GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器修改游戏是s还是h_gg修改器都能修改什么游戏的内容,赶快来一起来看看吧。
虽然 Docker 已经很强大了,但是在实际使用上还是有诸多不便,比如集群管理、资源调度、文件管理等等。那么在这样一个百花齐放的容器时代涌现出了很多解决方案,比如 Mesos、Swarm、Kubernetes 等等,其中谷歌开源的 Kubernetes 是作为老大哥的存在。也可参考:k8s 和 Docker 关系简单说明
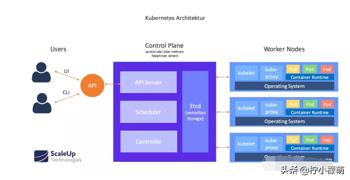
kubernetes 已经成为容器编排领域的王者,它是基于容器的集群编排引擎,具备扩展集群、滚动升级回滚、弹性伸缩、自动治愈、服务发现等多种特性能力。
Kubernetes 的出现不仅主宰了容器编排的市场,更改变了过去的运维方式,不仅将开发与运维之间边界变得更加模糊,而且让 DevOps 这一角色变得更加清晰,每一个软件工程师都可以通过 Kubernetes 来定义服务之间的拓扑关系、线上的节点个数、资源使用量并且能够快速实现水平扩容、蓝绿部署等在过去复杂的运维操作。
主要介绍学习一些什么知识

传统的客户端服务端架构
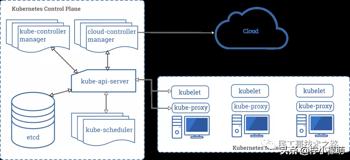
Kubernetes 遵循非常传统的客户端/服务端的架构模式,客户端可以通过 RESTful 接口或者直接使用 kubectl 与 Kubernetes 集群进行通信,这两者在实际上并没有太多的区别,后者也只是对 Kubernetes 提供的 RESTful API 进行封装并提供出来。每一个 Kubernetes 集群都是由一组 Master 节点和一系列的 Worker 节点组成,其中 Master 节点主要负责存储集群的状态并为 Kubernetes 对象分配和调度资源。
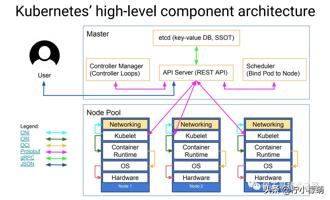
作为管理集群状态的 Master 节点,它主要负责接收客户端的请求,安排容器的执行并且运行控制循环,将集群的状态向目标状态进行迁移。Master 节点内部由下面三个组件构成:
API Server: 负责处理来自用户的请求,其主要作用就是对外提供 RESTful 的接口,包括用于查看集群状态的读请求以及改变集群状态的写请求,也是唯一一个与 etcd 集群通信的组件。
etcd: 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
Scheduler: 主节点上的组件,该组件监视那些新创建的未指定运行节点的 Pod,并选择节点让 Pod 在上面运行。调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
controller-manager: 在主节点上运行控制器的组件,从逻辑上讲,每个控制器都是一个单独的进程,但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。这些控制器包括:节点控制器(负责在节点出现故障时进行通知和响应)、副本控制器(负责为系统中的每个副本控制器对象维护正确数量的 Pod)、端点控制器(填充端点 Endpoints 对象,即加入 Service 与 Pod))、服务帐户和令牌控制器(为新的命名空间创建默认帐户和 API 访问令牌)。
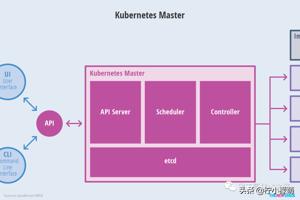
其他的 Worker 节点实现就相对比较简单了,它主要由 kubelet 和 kube-proxy 两部分组成。
kubelet: 是工作节点执行操作的 agent,负责具体的容器生命周期管理,根据从数据库中获取的信息来管理容器,并上报 pod 运行状态等。
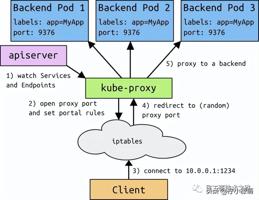
kube-proxy: 是一个简单的网络访问代理,同时也是一个 Load Balancer。它负责将访问到某个服务的请求具体分配给工作节点上同一类标签的 Pod。kube-proxy 实质就是通过操作防火墙规则(iptables或者ipvs)来实现 Pod 的映射。
Container Runtime: 容器运行环境是负责运行容器的软件,Kubernetes 支持多个容器运行环境: Docker、 containerd、cri-o、 rktlet 以及任何实现 Kubernetes CRI(容器运行环境接口)。
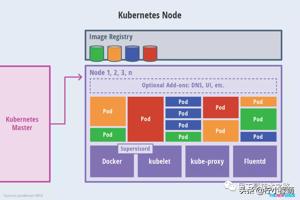
主要介绍关于 K8s 的一些基本概念
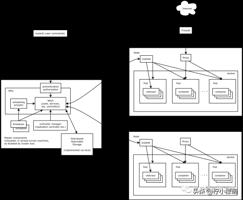
主要由以下几个核心组件组成:
除了核心组件,还有一些推荐的插件:
以上内容参考链接: https://www.escapelife.site/posts/2c4214e7.html
安装v1.16.0版本,竟然成功了。记录在此,避免后来者踩坑。
本篇文章,安装大步骤如下:
详细安装步骤参考:CentOS 搭建 K8S,一次性成功,收藏了!集群安装教程请参考:全网最新、最详细基于V1.20版本,无坑部署最小化 K8S 集群教程
Pod 就是最小并且最简单的 Kubernetes 对象
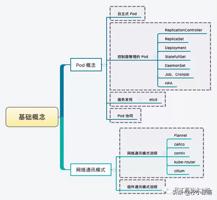
Pod、Service、Volume 和 Namespace 是 Kubernetes 集群中四大基本对象,它们能够表示系统中部署的应用、工作负载、网络和磁盘资源,共同定义了集群的状态。Kubernetes 中很多其他的资源其实只对这些基本的对象进行了组合。
详细介绍请参考:Kubernetes 之 Pod 实现原理
Kuternetes 企业级 Docker 私有仓库 Harbor 工具。
Harbor 的每个组件都是以 Docker 容器的形式构建的,使用 Docker Compose 来对它进行部署。用于部署 Harbor 的 Docker Compose 模板位于 /Deployer/pose.yml 中,其由 5 个容器组成,这几个容器通过 Docker link 的形式连接在一起,在容器之间通过容器名字互相访问。对终端用户而言,只需要暴露 Proxy(即Nginx) 的服务端口即可。
详细介绍与搭建步骤请参考:企业级环境中基于 Harbor 搭建
YAML 是一种非常简洁/强大/专门用来写配置文件的语言!
