GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器找游戏物品代码_gg修改器怎么看物品代码的内容,赶快来一起来看看吧。

大数据和云原生时代,企业数据量迎来急剧增长、数据类型日益丰富多样,各类新兴业务对数据库的各项能力不断提出挑战。伴随云原生理念的广泛传播和真正落地,如何进一步整合云计算基础设施和数据库,推动数据库实现高可扩展、高度自动化、快速部署,以满足企业真实业务需要,已成为业界关注的重要方向。
火山引擎veDB 是一款全托管的云数据库,简单易用,兼容 MySQL、PG 和 MongoDB 等数据库引擎,业务代码几乎无需修改即可接入使用。据介绍,veDB 的架构遵循的是“分离”哲学,包括计算和存储的分离、日志和数据的分离、读写分离,因此veDB拥有敏捷灵活、性能和容量大、低成本、高可靠、高可用等优势。
火山引擎是字节跳动旗下的云服务平台,也是字节跳动最佳技术实践的对外输出窗口。本文将围绕 veDB(for MySQL)在字节内部遇到的各类挑战和解决方案,介绍企业级大规模数据库的演进历程。

veDB(for MySQL)介绍
veDB 整体架构呈现计算与存储分离的总体特征。以 veDB(for MySQL) 为例,其技术架构具有以下特点:
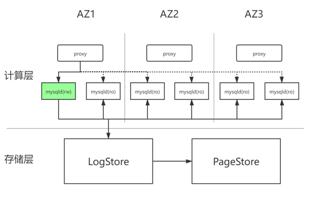
veDB 计算存储分离架构
完全兼容 MySQL :计算层基于 Percona Sever 8.0 版本打造,完全兼容字节线上的 MySQL 生态,字节的应用迁移到 veDB 上不需要任何改造;
计算存储分离:云原生架构,计算引擎能力和存储能力均可以独立扩展;
超大实例容量:数据库容量不受单机磁盘容量限制,存储层容量可以按需扩展;
只读线性扩展:添加只读节点无需拷贝数据,并且只读节点支持页面级别 REDO 并行回放技术,提供低读延迟(~10ms);
闪速备份恢复:存储层支持快照备份,通过 PITR 技术快速恢复至历史任意时间点。

开发历史
veDB(for MySQL) 具体的发展历程如下图所示:

目前,在字节跳动内部,veDB 已大规模接入线上业务,包括在国内预生产环境已完成了对 RDS MySQL 的全量替代,已接入国内生产环境 ~40% 的业务库,基本覆盖所有业务门类。预计到 2022 年底,veDB 将替代内部 RDS MySQL 约 80% 的国内业务,并使综合成本下降约 30%。同时,veDB 也已亮相字节跳动云服务平台火山引擎,对外提供 NewSQL 类 DBaaS 服务。
veDB(for MySQL)技术挑战
在构建 veDB(for MySQL)的过程中,团队遇到了以下三方面的技术挑战:
相比于本地的 NVME SSD 磁盘,计算存储分离架构会带来时延的增加;
在只读节点读延迟方面,如何做到比较低的读延迟;
由于业务会有各式各样的个性化诉求,需要对其个性化的数据进行优化。
对于这些技术问题,下面是一些针对性的解决方案。
如何克服时延挑战
虽然计算存储分离架构带来了一定的灵活性,但是相对于传统的单机主备架构,也带来了写日志和读页面的时延增加。具体来说,比如传统单机主备架构的读写时延大概是十微秒,但是计算存储分离架构由于经过一层网络 TCP/IP,时延大概是 1 毫秒左右,这会造成部分时延敏感性业务体验受损。
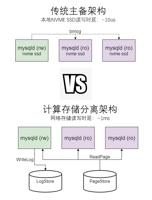
解决方案
针对上述问题,团队提出了以下三种解决方式:
共享内存写缓存/NVME SSD 读缓存:首先,Redo 日志在写入远端 Log Store 之前,会写入一个共享内存,然后再批量写入远端,这样做虽然类似于原生 MySQL 异步提交,但效率上要比异步提交高很多;其次,团队提供了二级读缓存的特性,虽然本地盘比较小,但是也有一部分存储空间,团队利用这部分存储空间来实施 Buffer Pool 的扩展,大大减少对远端 Page Store 的读取操作;
页面预取/计算下推:团队面对部分业务场景可以针对性地进行页面预取优化,提前从 Page Store 读取页面到缓冲区,可以避免在有需求时临时读取;
RDMA/AEP Store:这个其实类似于 PolarDB 读写 Polar FX ,但是 RDMA 部署会受到一些条件限制,团队目前是在有部署条件的场景下推行使用 RDMA 网络,并且结合 AEP Store 优化读写时延。
通过以上解决方案,总体而言,veDB(for MySQL)与本地 NVME SSD 磁盘相比,在延时敏感型业务体验上变化不大,在部分场景有更优表现,因为veDB去除了许多操作,比如不用刷脏页、没有 Checkpoint。
只读节点如何做到超低读延迟
什么是读延迟?主备架构中的主机写完数据之后,备机不能立刻读取数据,这其中的延迟被称为读延迟。
这其中面临的问题是什么呢?首先是传统的主备架构,比如 MySQL 基于 Binlog 同步,只读节点延时受业务负载影响比较大,虽然它在 v5.7 版本引入并行回放机制改善了读延迟,但是并没有完全克服问题;另外计算存储分离之后,团队并不是基于 Binglog 构造数据,而是基于 Redo 日志构造数据,那么 RO 节点如何同步数据呢?团队提供了以下技术解决方案。
解决方案
页面(Page)级别并行回放机制:首先只读节点启动后,veDB会基于最新快照,持续从共享存储去拉取物理日志并行解析回放,值得注意的是,veDB可以根据不同的规格选择不同的并行机制;
Redo 日志拉取(Pull)模式:这种模式下的计算节点读写,RW 节点和 RO 节点之间并没有直接的网络交互(如上图所示),只读节点从存储池拉取 Redo 日志;
Redo 日志推送(Push)模式:Push 模式是指在 RW 节点完成日志持久化之后,直接把 Redo 日志推到只读节点。

