GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器运行的游戏没反应_gg修改器运行的游戏没反应了的内容,赶快来一起来看看吧。

注意,get_user_pages 函数族不仅对管道有用——实际上它在许多驱动程序中都是核心。一个典型的用法与我们提及的内核旁路有关:网卡驱动程序可能会使用它将某些用户内存区域转换为物理页,然后将物理页位置传递给网卡,并让网卡直接与该内存区域交互,而无需内核参与。

大体积页面
到目前为止,我们所呈现的页大小始终相同——在 x86-64 架构上为 4KiB。但许多 CPU 架构,包括 x86-64,都包含更大的页面尺寸。x86-64 的情况下,我们不仅有 4KiB 的页(“标准”大小),还有 2MiB 甚至 1GiB 的页(“巨大”页)。在本文的剩余部分中,我们只讨论2MiB的大页,因为 1GiB 的页相当少见,对于我们的任务来说纯属浪费。
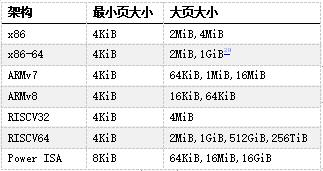
当今常用架构中的页大小,来自维基百科
大页的主要优势在于管理成本更低,因为覆盖相同内存量所需的页更少。此外其他操作的成本也更低,例如将虚拟地址解析为物理地址,因为所需要的页表少了一级:以一个 21 位的偏移量代替页中原来的12位偏移量,从而少一级页表。
这减轻了处理此转换的 CPU 部分的压力,因而在许多情况下提高了性能。但是在我们的例子中,压力不在于遍历页表的硬件,而在内核中运行的软件。
在 Linux 上,我们可以通过多种方式分配 2MiB 大页,例如分配与 2MiB 对齐的内存,然后使用 madvise 告诉内核为提供的缓冲区使用大页:
void* buf = aligned_alloc(1 << 21, size);madvise(buf, size, MADV_HUGEPAGE)
切换到大页又给我们的程序带来了约 50% 的性能提升:
% ./write --write_with_vmsplice --huge_page | ./read --read_with_splice51.0GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
然而,提升的原因并不完全显而易见。我们可能会天真地认为,通过使用大页, struct page 将只引用 2MiB 页,而不是 4KiB 页面。
遗憾的是,情况并非如此:内核代码假定 struct page 引用当前架构的“标准”大小的页。这种实现作用于大页(通常Linux称之为“复合页面”)的方式是,“头” struct page 包含关于背后物理页的实际信息,而连续的“尾”页仅包含指向头页的指针。
因此为了表示 2MiB 的大页,将有1个“头”struct page,最多 511 个“尾”struct pages。或者对于我们的 128KiB 缓冲区来说,有 31个尾 struct pages:
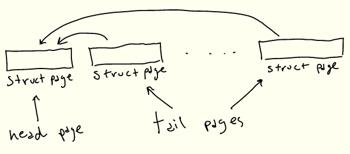
即使我们需要所有这些 struct pages,最后生成它的代码也会大大加快。找到第一个条目后,可以在一个简单的循环中生成后面的 struct pages,而不是多次遍历页表。这样就提高了性能!

Busy looping
我们很快就要完成了,我保证!再看一下 perf 的输出:
- 46.91% 0.38% write libc-2.33.so [.] vmsplice - 46.84% vmsplice - 43.15% entry_SYSCALL_64_after_hwframe - do_syscall_64 - 41.80% __do_sys_vmsplice + 14.90% wait_for_space + 8.27% __wake_mon_lock 4.40% add_to_pipe + 4.24% iov_iter_get_pages + 3.92% __mutex_lock.constprop.0 1.81% iov_iter_advance + 0.55% import_iovec + 0.76% syscall_exit_to_user_mode 1.54% syscall_return_via_sysret 1.49% __entry_text_start
现在大量时间花费在等待管道可写(wait_for_space),以及唤醒等待管道填充内容的读程序(__wake_mon_lock)。
为了避免这些同步成本,如果管道无法写入,我们可以让 vmsplice 返回,并执行忙循环直到写入为止——在用 splice 读取时做同样的处理:
...// SPLICE_F_NONBLOCK will cause `vmsplice` to return immediately// if we can’t write to the pipe, returning EAGAINssize_t ret = vmsplice(STDOUT_FILENO, &bufvec, 1, SPLICE_F_NONBLOCK);if (ret < 0 && errno == EAGAIN) { continue; // busy loop if not ready to write}...
通过忙循环,我们的性能又提高了25%:
% ./write --write_with_vmsplice --huge_page --busy_loop | ./read --read_with_splice --busy_loop62.5GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)