YAML 全称是 ”YAML Ain’t a Markup Language” 的递归缩写,该语言的设计参考了 JSON / XML 和 SDL 等语言,强调以数据为中心,简洁易读,编写简单。

学过编程的人理解起来应该非常容易

推荐给大家一篇文章:Kubernetes 之 YAML 语法,这篇文章介绍的非常详细,有很多例子说明。
K8S 中所有的内容都抽象为了资源,资源实例化之后就叫做对象。
在 Kubernetes 系统中,Kubernetes 对象是持久化的实体,Kubernetes 使用这些实体去表示整个集群的状态。特别地,它们描述了如下信息:
Kubernetes 对象是 “目标性记录” —— 一旦创建对象,Kubernetes 系统将持续工作以确保对象存在。通过创建对象,本质上是在告知 Kubernetes 系统,所需要的集群工作负载看起来是什么样子的,这就是 Kubernetes 集群的期望状态。
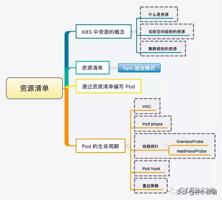
Kubernetes 之资源清单详细介绍看这里
Kubernetes 资源控制器配置文件的编写是学习 K8S 的重中之重!
资源配额控制器确保了指定的资源对象始终不会超过配置的资源,能够有效的降低整个系统宕机的机率,增强系统的鲁棒性,对整个集群的稳定性有非常重要的作用。
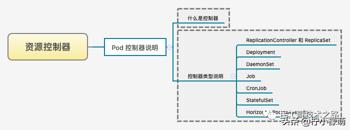
Kubernetes 资源控制器使用指南手册
Kubernetes 中为了实现服务实例间的负载均衡和不同服务间的服务发现,创造了 Service 对象,同时又为从集群外部访问集群创建了 Ingress 对象。
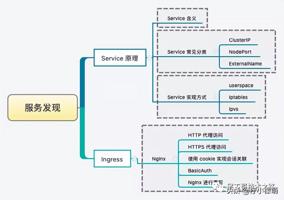
可参考:Kubernetes 之服务发现
我们都知道传统的 SVC 只支持四层上面的代码,而对于七层上的代码而无能为力。比如:我们使用 K8S 集群对外提供 HTTPS 的服务,为了方便和便捷,我们需要在对外的 Nginx 服务上面配置 SSL 加密,但是将请求发送给后端服务的时候,进行证书卸载的操作,后续都是用 HTTP 的协议进行处理。而面对此问题,K8S 中给出了使用 Ingress (K8S在1.11版本中推出了)来进行处理。
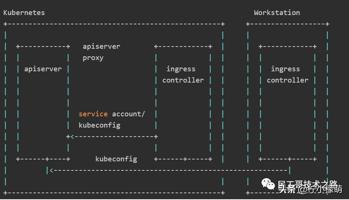
更多详细内容请参阅:Kubernetes 之 Ingress 服务,介绍关于 Ingress 服务的安装方式,配置关于 Ingress 服务的 HTTP 代理访问,介绍 Ingress 服务的 BasicAuth 认证方式,介绍 Ingress 的进行规则重写的方式。
在之前的文章中,我们已经知道了很多 K8S 中的组件了,包括资源控制器等。在资源控制器中,我们说到了 StatefulSet 这个控制器组件,其专门为了有状态服务而生的,而对应的存储要存放到哪里呢?