为什么会有 Pull 和 Push 两种模式呢?两种模式效果并不相同,在 Pull 模式下,veDB能够支持 30+ RO 节点,但此时读延时较高,大约在 100 毫秒左右。在 Push 模式下,veDB能够支持 15 个左右的 RO 节点,此时读延时较低,大约在 10 毫秒左右。
数据导入能力优化
对于如何更快从 MySQL 迁移数据,传统方式是 MySQL 本身支持 Dump、Restore, 或者第三方工具支持 Myloader Mydumper ,但由于存储计算分离,这种逻辑转换方式的性能表现并不佳。
解决方案
首先,考虑到 InnoDB 存储层物理页格式是一致的,veDB引入 Fastloader 工具直接把页面批量写入到存储层(Page store),其中,有些信息需要更新,比如 InnoDB 表的 Space ID 、索引的 ID 、 LSN等。同时,veDB目前支持 MySQL 5.6/5.7/8.0 去导入数据。
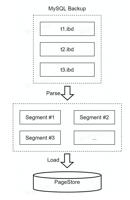
优化效果如何呢?总体而言,对于24G(1亿条)数据,用时从 1637s 降到 32s,性能提升了 51 倍;对于 69G(3 亿条)数据,用时从 21585s 降到 95s,性能提升了 227 倍。
大表DDL处理优化
原生 MySQL V8.0 版本支持 Instant 的 DDL 特性,虽然比较快,但是它适合的场景有限。另外,MySQL 备机回放 DDL 的 Binlog 时,它会引入一个较大的主备时延,只有 DDL 执行完成,它才能执行其它进程,这会造成较大的问题。目前各大互联网公司包主要运用两个第三方工具 Ghost 和 Pity online schema change ,来解决主备延时的问题,不过执行效率较低。尤其对veDB来说,存储计算分离之后,表变得更大,延时问题更加凸显。
解决方案
veDB引入了 FastDDL 来解决以上问题,具体而言:
主键索引(源表)页面预取:DDL 分为两个阶段,第一个阶段是对原表主键索引进行全表扫描,然后在这一阶段进行精准的页面预取;
并行构建(按索引,多机房):第二个阶段就是并行构建,比如按照索引并行构建,团队要重新构建表,其中包含 10 个索引,那么会有 10 个并发;同时,如果机房之间通过 Binlog 去同步,团队可以多机房一起执行;
存储层 Write-Through:veDB 架构的特点是 Log is Database。为了优化 DDL,团队直接写入 Page store,Bypass 了 Log store,起到一定的加速作用。
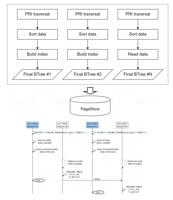
关于优化效果,主要有以下三点:
普适:基本上 MySQL 能够支持任何 Online DDL的操作;
快:它作为一个内部实现工具,是 gh-ost 速度的十分之一;
静:团队不引入 Binlog 主备延时,比如机房分别执行 DDL,等待它们执行差不多,最后 relay 就能完成。
复杂查询下推处理优化
在 MySQL 里面,复杂查询基本都是单线程执行,而单线程的任务一般比较重,包括解析、优化、数据读取和执行,计算存储分离会导致跨网络读取页面的时延大大增加。如果复杂查询出现 catch miss,即在缓冲区找不到数据,就需要从存储区拉取数据。这种情况频繁发生,性能会变差。另外,单库容量也大大增加了,数据容量从原来的几T 变成了现在的几十T,也加大了复杂查询的负担。
解决方案
计算操作(部分)直接下推存储层:当执行任务时,团队会去查询 B+ 数的倒数第二层节点,得到需要分发的页面 ID 情况,并且把任务并行分发给存储层;
