GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器的游戏代码_gg修改器游戏版的内容,赶快来一起来看看吧。
环境变量数组
数组ENVIRON被分别添加到gawk和MKS awk中。
然后被添加到System V Realease 4 nawk中,现在被包含在POSIX表侄女的awk中。它允许你访问环境变量。
BEGIN{
for ( env in ENVRION)
print env “=“ ENVIRON[env]
}
这部分实验结果数组为空,原因不明。
函数
9个内置函数归为算数函数。
cos(x) x的余弦
exp(x) e的x次幂
int(x) x的整数部分
log(x) x的自然对数(e为低)
sin(x) x的正弦(x为弧度)
sqrt(x) x的平方根
atan2(y,x) y/x的反正切
rand() 伪随机数,0~1(最小为0)
srand(x) 建立rand()的心的种子。如果没有指定中子数,就用当天的时间。
三角函数
三角函数sin() cos()的运行方式相同,弧度表示的角度作为参数并计算这个角的正弦或余弦
三角函数atan2()有两个参数并返回这两个数商的反正切
exp()是自然指数,以e为底的指数
函数log()是函数exp()的反函数,即x的自然对数。
sqrt()的参数只有一个,返回这个数的正平方根。
整数函数int(),取整
随机数的生成
rand()生成一个0到1之间的浮点型的伪随机数。
函数srand()为随机数发生器设置一个种子数,或起点数。如果调用srand()时没有参数,它将用当时的时间来生成一个种子数。
如果没有调用srand(),awk在开始执行程序之前默认以某个常量为参数调用srand()。使得你的程序在每次运行时都从同一个种子数开始。这可以用于重复测试相同的操作,但是如果希望程序在不同的时间运行具有不同的操作则不合适。
BEGIN{
print rand()
print rand()
srand()
print rand()
print rand()
}
awk -f awkrand
0.237788
0.291066
0.213636
0.754719
awk -f awkrand
0.237788
0.291066
0.758529
0.904859
两次运行,发现前两个随机数一样,而后两个不一样
彩票生成器:
1.传入2参数,第一个是取数数量,第二个是最大数
2.使用随机数生成1个,乘以最大数,取整,保存到数组
3.循环生成第二个,检测是否与以生成数重复,不重复保存继续;重复舍弃继续
4检测数组数量,达到取数数量后退出循环;没达到则重复3
字符串函数
内置字符串函数比算数函数更重要。
awk被设计成字符串处理语言。
|
awk函数 |
描述 |
|
gsub(r,s,t) |
在字符串t中用字符串s替换和正则表达式r匹配的所有字符串。返回替换的个数。如果没有给出t,默认为$0 |
|
index(s,t) |
返回字符串t在字符串s中的位置,如果没有指定s,则返回0 |
|
length(s) |
返回字符串s的长度,当没有给s时,返回$0的长度 |
|
match(s,r) |
如果正则表达式r在s中出现,则返回出现的其实位置;如果在s中没有发现r,则返回0.设置RSTART和RLENGTH |
|
split(s,a,sep) |
使用字段分隔sep将字符串s分解到数组a的元素中,返回元素的个数。如果没有给出sep,则使用FS。数组分隔和字段分隔采用同样的方式。 |
|
sprintf(’fmt’,expr) |
对expr使用printf格式说明 |
|
sub(r,s,t) |
在字符串t中使用s替换正则表撒事r的首次匹配。如果成功则返回1,否则返回0.如果没有给出t,默认为$0 |
|
substr(s,p,n) |
返回字符串s中从位置p开始最大长度为n的字符串。如果没有给出n,返回从p开始剩余的字符串。 |
|
tolower(s) |
将字符串s中的所有大写字符转换为小写,并返回新字符串 |
|
toupper(s) |
将字符串s中的所有小写字符串转换为大写,并返回新字符串。 |
子串
index()和substr()都是用于处理子串,给定字符串s,函数index(s,t)返回t在s中出现的最左边的位置。字符串的开始位置是1(这跟c语言不同)
例子:
pos=index(“mississippi”,”is”)