介绍 K8S 中常见的存储机制可以让我们所使用的:Kubernetes 之数据存储
有这样一个需求,就是集群中多台服务的配置是不一致的。这就导致资源分配并不是均匀的,比如我们需要有些服务节点用来运行计算密集型的服务,而有些服务节点来运行需要大量内存的服务。而在 k8s 中当然也配置了相关服务来处理上述的问题,那就是 Scheduler。
Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 Pod 分配到集群的节点上。听起来非常简单,但有很多要考虑的问题:
Scheduler 是作为单独的程序运行的,启动之后会一直坚挺 API Server,获取 PodSpec.NodeName 为空的 Pod,对每个 Pod 都会创建一个 binding,表明该 Pod 应该放到哪个节点上。
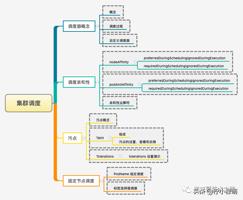
详细的介绍请参考:Kubernetes 之集群调度
kubectl 是 Kubernetes 自带的客户端,可以用它来直接操作 Kubernetes 集群。
日常在使用 Kubernetes 的过程中,kubectl 工具可能是最常用的工具了,所以当我们花费大量的时间去研究和学习 Kuernetes 的时候,那么我们就非常有必要去了解下如何高效的使用它了。
从用户角度来说,kubectl 就是控制 Kubernetes 的驾驶舱,它允许你执行所有可能的 Kubernetes 操作;从技术角度来看,kubectl 就是 Kubernetes API 的一个客户端而已。

Kubernetes API 是一个 HTTP REST API 服务,该 API 服务才是 Kubernetes 的真正用到的用户接口,所以 Kubernetes 通过该 API 进行实际的控制。这也就意味着每个 Kubernetes 的操作都会通过 API 端点暴露出去,当然也就可以通过对这些 API 端口进行 HTTP 请求来执行相应的操作。所以,kubectl 最主要的工作就是执行 Kubernetes API 的 HTTP 请求。
get #显示一个或多个资源
describe #显示资源详情
create #从文件或标准输入创建资源
update #从文件或标准输入更新资源
delete #通过文件名、标准输入、资源名或者 label 删除资源
log #输出 pod 中一个容器的日志
rolling-update #对指定的 RC 执行滚动升级
exec #在容器内部执行命令
port-forward #将本地端口转发到 Pod
proxy #为 Kubernetes API server 启动代理服务器
run #在集群中使用指定镜像启动容器
expose #将 SVC 或 pod 暴露为新的 kubernetes service
label #更新资源的 label
config #修改 kubernetes 配置文件
cluster-info #显示集群信息
api-versions #以”组/版本”的格式输出服务端支持的 API 版本
version #输出服务端和客户端的版本信息
help #显示各个命令的帮助信息
ingress-nginx #管理 ingress 服务的插件(官方安装和使用方式)
# Kubectl自动补全
$ source <(pletion zsh)
$ source <(pletion bash)
# 显示合并后的 kubeconfig 配置
$ kubectl config view
# 获取pod和svc的文档
$ kubectl explain pods,svc
# yaml
kubectl create -f xxx-rc.yaml
kubectl create -f xxx-service.yaml
# json
kubectl create -f ./pod.json
cat pod.json | kubectl create -f -
# yaml2json
kubectl create -f docker-registry.yaml --edit -o json
kubectl create -f xxx-service.yaml -f xxx-rc.yaml
kubectl create -f <目录>
kubectl create -f https://git.io/vPieo
kubectl get nodes
kubectl get namespace
# 查看子命令帮助信息
kubectl get --help
# 列出默认namespace中的所有pod
kubectl get pods
# 列出指定namespace中的所有pod
kubectl get pods --namespace=test
# 列出所有namespace中的所有pod
kubectl get pods --all-namespaces
# 列出所有pod并显示详细信息
kubectl get pods -o wide
kubectl get replicationcontroller web
kubectl get -k dir/
kubectl get -f pod.yaml -o json
kubectl get rc/web service/frontend pods/web-pod-13je7
kubectl get pods/app-prod-78998bf7c6-ttp9g --namespace=test -o wide
kubectl get -o template pod/web-pod-13je7 --template={{.status.phase}}
# 列出该namespace中的所有pod包括未初始化的
kubectl get pods,rc,services --include-uninitialized
kubectl get rc
# 查看全部deployment
kubectl get deployment
# 列出指定deployment
kubectl get deployment my-app
kubectl get svc
kubectl get service
kubectl get pods -n default
kubectl get pods --all-namespace
kubectl describe pods/nginx
kubectl describe pods my-pod
kubectl describe -f pod.json
kubectl describe nodes c1
kubectl describe pods <rc-name>
# 滚动更新 pod frontend-v1
kubectl rolling-update frontend-v1 -f frontend-v2.json
# 更新资源名称并更新镜像
kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2
# 更新 frontend pod 中的镜像
kubectl rolling-update frontend --image=image:v2
# 退出已存在的进行中的滚动更新
kubectl rolling-update frontend-v1 frontend-v2 --rollback
# 强制替换; 删除后重新创建资源; 服务会中断
kubectl replace --force -f ./pod.json
# 添加标签
kubectl label pods my-pod new-label=awesome
# 添加注解
kubectl annotate pods my-pod icon-url=http://goo.gl/XXBTWq
# 部分更新节点
kubectl patch node k8s-node-1 -p ’{"spec":{"unschedulable":true}}’
# 更新容器镜像;spec.containers[*].name 是必须的,因为这是合并的关键字
kubectl patch pod valid-pod -p
’{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}’
# Scale a replicaset named ’foo’ to 3
kubectl scale --replicas=3 rs/foo
# Scale a resource specified in "foo.yaml" to 3
kubectl scale --replicas=3 -f foo.yaml
# If the deployment named mysql’s current size is 2, scale mysql to 3
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
# Scale multiple replication controllers
kubectl scale --replicas=5 rc/foo rc/bar rc/baz
# yaml文件名字按照你创建时的文件一致
kubectl delete -f xxx.yaml
kubectl delete pods -l name=<label-name>
kubectl delete services -l name=<label-name>
kubectl delete pods,services -l name=<label-name>
kubectl delete pods --all
kubectl delete service --all
kubectl delete deployment --all
在编辑器中编辑任何 API 资源
# 编辑名为docker-registry的service
kubectl edit svc/docker-registry
在寄主机上,不进入容器直接执行命令