并行任务分发:团队引入了并行执行查询算子, SQL 层完成分发之后,可以通过算子收集结果,汇聚并返回给计算层;
回表查询页面精准预取:对于回表查询,比如查完二级索引之后,需要去主键索引上查询,团队会做预取。
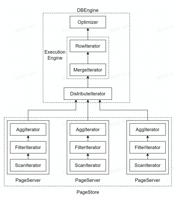
基于以上方案,veDB也取得了不错的效果。比如对于 count(*) 操作,在不增加计算层 CPU 负担的情况下,veDB实现了 5 倍 到 100 倍左右的提升;同时,以 TPCH (100G) 的数据集测试为例,对于缓冲区命中率低和命中率高的两种情况而言,从最坏到最好的情况,会有 2 倍到 10倍的提升。
秒杀场景优化
在类似于秒杀、限时抢购、抢红包等场景下,大量用户需要在极短时间内请求商品或者红包,此时数据库将面临单行记录大并发更新的老大难问题。通常,这会导致系统活跃线程增加、 TPS 降低、时延增加、系统吞吐降低。针对这种情况,目前有两种解决方案,其一是不依靠数据库,在应用层进行处理,但是这种方案较为复杂;其二就是依靠数据库来解决问题。
解决方案
SQL 语句更新列热点标识:对于带有热点更新标识的 SQL ,团队会在数据库内部维护一个哈希表,会将相同数据的 SQL 放在哈希表的一个队列里;
批量处理:经过一段时间之后,团队会针对队列里的 SQL 进行合并处理;
语法糖:为了更好地满足业务需求,veDB支持打开 Binlog ,以及语法糖,比如:Auto_Logic_Commit_Rollback hint,是指成功就自动提交,否则 Rollback;另外veDB扩展 Update..returning,支持语句返回。
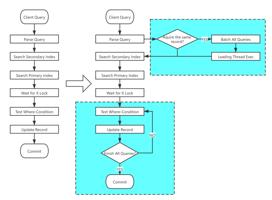
基于以上操作,实施效果如何呢?以一个 20c 的虚拟机为例,单行更新性能能够达到 9.3w QPS,多行更新性能能够达到 14.7w QPS。同时,团队目前已经上线了电商直播、抖音的本地生活,在业务直播带货过程中,即使热点商品 QPS 突然猛增到 1.5 万,veDB数据库也能够提供足够的支持。
计算引擎写能力如何扩缩容?
对于一写多读的架构,是如何做到多写呢?团队结合了字节内部的分库分表的中间件与 veDB,提供 Multimaster 支持。但是分库分表的 Multimaster 在写流量较大的场景时(例如 618 或双 11 活动)会面临集群扩容的问题,活动结束后又会面临集群缩容的问题。传统基于中间件的分库分表方案扩容需要复制数据,会面临两个问题:其一是耗时与数据量成正比,其二是还需要一倍的冗余空间,因此需要扩容。另外,分库分表目前没有一个有效的在线缩容方案,会导致在大型网络活动结束后,没有办法及时缩容。
解决方案
由于计算存储架构分离,数据都在存储层。veDB引入共享表的概念,共享表可以在不同的数据库实例之间进行共享,而不同的实例在 MySQL 都有相同的 space ID。同时,共享表的所有权(包括读和写)在任何时候都属于一个实例,它可以在实例之间动态切换,团队仅需要变更元数据的信息,无需移动数据。
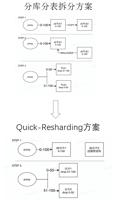
其实施效果如何呢?首先是扩容效果:假如分库分表有 1000 partitions,并且 1000 partitions 都在一个实例上,而要扩展成两个实例,此时扩容只需要在 1min 内就能完成 。这样做的好处是拆分过程与数据量无关,只需要提前准备好计算节点资源(虚机 或 容器),即可迅速完成拆分。其次是缩容效果:缩容的方式与扩容的方式是一致的,它也是变更元数据,因此缩容与扩容的效率基本相同。