总结
通过查看 perf 输出和 Linux 源码,我们系统地提高了程序性能。在高性能编程方面,管道和拼接并不是真正的热门话题,而我们这里所涉及的主题是:零拷贝操作、环形缓冲区、分页与虚拟内存、同步开销。
尽管我省略了一些细节和有趣的话题,但这篇博文还是已经失控而变得太长了:
在实际代码中,缓冲区是分开分配的,通过将它们放置在不同的页表条目中来减少页表争用(FizzBuzz程序也是这样做的)。
记住,当使用 get_user_pages 获取页表条目时,其 refcount 增加,而 put_page 减少。如果我们为两个缓冲区使用两个页表条目,而不是为两个缓冲器共用一个页表条目的话,那么在修改 refcount 时争用更少。
通过用taskset将./write和./read进程绑定到两个核来运行测试。
资料库中的代码包含了我试过的许多其他选项,但由于这些选项无关紧要或不够有趣,所以最终没有讨论。
资料库中还包含get_user_pages_fast 的一个综合基准测试,可用来精确测量在用或不用大页的情况下运行的速度慢多少。
一般来说,拼接是一个有点可疑/危险的概念,它继续困扰着内核开发人员。
请让我知道本文是否有用、有趣或不一定!

致谢
非常感谢 Alexandru Scvorţov、Max Staudt、Alex Appetiti、Alex Sayers、Stephen Lavelle、Peter Cawley和Niklas Hambüchen审阅了本文的草稿。Max Staudt 还帮助我理解了 get_user_page 的一些微妙之处。
1. 这将在风格上类似于我的atan2f性能调研(https://mazzo.li/posts/vectorized-atan2.html),尽管所讨论的程序仅用于学习。此外,我们将在不同级别上优化代码。调优 atan2f 是在汇编语言输出指导下进行的微优化,调优管道程序则涉及查看 perf 事件,并减少各种内核开销。
2. 本测试在英特尔 Skylake i7-8550U CPU 和 Linux 5.17 上运行。你的环境可能会有所不同,因为在过去几年中,影响本文所述程序的 Linux 内部结构一直在不断变化,并且在未来版本中可能还会调整。
3. “FizzBuzz”据称是一个常见的编码面试问题,虽然我个人从来没有被问到过该问题,但我有确实发生过的可靠证据。
4. 尽管我们固定了缓冲区大小,但即便我们使用不同的缓冲区大小,考虑到其他瓶颈的影响,(吞吐量)数字实际也并不会有很大差异。
5. 关于有趣的细节,可随时参考资料库。一般来说,我不会在这里逐字复制代码,因为细节并不重要。相反,我将贴出更新的代码片段。
6. 注意,这里我们分析了一个包括管道读取和写入的shell调用——默认情况下,perf record跟踪所有子进程。
7. 分析该程序时,我注意到 perf 的输出被来自“Pressure Stall Information”基础架构(PSI)的信息所污染。因此这些数字取自一个禁用PSI后编译的内核。这可以通过在内核构建配置中设置 CONFIG_PSI=n 来实现。在NixOS 中:
boot.kernelPatches = [{ name = "disable-psi"; patch = ; extraConfig = ’’ PSI n ’’;}];
此外,为了让 perf 能正确显示在系统调用中花费的时间,必须有内核调试符号。如何安装符号因发行版而异。在最新的 NixOS 版本中,默认情况下会安装它们。
8. 假如你运行了 perf record -g,可以在 perf report 中用 + 展开调用图。
9. 被称为 tmp_page 的单一“备用页”实际上由 pipe_read 保留,并由pipe_write 重用。然而由于这里始终只是一个页面,我无法利用它来实现更高的性能,因为在调用 pipe_write 和 pipe_ read 时,页面重用会被固定开销所抵消。
10. 从技术上讲,vmsplice 还支持在另一个方向上传输数据,尽管用处不大。如手册页所述:
vmsplice实际上只支持从用户内存到管道的真正拼接。反方向上,它实际上只是将数据复制到用户空间。
11. Travis Downs 指出,该方案可能仍然不安全,因为页面可能会被进一步拼接,从而延长其生命期。这个问题也出现在最初的 FizzBuzz 帖子中。事实上,我并不完全清楚不带 SPLICE_F_GIFT 的 vmsplice 是否真的不安全——vmsplic 的手册页说明它是安全的。然而,在这种情况下,绝对需要特别小心,以实现零拷贝管道,同时保持安全。在测试程序中,读取端将管道拼接到/dev/ 中,因此可能内核知道可以在不复制的情况下拼接页面,但我尚未验证这是否是实际发生的情况。
12. 这里我们呈现了一个简化模型,其中物理内存是一个简单的平面线性序列。现实情况复杂一些,但简单模型已能说明问题。
13. 可以通过读取 /proc/self/pagemap 来检查分配给当前进程的虚拟页面所对应的物理地址,并将“页面帧号”乘以页面大小。
14. 从 Ice Lake 开始,英特尔将页表扩展为5级,从而将最大可寻址内存从256TiB 增加到 128PiB。但此功能必须显式开启,因为有些程序依赖于指针的高 16 位不被使用。
15. 页表中的地址必须是物理地址,否则我们会陷入死循环。
16. 注意,高 16 位未使用:这意味着我们每个进程最多可以处理 248 − 1 字节,或 256TiB 的物理内存。