kubectl exec mypod -- date
kubectl exec mypod --namespace=test -- date
kubectl exec mypod -c ruby-container -- date
kubectl exec mypod -c ruby-container -it -- bash
# 不实时刷新kubectl logs mypod
kubectl logs mypod --namespace=test
kubectl logs -f mypod -c ruby-container
对于新安装的 Kubernetes,经常出现的一个问题是 Service 没有正常工作。如果您已经运行了 Deployment 并创建了一个 Service,但是当您尝试访问它时没有得到响应,希望这份文档(全网最详细的 K8s Service 不能访问排查流程)能帮助您找出问题所在。
在某些情况下,经常发现 kubectl 进程挂起现象,然后在 get 时候发现删了一半,而另外的删除不了
[root@k8s-master ~]# kubectl get -f fluentd-elasticsearch/
NAME DESIRED CURRENT READY AGE
rc/elasticsearch-logging-v1 0 2 2 15h
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/kibana-logging 0 1 1 1 15h
Error from server (NotFound): services "elasticsearch-logging" not found
Error from server (NotFound): daemonsets.extensions "fluentd-es-v1.22" not found
Error from server (NotFound): services "kibana-logging" not found
删除这些 deployment,service 或者 rc 命令如下:
kubectl delete deployment kibana-logging -n kube-system --cascade=false
kubectl delete deployment kibana-logging -n kube-system --ignore-not-found
delete rc elasticsearch-logging-v1 -n kube-system --force now --grace-period=0
rm -rf /var/lib/etcd/*
删除后重新 reboot master 结点。
reset etcd 后需要重新设置网络
etcdctl mk /atomic.io/network/config ’{ "Network": "192.168.0.0/16" }’
每次启动都是报如下问题:
start request repeated too quickly for kube-apiserver.service
但其实不是启动频率问题,需要查看, /var/log/messages,在我的情况中是因为开启 ServiceAccount 后找不到 ca.crt 等文件,导致启动出错。
May 21 07:56:41 k8s-master kube-apiserver: Flag --port has been deprecated, see --insecure-port instead.
May 21 07:56:41 k8s-master kube-apiserver: F0521 07:56:41.692480 4299 universal_validation.go:104] Validate server run options failed: unable to load client CA file: open /var/run/kubernetes/ca.crt: no such file or directory
May 21 07:56:41 k8s-master systemd: kube-apiserver.service: main process exited, code=exited, status=255/n/a
May 21 07:56:41 k8s-master systemd: Failed to start Kubernetes API Server.
May 21 07:56:41 k8s-master systemd: Unit kube-apiserver.service entered failed state.
May 21 07:56:41 k8s-master systemd: kube-apiserver.service failed.
May 21 07:56:41 k8s-master systemd: kube-apiserver.service holdoff time over, scheduling restart.
May 21 07:56:41 k8s-master systemd: start request repeated too quickly for kube-apiserver.service
May 21 07:56:41 k8s-master systemd: Failed to start Kubernetes API Server.
在部署 fluentd 等日志组件的时候,很多问题都是因为需要开启 ServiceAccount 选项需要配置安全导致,所以说到底还是需要配置好 ServiceAccount.
在配置 fluentd 时候出现cannot create /var/log/fluentd.log: Permission denied 错误,这是因为没有关掉 SElinux 安全导致。
可以在 /etc/selinux/config 中将 SELINUX=enforcing 设置成 disabled,然后 reboot
首先生成各种需要的 keys,k8s-master 需替换成 master 的主机名.
openssl genrsa -out ca.key 2048
openssl req -x509 -new -nodes -key ca.key -subj "/CN=k8s-master" -days 10000 -out ca.crt
openssl genrsa -out server.key 2048
echo subjectAltName=IP:10.254.0.1 > f
#ip由下述命令决定
#kubectl get services --all-namespaces |grep ’default’|grep ’kubernetes’|grep ’443’|awk ’{print $3}’
openssl req -new -key server.key -subj "/CN=k8s-master" -out server.csr
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial -extfile f -out server.crt -days 10000
如果修改 /etc/kubernetes/apiserver 的配置文件参数的话,通过 systemctl start kube-apiserver 启动失败,出错信息为:
Validate server run options failed: unable to load client CA file: open /root/keys/ca.crt: permission denied
但可以通过命令行启动 API Server
/usr/bin/kube-apiserver --logtostderr=true --v=0 --etcd-servers=http://k8s-master:2379 --address=0.0.0.0 --port=8080 --kubelet-port=10250 --allow-privileged=true --service-cluster-ip-range=10.254.0.0/16 --admission-control=ServiceAccount --insecure-bind-address=0.0.0.0 --client-ca-file=/root/keys/ca.crt --tls-cert-file=/root/keys/server.crt --tls-private-key-file=/root/keys/server.key --basic-auth-file=/root/keys/basic_auth.csv --secure-port=443 &>> /var/log/kubernetes/kube-apiserver.log &
命令行启动 Controller-manager
/usr/bin/kube-controller-manager --logtostderr=true --v=0 --master=http://k8s-master:8080 --root-ca-file=/root/keys/ca.crt --service-account-private-key-file=/root/keys/server.key & >>/var/log/kubernetes/kube-controller-manage.log
etcd是kubernetes 集群的zookeeper进程,几乎所有的service都依赖于etcd的启动,比如flanneld,apiserver,docker…..在启动etcd是报错日志如下:
May 24 13:39:09 k8s-master systemd: Stopped Flanneld overlay address etcd agent.