pos值为2.如果没有发现子串,函数index()返回0
给定字符串s,substr(s,p)返回从位置p开始的字符。
例子:
phone = substr(“707 555-1111”,5)
返回555-1111
还可以提供第3个参数来表示返回字符的个数。
phone = substr(“707 555-1111”,1,3)
返回707
这两个函数经常一起使用。
例子:
awk ’
BEGIN{ upper= ’ABCDEFGHIJKLMNOPQRSTUVWXYZ’
lower=”abcdefghijklmnopqrstuvwxyz”
}
{
firstchar = substr($1,1,1)
if (char = index(lower,firstchar))
{
$1 =substr(upper,char,1)substr($1,2)
}
print $0
}
字符串长度
内置函数length()可以知道一个字符串中有多少个字符。
如果length()调用时没有给参数,将返回$0的长度
一个处理断行的方法就是用用length()函数得到每个字读啊的长度,这昂可能效率更高。通过累计这些长度,当一个新的字段使得行的长度超过某个特定的数据时,我们就指定一个换行。
替换函数
awk提供了两个替换函数:sub()和gsub()。两者之间的区别是gsub()可以实现输入字符串中所有位置的替换,而sub()只实现第一个位置的替换这使得gsbu()和sed中用g(全局的)标志的替换命令相同。
两个函数都至少需要两个参数。第一个参数是正则表达式(用斜杠包围着),用于和一个moist匹配;第二个参数是一个字符串,用来替换模式匹配的字符串。
正则表达式可以用一个变量来给出,这种情况将省略斜杠。
第三个可选的参数指定的字符串是将被替换的目标。如果没有第三个参数,将当前输入记录($0)作为被替换的字符串。
替换函数直接改变指定的字符串。假设函数能正常工作,你或许希望当发生替换后函数返回替换后的新字符串。但替换函数实际上返回的是替换的数量。在sub()运行成功时总是返回1,不成功时都返回0.因此通过测试这个结果来确定是否执行了替换操作。
例子:
awk -f awkreplace test.txt
执行结果:
posix
this not posix
I like posix
查看代码:cat awkreplace
{
if( gsub(/unix/,”posix”,$0))
print $0
}
如果在替换字符串中出现了“&”字符,它将被与正则表达式匹配的字符串代替。
“&”将输出一个字符“&”。
例子:
awk -f awkreplace2 test.txt
执行结果:原字符串unix被替换为“FBunixFR”
FBunixFR
this not FBunixFR
I like FBunixFR
查看代码:
cat awkreplace2
{
if( gsub(/unix/,”\FB&\FR”,$0))
print $0
}
大小写转换
tolower()和toupper()。
每个函数需要一饿字符串参数,并返回该字符串的一个备份,其中所有字符串都发生了转换。
例子:
awk -f awktolower test.txt
执行结果:
unix
this not unix
i like unix
查看代码:
cat awktolower
{
print tolower($0)
}
awk -f awktoupper test.txt
执行结果:
UNIX
THIS NOT UNIX
I LIKE UNIX
查看代码:
cat awktoupper
{
print toupper($0)
}
match()函数
match()用于确定一个正则表达式是否和指定的字符串匹配。它需要两个参数,字符串和正则表达式。
注意:这个函数正则表达式在第二个位置,这个替换函数中正则表达式的位置不一样。
match()函数返回与正则表达式匹配的子串的开始位置。
例子:
awk -f awkmatch test.txt
0
1
1
[root@dellbook awk]# cat awkmatch
{
print match($0,/[A-Z]/)
}
match()函数也设置了两个系统变量:RSTART和RLENGTH。
RSTART中包含这个函数的返回值,即匹配子字符串的开始位置。RLENGTH中包含匹配的字符串的字符数。
当模式不匹配时,RSTART设置为0,RLENGTH设置为-1.
