = {
’objective’: ’binary:logistic’,
’eval_metric’: ’logloss’,
’eta’: 0.01,
’subsample’: 0.5,
’colsample_bytree’: 0.8,
’max_depth’: 5,
’base_score’: base_score,
’seed’: SEED
}
# Train using early stopping on the validation dataset.
watchlist = [(dtrain, ’X_train’), (dvalid, ’X_test’)]
model = xgb.train(params,
dtrain,
num_boost_round=5000,
evals=watchlist,
early_stopping_rounds=20,
verbose_eval=100)
===============================================================
Wall time: 14.3 s
在 Apple M1 8 核 CPU 上执行训练需要 14.3 秒,并启用了提前停止功能。
有关 XGBoost 模块内可配置参数的更多信息,请参阅 XGBoost Parameters 。
计算 SHAP 值
根据算法的性质, SHAP 有许多不同的风格。最流行的似乎是 KernelSHAP 、 DeepSHAP 和 TreeSHAP 。虽然 KernelSHAP 与模型无关,但 TreeSHAP 仅适用于基于树的模型(包括我们刚刚培训的 XGBoost 模型)。使用 shap 库中的 TreeExplainer 类解释包含超过 30K 个样本和超过 1000 棵树的整个数据集。
%%time
explainer = shap.TreeExplainer(model=model)
shap_values = explainer.shap_values(X)
================================================================
CPU times: user 4min 12s, sys: 116 ms, total: 4min 12s
Wall time: 1min 4s
使用上述相同的硬件,在 1.4 分钟内计算出 SHAP 值。请注意将它们与下一秒获得的值进行比较的时间。既然已经确定了 SHAP 值,下一步就是解释。为了理解这些值, shap 提供了几种不同类型的可视化,如力图、汇总图、决策图等,每种图都突出了模型的特定方面。下面包括两个图。
SHAP 力图
力图用于解释数据集中的单个实例。为训练集中的第一行生成力图,并查看不同特征如何影响预测。首先打印此数据实例的地面真相标签和模型预测。
classes = {0 : ’False’, 1: ’True’}
# ground truth label
y[0]
=========================
False
# Model Prediction
y_pred = [round(value) for value in model.predict(dvalid)]
classes[y_pred[0]]
==========================================================
False
此人的基本真相标签为 False ;也就是说,这个人赚了≤$每年 5 万。该模型也预测了同样的情况。图 2 显示了同一个人的力量图,深入了解了各种特征是如何对模型的预测做出贡献的。
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[0,:],X.iloc[0,:])

图 2.SHAP 力图