May 24 13:39:28 k8s-master systemd: Starting Etcd Server...
May 24 13:39:28 k8s-master etcd: recognized and used environment variable ETCD_ADVERTISE_CLIENT_URLS=http://etcd:2379,http://etcd:4001
May 24 13:39:28 k8s-master etcd: recognized environment variable ETCD_NAME, but unused: shadowed by corresponding flag
May 24 13:39:28 k8s-master etcd: recognized environment variable ETCD_DATA_DIR, but unused: shadowed by corresponding flag
May 24 13:39:28 k8s-master etcd: recognized environment variable ETCD_LISTEN_CLIENT_URLS, but unused: shadowed by corresponding flag
May 24 13:39:28 k8s-master etcd: etcd Version: 3.1.3
May 24 13:39:28 k8s-master etcd: Git SHA: 21fdcc6
May 24 13:39:28 k8s-master etcd: Go Version: go1.7.4
May 24 13:39:28 k8s-master etcd: Go OS/Arch: linux/amd64
May 24 13:39:28 k8s-master etcd: setting maximum number of CPUs to 1, total number of available CPUs is 1
May 24 13:39:28 k8s-master etcd: the server is already initialized as member before, starting as etcd member...
May 24 13:39:28 k8s-master etcd: listening for peers on http://localhost:2380
May 24 13:39:28 k8s-master etcd: listening for client requests on 0.0.0.0:2379
May 24 13:39:28 k8s-master etcd: listening for client requests on 0.0.0.0:4001
May 24 13:39:28 k8s-master etcd: recovered store from snapshot at index 140014
May 24 13:39:28 k8s-master etcd: name = master
May 24 13:39:28 k8s-master etcd: data dir = /var/lib/etcd/default.etcd
May 24 13:39:28 k8s-master etcd: member dir = /var/lib/etcd/default.etcd/member
May 24 13:39:28 k8s-master etcd: heartbeat = 100ms
May 24 13:39:28 k8s-master etcd: election = 1000ms
May 24 13:39:28 k8s-master etcd: snapshot count = 10000
May 24 13:39:28 k8s-master etcd: advertise client URLs = http://etcd:2379,http://etcd:4001
May 24 13:39:28 k8s-master etcd: ignored file 0000000000000001-0000000000012700.wal.broken in wal
May 24 13:39:29 k8s-master etcd: restarting member 8e9e05c52164694d in cluster cdf818194e3a8c32 mit index 148905
May 24 13:39:29 k8s-master etcd: 8e9e05c52164694d became follower at term 12
May 24 13:39:29 k8s-master etcd: newRaft 8e9e05c52164694d [peers: [8e9e05c52164694d], term: 12, commit: 148905, applied: 140014, lastindex: 148905, lastterm: 12]
May 24 13:39:29 k8s-master etcd: enabled capabilities for version 3.1
May 24 13:39:29 k8s-master etcd: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32 from store
May 24 13:39:29 k8s-master etcd: set the cluster version to 3.1 from store
May 24 13:39:29 k8s-master etcd: starting server... [version: 3.1.3, cluster version: 3.1]
May 24 13:39:29 k8s-master etcd: raft save state and entries error: open /var/lib/etcd/default.etcd/member/wal/0.tmp: is a directory
May 24 13:39:29 k8s-master systemd: etcd.service: main process exited, code=exited, status=1/FAILURE
May 24 13:39:29 k8s-master systemd: Failed to start Etcd Server.
May 24 13:39:29 k8s-master systemd: Unit etcd.service entered failed state.
May 24 13:39:29 k8s-master systemd: etcd.service failed.
May 24 13:39:29 k8s-master systemd: etcd.service holdoff time over, scheduling restart.
核心语句:
raft save state and entries error: open /var/lib/etcd/default.etcd/member/wal/0.tmp: is a directory
进入相关目录,删除 0.tmp,然后就可以启动啦!
问题背景:当前部署了 3 个 etcd 节点,突然有一天 3 台集群全部停电宕机了。重新启动之后发现 K8S 集群是可以正常使用的,但是检查了一遍组件之后,发现有一个节点的 etcd 启动不了。
经过一遍探查,发现时间不准确,通过以下命令 ntpdate ntp. 重新将时间调整正确,重新启动 etcd,发现还是起不来,报错如下:
Mar 05 14:27:15 k8s-node2 etcd[3248]: etcd Version: 3.3.13
Mar 05 14:27:15 k8s-node2 etcd[3248]: Git SHA: 98d3084
Mar 05 14:27:15 k8s-node2 etcd[3248]: Go Version: go1.10.8
Mar 05 14:27:15 k8s-node2 etcd[3248]: Go OS/Arch: linux/amd64
Mar 05 14:27:15 k8s-node2 etcd[3248]: setting maximum number of CPUs to 4, total number of available CPUs is 4
Mar 05 14:27:15 k8s-node2 etcd[3248]: the server is already initialized as member before, starting as etcd member
...
Mar 05 14:27:15 k8s-node2 etcd[3248]: peerTLS: cert = /opt/etcd/ssl/server.pem, key = /opt/etcd/ssl/server-key.pe
m, ca = , trusted-ca = /opt/etcd/ssl/ca.pem, client-cert-auth = false, crl-file =
Mar 05 14:27:15 k8s-node2 etcd[3248]: listening for peers on https://192.168.25.226:2380
Mar 05 14:27:15 k8s-node2 etcd[3248]: The scheme of client url http://127.0.0.1:2379 is HTTP while peer key/cert
files are presented. Ignored key/cert files.