例子:
awk -f awkmatch test.txt
执行结果:
0 -1
1 1
1 1
查看代码:
cat awkmatch
{
match($0,/[A-Z]/)
print RSTART,RLENGTH
}
第一行没有匹配
第二第三行都是首字母是大写
再看一个替换大写字母的例子,例子中将使用index、substr、gsub和match总共4各函数。
例子:
awk脚本:awkmath1
BEGIN{ upper = “ABCDEFGHIJKLMNOPQRSTUVWXYZ”
lower = “abcdefghijklmnopqrstuvwxyz”
}
{
print $0
while (match($0,/[A-Z]+/))
{
for (x = RSTART; x < RSTART+RLENGTH; ++x) {
CAP = substr($0,x,1)
CHAR =index(upper, CAP)
gsub(CAP,substr(lower,CHAR,1),$0)
}
print $0
}
}
执行结果:
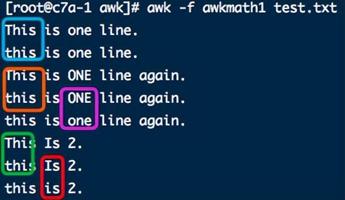
这里输出做了对比。先输出了原字符串,再输出一次循环后的字符串。
每次循环只处理找到的第一处连续的大写字母字符串。
例子中,文本test.txt文件中第2和第3行都有2除大写字符串。可以看到2次循环后完成替换。
如果想要替换包含2个以及2个以上大写字母子串,match的正则条件改为“[A-Z][A-Z]+”
gsub函数也要相应修改,原代码中只替换1个字符。
如果想要替换多个相同字符中的最后一个,可以看下面这个例子。
例子:
将文本中最后一个冒号替换为“—”
awk脚本: awkmatch3
{
if (match($0,/:[^*]*:/)) {
before = substr($0,1,(RSTART + RLENGTH-2))
after = substr($0,(RSTART + RLENGTH))
$0 = before “—” after
}
print $0
}
执行结果:
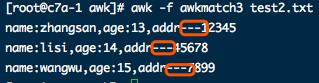
基本就是将最后一个冒号之前和之后的字符串取出来,再跟新的连接符“—”拼接
以上就是关于gg修改器的游戏代码_gg修改器游戏版的全部内容,希望对大家有帮助。

gg游戏修改器改点卷,GG游戏修改器改点卷玩游戏更加快乐 大小:4.33MB9,770人安装 随着游戏行业的不断发展,越来越多的玩家加入到各种游戏的行列中。不过随之也带来了……
下载
gg修改器改评分要root吗,GG修改器改评分无需root 大小:14.44MB9,783人安装 GG修改器是一款神奇的工具,可以修改手机游戏的内部数据,如金币、钻石、经验值等。……
下载
GG游戏修改器教程,gg游戏修改器使用 大小:11.99MB10,051人安装 相关下载: 相关下载: 飞天方法: 搜索1;0.01;0.2;0.3::40(F类数据)下飞机后改……
下载
gg修改器框架版下载中文_GG修改器 框架 大小:16.04MB10,775人安装 大家好,今天小编为大家分享关于gg修改器框架版下载中文_GG修改器 框架的内容,赶快……
下载
gg修改器免root版怎么使用,GG修改器免root版使用方法 大小:18.42MB11,195人安装 gg修改器免root版怎么使用,GG修改器免root版使用方法? gg修改器免root版使用方法很……
下载
gg修改器root启动失败_gg修改器开启不了ROOT怎么办 大小:17.14MB10,723人安装 大家好,今天小编为大家分享关于gg修改器root启动失败_gg修改器开启不了ROOT怎么办……
下载
gg修改器下载中文教学,让您游戏更流畅GG修改器下载中文教学 大小:6.73MB9,638人安装 游戏中卡顿、卡屏、延迟等问题一直是影响游戏体验的一大难题。而GG修改器作为一款优……
下载
王者体验服gg修改器,GG修改器能不能改王者体验服 大小:7.11MB10,926人安装 122诸葛亮(旧版) 132马克波罗(旧) 156张亮(旧) 182干将(旧) 225庞统(傀……
下载
gg游戏修改器改星元地狱火,使用GG游戏修改器让《星元地狱火》变得更加精彩 大小:5.60MB9,363人安装 作为一款多人在线游戏,《星元地狱火》一直备受玩家们的热爱。然而,随着游戏的深入……
下载
新版gg修改器字符串,gg修改器字符串 大小:17.33MB10,782人安装 六,游戏搜索的时候闪退怎么办点击修改器的左上角的三条杠,找到对gg隐藏,把234……
下载