此处的 base _ value 为– 1.143 ,而所选样本的目标值为– 3.89 。所有大于基本值的值都有收益≥$ 50K ,反之亦然。对于所选的样本,图 2 中显示为红色的特征将预测推到基础值,而蓝色的特征则将预测推离基础值。因此,可以推断,拥有 2174 的资本收益和 0 的关系状态会对该模型对该特定个人收入> 5 万美元的预测产生负面影响。
SHAP 汇总图
SHAP 汇总图概述了哪些功能对模型更重要。这可以通过为数据集中的每个样本绘制每个特征的 SHAP 值来实现。图 3 描述了一个汇总图,其中图中的每个点对应于数据集中的一行。
shap.summary_plot(shap_values_gpu, X_test)
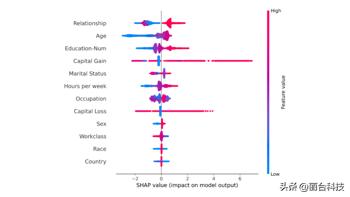
图 3.SHAP 汇总图
图 3 中的每个点表示原始数据集中的一行。对于每个点:
从总结图可以推断,与其他特征相比,“关系状态”和“年龄”对预测一个人是否会获得更高收入具有更高的总模型影响。
步骤 2 : GPU 加速 SHAP
然而, TreeSHAP 算法的复杂性导致难以映射到硬件加速器。这导致了 GPUTreeShap 的开发,这是适合与 GPU 一起使用的 TreeSHAP 算法的变体。现在可以在计算 SHAP 值时利用 GPU 硬件,从而加快整个模型解释过程。
GPUTreeShap enables massively exact calculation of the shape values for tree-based algorithms。图 4 显示了 GPUTreeSHAP 如何提供在 CPU 上使用带有 GPU 的 SHAP 时获得的增益估计。根据 GPUTreeShap: Massively Parallel Exact Calculation of SHAP Scores for Tree Ensembles ,“通过单个 NVIDIA Tesla V100-32 GPU ,在两个 20 核 Xeon E5-2698 v4 2.2 GHz CPU 上执行的最先进的多核 CPU 实现上,我们实现了 SHAP 值最高 19 倍的加速, SHAP 交互值最高 340 倍的加速。我们还使用八个 V100 GPU 进行了多 GPU 计算实验,显示每秒 1.2M 行的吞吐量–基于 CPU 的等效性能估计需要 6850 CPU 个内核。”
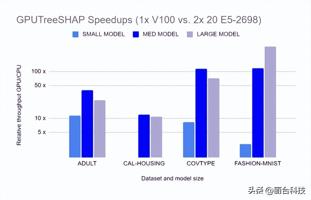
图 4.使用 GPU 的 SHAP 加速
安装
GPUTreeShap 已与 Python shap package 集成。访问 GPUTreeShap 的另一种方法是安装 RAPIDS 数据科学框架。这确保了可以访问 GPUTreeShap 和许多不同的库,以便完全在 GPU 中执行端到端的数据科学管道。
RAPIDS 也有 integrated with XGBoost (从 0.14 开始)。事实上, XGBoost 是在最终成为 RAPIDS 生态系统的情况下加速的第一个流行的 ML 工具包。图 5 突出显示了 GPU 上的 XGBoost 加速,将单个 V100 GPU 与双 20 核 CPU 进行了比较。
开发人员可以利用 RAPIDS 对 XGBoost 和 SHAP 值的 GPU 加速。默认的开源 XGBoost 包已经包含支持 GPU CUDA 的 GPU 支持。
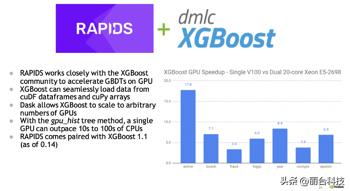
图 5. RAPIDS 与 XGBoost 社区密切合作,加速 GPU 上的 GBDT
使用 GPU 加速训练 XGBoost 车型
上一节演示了谁在成人收入数据集上训练 XGBoost 模型。本节重复使用 GPU 加速启用的相同过程。这需要更改名为 tree_method 的单个参数的值,并大幅减少计算时间。
将 tree_method 参数指定为 gpu_hist,保持所有其他参数不变。
%%time
# Feed the model the global bias
base_score = np.mean(y_train)