Mar 05 14:27:15 k8s-node2 etcd[3248]: listening for client requests on 127.0.0.1:2379
Mar 05 14:27:15 k8s-node2 etcd[3248]: listening for client requests on 192.168.25.226:2379
Mar 05 14:27:15 k8s-node2 etcd[3248]: member 9c166b8b7cb6ecb8 has already been bootstrapped
Mar 05 14:27:15 k8s-node2 systemd[1]: etcd.service: main process exited, code=exited, status=1/FAILURE
Mar 05 14:27:15 k8s-node2 systemd[1]: Failed to start Etcd Server.
Mar 05 14:27:15 k8s-node2 systemd[1]: Unit etcd.service entered failed state.
Mar 05 14:27:15 k8s-node2 systemd[1]: etcd.service failed.
Mar 05 14:27:15 k8s-node2 systemd[1]: etcd.service failed.
Mar 05 14:27:15 k8s-node2 systemd[1]: etcd.service holdoff time over, scheduling restart.
Mar 05 14:27:15 k8s-node2 systemd[1]: Starting Etcd Server...
Mar 05 14:27:15 k8s-node2 etcd[3258]: recognized environment variable ETCD_NAME, but unused: shadowed by correspo
nding flag
Mar 05 14:27:15 k8s-node2 etcd[3258]: recognized environment variable ETCD_DATA_DIR, but unused: shadowed by corr
esponding flag
Mar 05 14:27:15 k8s-node2 etcd[3258]: recognized environment variable ETCD_LISTEN_PEER_URLS, but unused: shadowed
by corresponding flag
Mar 05 14:27:15 k8s-node2 etcd[3258]: recognized environment variable ETCD_LISTEN_CLIENT_URLS, but unused: shadow
ed by corresponding flag
Mar 05 14:27:15 k8s-node2 etcd[3258]: recognized environment variable ETCD_INITIAL_ADVERTISE_PEER_URLS, but unuse
d: shadowed by corresponding flag
Mar 05 14:27:15 k8s-node2 etcd[3258]: recognized environment variable ETCD_ADVERTISE_CLIENT_URLS, but unused: sha
dowed by corresponding flag
Mar 05 14:27:15 k8s-node2 etcd[3258]: recognized environment variable ETCD_INITIAL_CLUSTER, but unused: shadowed
by corresponding flag
Mar 05 14:27:15 k8s-node2 etcd[3258]: recognized environment variable ETCD_INITIAL_CLUSTER_TOKEN, but unused: sha
dowed by corresponding flag
Mar 05 14:27:15 k8s-node2 etcd[3258]: recognized environment variable ETCD_INITIAL_CLUSTER_STATE, but unused: sha
dowed by corresponding flag
解决方法:
检查日志发现并没有特别明显的错误,根据经验来讲,etcd 节点坏掉一个其实对集群没有大的影响,这时集群已经可以正常使用了,但是这个坏掉的 etcd 节点并没有启动,解决方法如下:
进入 etcd 的数据存储目录进行备份 备份原有数据:
cd /var/lib/etcd/default.etcd/member/
cp * /data/bak/
删除这个目录下的所有数据文件
rm -rf /var/lib/etcd/default.etcd/member/*
停止另外两台 etcd 节点,因为 etcd 节点启动时需要所有节点一起启动,启动成功后即可使用。
#master 节点
systemctl stop etcd
systemctl restart etcd
#node1 节点
systemctl stop etcd
systemctl restart etcd
#node2 节点
systemctl stop etcd
systemctl restart etcd
在每台服务器需要建立主机互信的用户名执行以下命令生成公钥/密钥,默认回车即可
ssh-keygen -t rsa
可以看到生成个公钥的文件。
互传公钥,第一次需要输入密码,之后就OK了。
ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.199.132 (-p 2222)
-p 端口 默认端口不加-p,如果更改过端口,就得加上-p. 可以看到是在.ssh/下生成了个 authorized_keys的文件,记录了能登陆这台服务器的其他服务器的公钥。
测试看是否能登陆:
ssh 192.168.199.132 (-p 2222)
hostnamectl set-hostname k8s-master1
如果不安装或者不输出,可以将 update 修改成 install 再运行。
yum install update
yum update kernel
yum update kernel-devel
yum install kernel-headers
yum install gcc
yum install gcc make
运行完后
sh VBoxLinuxAdditions.run
可以通过下面命令强制删除
kubectl delete pod NAME --grace-period=0 --force
删除namespace一直处于Terminating状态
可以通过以下脚本强制删除
[root@k8s-master1 k8s]# cat delete-ns.sh
#!/bin/bash
set -e
useage(){
echo "useage:"
echo " delns.sh NAMESPACE"
}
if [ $# -lt 1 ];then
useage
exit
fi
NAMESPACE=$1
JSONFILE=${NAMESPACE}.json
kubectl get ns "${NAMESPACE}" -o json > "${JSONFILE}"
vi "${JSONFILE}"
curl -k -H "Content-Type: application/json" -X PUT --data-binary @"${JSONFLE}"
http://127.0.0.1:8001/api/v1/namespaces/"${NAMESPACE}"/finalize
下面我们创建一个对应的容器,该容器只有 requests 设定,但是没有 limits 设定,
- name: t02
image: busybox
command: ["/bin/sh"]
args: ["-c", "while true; do echo hello t02; sleep 10;done"]
resources:
requests:
memory: "100Mi"
cpu: "100m"
Kubernetes 上对应用程序进行故障排除的 6 个技巧 推荐给大家,日常排错必备。分享一份阿里云内部超全K8s实战手册,免费下载!