17. struct page 可能指向尚未分配的物理页,这些物理页还没有物理地址和其他与页相关的抽象。它们被视为对物理页面的完全抽象的引用,但不一定是对已分配的物理页面的引用。这一微妙观点将在后面的旁注中予以说明。
18. 实际上,管道代码总是在 nr_pages = 16 的情况下调用 get_user_pages_fast,必要时进行循环,这可能是为了使用一个小的静态缓冲区。但这是一个实现细节,拼接页面的总数仍将是32。
19. 以下部分是本文不需要理解的微妙之处!
如果页表不包含我们要查找的条目,get_user_pages_fast 仍然需要返回一个 struct page。最明显的方法是创建正确的页表条目,然后返回相应的 struct page。
然而,get_user_pages_fast 仅在被要求获取 struct page 以写入其中时才会这样做。否则它不会更新页表,而是返回一个 struct page,给我们一个尚未分配的物理页的引用。这正是 vmsplice 的情况,因为我们只需要生成一个 struct page 来填充管道,而不需要实际写入任何内存。
换句话说,页面分配会被延迟,直到我们实际需要时。这节省了分配物理页的时间,但如果页面从未通过其他方式填充错误,则会导致重复调用 get_user_pages_fast 的慢路径。
因此,如果我们之前不进行 memset,就不会“手动”将错误页放入页表中,结果是不仅在第一次调用 get_user_pages_fast 时会陷入慢路径,而且所有后续调用都会出现慢路径,从而导致明显地减速(25GiB/s而不是30GiB/s):
% ./write --write_with_vmsplice --dont_touch_pages | ./read --read_with_splice25.0GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
此外,在使用大页时,这种行为不会表现出来:在这种情况下,get_user_pages_fast 在传入一系列虚拟内存时,大页支持将正确地填充错误页。
如果这一切都很混乱,不要担心,get_user_page 和 friends 似乎是内核中非常棘手的一角,即使对于内核开发人员也是如此。
20. 仅当 CPU 具有 PDPE1GB 标志时。
21. 例如,CPU包含专用硬件来缓存部分页表,即“转换后备缓冲区”(translation lookaside buffer,TLB)。TLB 在每次上下文切换(每次更改 CR3 的内容)时被刷新。大页可以显著减少 TLB 未命中,因为 2MiB 页的单个条目覆盖的内存是 4KiB 页面的 512 倍。
22. 如果你在想“太烂了!”正在进行各种努力来简化和/或优化这种情况。最近的内核(从5.17开始)包含了一种新的类型,struct folio,用于显式标识头页。这减少了运行时检查 struct page 是头页还是尾页的需要,从而提高了性能。其他努力的目标是彻底移除额外的 struct pages,尽管我不知道怎么做的。
以上就是关于gg修改器运行的游戏没反应_gg修改器运行的游戏没反应了的全部内容,希望对大家有帮助。
GG修改器最新版2022,gg修改器最新版下载2022 大小:6.93MB13,254人安装 GG修改器最新版2022能够让玩家感受瞬间秒杀全场的畅爽操作,该软件可以修改游戏中的……
下载
gg游戏助手修改器中文,gg游戏助手修改器中文游戏修改利器 大小:11.72MB11,512人安装 各位游戏玩家们,你们是否曾经遭遇过游戏难度略有些高,无法通过游戏的情况?又或者……
下载
gg修改器下载中文最新版_gg修改器全版本下载 大小:19.17MB12,897人安装 大家好,今天小编为大家分享关于gg修改器下载中文最新版_gg修改器全版本下载的内容……
下载
gg修改器手机要不要root,使用GG修改器手机,让你摆脱限制 大小:18.43MB12,074人安装 在手机游戏中,我们常常会遇到各种限制。例如,游戏内购买的虚拟物品需要花费大量金……
下载
平行空间使用gg游戏修改器,平行空间使用gg游戏修改器,极致游戏体验 大小:8.14MB11,531人安装 现今的游戏市场,各种游戏类型琳琅满目,但通过平行空间使用gg游戏修改器,可以为你……
下载
gg修改器2021最新中文版下载,gg修改器2021版下载安装 大小:6.09MB13,255人安装 做一个坚强的女子,独立自主,坚韧勇敢。面对困境,或许害怕,或许失败,但绝不逃避……
下载
gg修改器免root无广告版,为什么选择使用gg修改器免root无广告版? 大小:14.73MB11,341人安装 随着移动互联网和智能手机的普及,玩家们可以轻松地在手机上玩游戏。然而,一些游戏……
下载
gg修改器最新版本89.1,介绍GG修改器最新版本89./h3> 大小:15.69MB11,781人安装 GG修改器是一款非常优秀的游戏辅助工具,可以让玩家在游戏中获得更多的乐趣。最新版……
下载
gg游戏修改器怎么用航海王,掌握GG游戏修改器,航海王游戏更上一层楼! 大小:12.64MB11,352人安装 GG游戏修改器可谓是游戏玩家的神器,其强大的功能在玩家圈内声名远扬。对于喜欢航海……
下载
gg修改器中文版8.8,GG修改器中文版8.8:异常好用的游戏修改神器 大小:3.70MB11,769人安装 游戏是很多人澎湃的心跳,可是有时候游戏过程中却会遇到某些难以克服的问题,像是游……
下载