#Set hyperparameters for model training
params = {
’objective’: ’binary:logistic’,
’eval_metric’: ’logloss’,
’eta’: 0.01,
’subsample’: 0.5,
’colsample_bytree’: 0.8,
’max_depth’: 5,
’base_score’: base_score,
’tree_method’: "gpu_hist", # GPU accelerated training
’seed’: SEED
}
# Train using early stopping on the validation dataset.
watchlist = [(dtrain, ’X_train’), (dvalid, ’X_test’)]
model_gpu = xgb.train(params,
dtrain,
num_boost_round=5000,
evals=watchlist,
early_stopping_rounds=10,
verbose_eval=100)
=============================================================
CPU times: user 2.43 s, sys: 484 ms, total: 2.91 s
Wall time: 3.27 s
使用单个 Tesla T4 GPU (通过 Google Colab 提供)训练 XGBoost 车型有助于将训练时间从 14.3 秒减少到 3.27 秒。减少计算时间是有益的,因为训练机器学习模型,特别是在大型数据集上,既有挑战性,又很昂贵。
使用 GPU 计算 SHAP 值
当选择 GPU 预测器时, XGBoost 将 GPUTreeShap 用作计算形状值的后端。
%%time
model_gpu.set_param({"predictor": "gpu_predictor"})
explainer_gpu = shap.TreeExplainer(model=model_gpu)
shap_values_gpu = explainer_gpu.shap_values(X)
==========================================================
CPU times: user 1.34 s, sys: 252 ms, total: 1.59 s
Wall time: 1.56 s
使用 GPU ,计算 Shapley 值的计算时间从 1.4 分钟减少到 1.56 秒,大大减少了计算时间。当数据集涉及数百万个数据点时,这种收益将更加显著,这在许多行业都很常见。
总结
SHAP 等技术可以使机器学习系统更加可靠。如果一个模型可以被忠实地解释,那么可以对其进行分析,以确定它是否适合部署。这是向灌输对任何技术的信任迈出的重要一步。使用 GPU 加速,可以更快地计算 SHAP 值,从而更快地了解预测模型。
然而, SHAP 并不是万能的,它有自己的局限性。对 SHAP 的主要批评是它可能被误解。SHAP 基本上有助于回答为什么特定观测值接收到预测而不是基线值的问题。该基线值由背景数据集的选择决定,如果参考数据集发生变化,则可以提供对比结果。
因此,根据背景数据集的选择,相同的观察可能会导致不同的 SHAP 值。因此,重要的是要仔细、适当地 选择背景数据集 记住它们的使用背景。理解机器学习中与可解释性技术相关的假设和权衡非常重要。
要查看本文中使用的代码,请访问 GitHub 上的 parulnith/Data-Science-Articles 。
*本文转自 NVIDIA英伟达
以上就是关于gg游戏修改器如何加速游戏_gg修改器怎么加速游戏时间的全部内容,希望对大家有帮助。
阴阳师gg修改器最新改御魂,阴阳师gg修改器最新改御魂,是你不可或缺的游戏工具 大小:10.86MB9,691人安装 阴阳师这个游戏自上线以来,一直备受玩家的喜爱。但是御魂的升级过程实在是太过于漫……
下载
最新不掉gg修改器,最新不掉gg修改器:成为游戏高手的利器 大小:8.91MB9,545人安装 对于游戏爱好者来说,使用修改器成为游戏中的高手是一件非常令人兴奋的事情。最新的……
下载
gg修改器最新版73.1,了解GG修改器最新版73./h3> 大小:5.28MB9,319人安装 如果您是一位游戏玩家,您一定希望能够在游戏中享受更好的体验,那么GG修改器的最新……
下载
GG修改器无广告版,gg修改器无广告破解版 大小:11.51MB10,969人安装 语言:简体中文 环境:Android All GameGuardian游戏修改器是一款可以修改游戏的辅……
下载
如何在gg修改器里面添加游戏,使用GG修改器添加游戏:一步到位 大小:14.35MB9,371人安装 GG修改器是目前使用最广泛的游戏修改软件之一,它不仅可以修改游戏内的各种参数,还……
下载
gg修改器ios中文版下载,GG修改器iOS中文版:让你的游戏体验更加流畅 大小:9.72MB9,759人安装 如果你是一名游戏爱好者,那么你一定知道游戏中遇到的各种困难和挑战。有时候,我们……
下载
gg修改器框架下载最新,gg修改器框架下载最新为游戏玩家带来无限快乐 大小:3.89MB9,926人安装 伴随着电子游戏产业在全球范围内的迅速发展和普及,越来越多的游戏玩家开始寻找更好……
下载
gg游戏修改器root教程,赞美GG游戏修改器root教程 大小:6.64MB9,153人安装 GG游戏修改器root教程可能是现在最受欢迎的游戏修改工具。无论是想要获取更多游戏资……
下载
gg游戏修改器中文版正版下载_GG游戏修改器最新版 大小:9.59MB10,632人安装 大家好,今天小编为大家分享关于gg游戏修改器中文版正版下载_GG游戏修改器最新版的……
下载
gg修改器最新版中文_gg修改器最新版中文版下载 大小:7.38MB10,684人安装 大家好,今天小编为大家分享关于gg修改器最新版中文_gg修改器最新版中文版下载的内……
下载