一个目标:容器操作;两地三中心;四层服务发现;五种 Pod 共享资源;六个 CNI 常用插件;七层负载均衡;八种隔离维度;九个网络模型原则;十类 IP 地址;百级产品线;千级物理机;万级容器;相如无亿,k8s 有亿:亿级日服务人次。
一个目标:容器操作
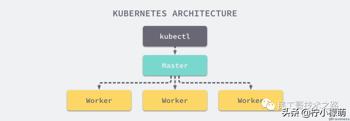
Kubernetes(k8s)是自动化容器操作的开源平台。这些容器操作包括:部署、调度和节点集群间扩展。
下面是 k8s 的架构拓扑图:
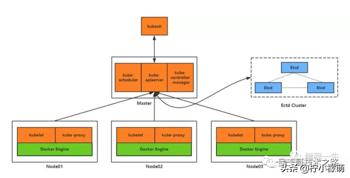
两地三中心
两地三中心包括本地生产中心、本地灾备中心、异地灾备中心。
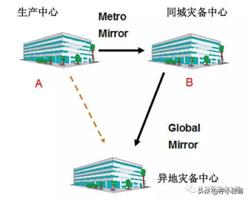
两地三中心要解决的一个重要问题就是数据一致性问题。
k8s 使用 etcd 组件作为一个高可用、强一致性的服务发现存储仓库。用于配置共享和服务发现。
它作为一个受到 Zookeeper 和 doozer 启发而催生的项目。除了拥有他们的所有功能之外,还拥有以下 4 个特点:
四层服务发现
先一张图解释一下网络七层协议:
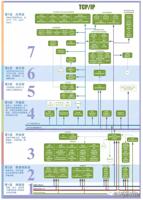
k8s 提供了两种方式进行服务发现:
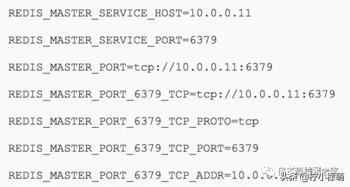
以上两种方式,一个是基于 TCP,DNS 基于 UDP,它们都是建立在四层协议之上。
五种 Pod 共享资源
Pod 是 k8s 最基本的操作单元,包含一个或多个紧密相关的容器。
一个 Pod 可以被一个容器化的环境看作应用层的“逻辑宿主机”;一个 Pod 中的多个容器应用通常是紧密耦合的,Pod 在 Node 上被创建、启动或者销毁;每个 Pod 里运行着一个特殊的被称之为 Volume 挂载卷,因此他们之间通信和数据交换更为高效。在设计时我们可以充分利用这一特性将一组密切相关的服务进程放入同一个 Pod 中。
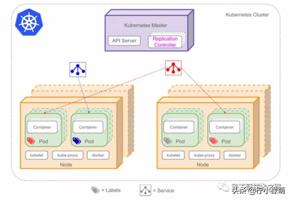
同一个 Pod 里的容器之间仅需通过 localhost 就能互相通信。
一个 Pod 中的应用容器共享五种资源:
Pod 的生命周期通过 Replication Controller 来管理;通过模板进行定义,然后分配到一个 Node 上运行,在 Pod 所包含容器运行结束后,Pod 结束。
Kubernetes 为 Pod 设计了一套独特的网络配置,包括为每个 Pod 分配一个IP地址,使用 Pod 名作为容器间通信的主机名等。
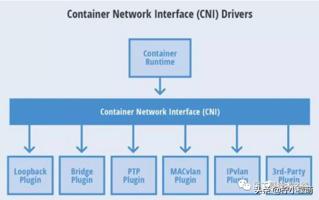
六个 CNI 常用插件
CNI(Container Network Interface)容器网络接口是 Linux 容器网络配置的一组标准和库,用户需要根据这些标准和库来开发自己的容器网络插件。CNI 只专注解决容器网络连接和容器销毁时的资源释放,提供一套框架。所以 CNI 可以支持大量不同的网络模式,并且容易实现。
下面用一张图表示六个 CNI 常用插件:
提负载均衡就不得不先提服务器之间的通信。
IDC(Internet Data Center)也可称数据中心、机房,用来放置服务器。IDC 网络是服务器间通信的桥梁。
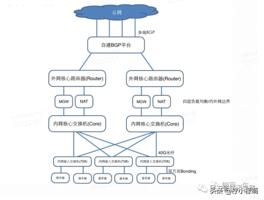
上图里画了很多网络设备,它们都是干啥用的呢?
路由器、交换机、MGW/NAT 都是网络设备,按照性能、内外网划分不同的角色。
先说说各层负载均衡:
这里用一张图来说说四层和七层负载均衡的区别:
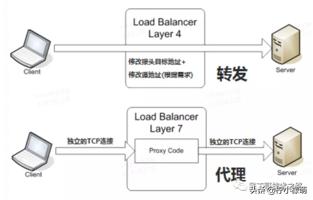
上面四层服务发现讲的主要是 k8s 原生的 kube-proxy 方式。k8s 关于服务的暴露主要是通过 NodePort 方式,通过绑定 minion 主机的某个端口,然后进行 Pod 的请求转发和负载均衡,但这种方式有下面的缺陷:
理想的方式是通过一个外部的负载均衡器,绑定固定的端口,比如 80;然后根据域名或者服务名向后面的 Service IP 转发。
Nginx 很好的解决了这个需求,但问题是如果有的新的服务加入,如何去修改并且加载这些 Nginx 配置?
Kubernetes 给出的方案就是 Ingress。这是一个基于七层的方案。
八种隔离维度
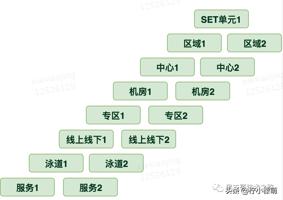
k8s 集群调度这边需要对上面从上到下、从粗粒度到细粒度的隔离做相应的调度策略。
九个网络模型原则
k8s 网络模型要符合四个基础原则、三个网络要求原则、一个架构原则、一个 IP 原则。
每个 Pod 都拥有一个独立的 IP 地址,而且假定所有 Pod 都在一个可以直接连通的、扁平的网络空间中,不管是否运行在同一 Node 上都可以通过 Pod 的 IP 来访问。
k8s 中的 Pod 的 IP 是最小粒度 IP。同一个 Pod 内所有的容器共享一个网络堆栈,该模型称为 IP-per-Pod 模型。
IP-per-Pod 模型从端口分配、域名解析、服务发现、负载均衡、应用配置等角度看,Pod 可以看做是一台独立的虚拟机或物理机。
要符合下面的架构:
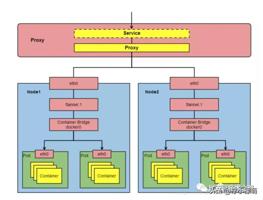
由上图架构引申出来 IP 概念从集群外部到集群内部:

十类IP地址
大家都知道 IP 地址分为 ABCDE 类,另外还有五类特殊用途的 IP。
第一类
A 类:1.0.0.0-1226.255.255.255,默认子网掩码/8,即255.0.0.0。
B 类:128.0.0.0-191.255.255.255,默认子网掩码/16,即255.255.0.0。
C 类:192.0.0.0-223.255.255.255,默认子网掩码/24,即255.255.255.0。
D 类:224.0.0.0-239.255.255.255,一般用于组播。
E 类:240.0.0.0-255.255.255.255(其中255.255.255.255为全网广播地址)。E 类地址一般用于研究用途。
第二类
0.0.0.0
严格来说,0.0.0.0 已经不是一个真正意义上的 IP 地址了。它表示的是这样一个集合:所有不清楚的主机和目的网络。这里的不清楚是指在本机的路由表里没有特定条目指明如何到达。作为缺省路由。
127.0.0.1 本机地址。
第三类
224.0.0.1 组播地址。
如果你的主机开启了IRDP(internet路由发现,使用组播功能),那么你的主机路由表中应该有这样一条路由。
第四类
169.254.x.x
使用了 DHCP 功能自动获取了 IP 的主机,DHCP 服务器发生故障,或响应时间太长而超出了一个系统规定的时间,系统会为你分配这样一个 IP,代表网络不能正常运行。
第五类
10.xxx、172.16.x.x~172.31.x.x、192.168.x.x 私有地址。
大量用于企业内部。保留这样的地址是为了避免亦或是哪个接入公网时引起地址混乱。
以上就是关于gg修改器修改游戏是s还是h_gg修改器都能修改什么游戏的全部内容,希望对大家有帮助。

和平精英gg修改器中文官网,寻找和平精英最完美助手?试试gg修改器中文官网吧! 大小:16.39MB9,141人安装 作为一款当今最热门的游戏,和平精英拥有着庞大的粉丝群体。然而,游戏难度较高,许……
下载
王者gg游戏修改器,王者GG游戏修改器玩游戏的不二选择 大小:19.22MB9,740人安装 随着智能手机的普及,越来越多的人开始玩手游。而正是因为手游的便捷性和即时性,才……
下载
gg修改器老版本免root_gg修改器免费版 大小:4.62MB10,651人安装 大家好,今天小编为大家分享关于gg修改器老版本免root_gg修改器免费版的内容,赶快……
下载
gg修改器怎么下免root优化_gg修改器免root修改 大小:6.18MB10,522人安装 大家好,今天小编为大家分享关于gg修改器怎么下免root优化_gg修改器免root修改的内……
下载
gg修改器免root权限6_gg修改器免root权限版(附修改教程) 大小:15.97MB10,621人安装 大家好,今天小编为大家分享关于gg修改器免root权限6_gg修改器免root权限版(附修改……
下载
gg修改器可以root,GG修改器,你值得拥有! 大小:6.77MB9,578人安装 如果你是一个玩家,你是否为某些游戏中繁琐的操作而感到厌倦?如果你是游戏开发者,……
下载
gg修改器免root什么用,gg修改器免root的实用性 大小:19.89MB9,501人安装 近年来,越来越多的手机游戏的出现让人们的生活更加多彩。但有时,我们在玩手机游戏……
下载
gg修改器下载中文怎么用_Gg修改器怎么下载 大小:17.29MB10,713人安装 大家好,今天小编为大家分享关于gg修改器下载中文怎么用_Gg修改器怎么下载的内容,……
下载
gg游戏修改器怎么修改领主,gg游戏修改器:让你的领主战争变得更加刺激 大小:16.09MB9,483人安装 如果你是个玩家,那么你一定知道游戏中的一些限制和瓶颈。有时候,这些限制会让我们……
下载
gg修改器最新版本下载方法,GG修改器是电竞玩家的神器 大小:12.01MB9,445人安装 GG修改器是目前市场上最为受欢迎的游戏辅助工具之一,因其稳定性和各种功能而备受电……
下载