veDB(for MySQL) 字节业务实践
首先来了解一下 veDB(for MySQL) 在字节的部署情况,主要包含高可用和高可靠两种部署方案。
高可用部署方案
目前 veDB (for MySQL)是三机房部署,对于高可用部署方案,团队分别在每个机房部署了存储池,如下图所示。第一个存储池用于存储 Redo 日志,第二个存储池用于存储 Binlog,第三个存储池是 Pagestore。
为什么要将 Redo 和 Binlog 分开存储?因为 Redo 的存储实现与 Binlog 不同,Redo 只需要存储两个小时,而 Binlog 需要存储一周左右,因此它们所需的容量是完全不同的。如果将二者都放入 SSD,会对 SSD 造成极大的容量负担,因此需要两个存储池。其次团队会在主机房(DC1)部署三个计算节点,在副机房(DC2、DC3)部署两个计算节点。DC1、 DC2 和 DC3 通过 Binlog 同步,但是在机房内是通过 Redo log 同步。
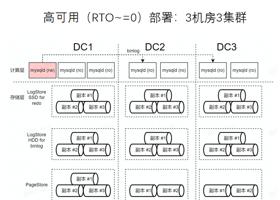
该部署方案的优点:一是保证最大服务可用性(RTO ~= 0),通过 Binlog 方式同步,无论哪一个机房出现问题,DC1 依旧可以提供服务;二是性能好/时延低,因为事务提交没有跨机房延迟,技术团队利用 RDMA + AEP Store 能够提供进一步加速。
该部署方案的缺点:比如跨机房不能保证 RPO=0、副机房只读节点的读延迟会较高。如上图所示,在 DC2 中,第一个只读节点的延迟是 Binlog 延迟,第二个只读节点的延迟是 Binlog 的延迟 + Redo log 的延迟。在主机房 DC1 中只有 Redo log 的延迟。
因此,该部署方案适用于对可用性和性能要求较高的业务场景,同时在极端情况下,比如机房整体故障,可能会损失失一点数据。
高可靠部署方案
该部署方案也可以被称为为三机房六副本,它是存储层跨机房部署,只包含两个存储池:LogStore SSD for redo&binlog,和 PageStore。由于它不需要依靠 Binlog 在机房间同步数据,所以可以不需要 Binlog 或者保留时间可以比较短,因此无需专门的 HDD 存储池来存储 Binlog。
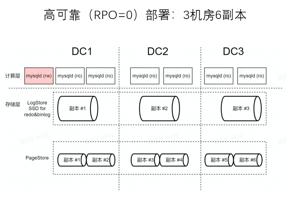
该部署方案的优点:一是保证最大数据可靠性:它依靠存储层通过 column 协议保证数据可靠,因此如果机房出现问题,其中的数据也不会消失;二是只读节点都延迟低:该方案中只有 Redo 日志延迟,比如 DC1 延迟是10毫秒左右,DC2 的延迟大概是 20毫秒左右。
该部署方案的缺点:一是性能相对较差:如果要保证 RPO = 0,事务性能相对会较差;二是时延相对较高:因为事务提交时需要写三副本或者两副本,这个过程中必然会存在跨机房的 RPC 延迟。
该部署方案适用于对数据可靠性要求比较高的业务,比如支付业务场景;同时它也适用于 QPS 不高,但是对备机读延迟敏感的业务。

典型业务实践
veDB(for MySQL) 主要被应用于以下四类业务实践:
小微库
该库的特点是数据量较小,QPS 较低。100% 预生产环境实例和部分生产环境实例都属于这类情况,使用 veDB 可以显著地提升资源利用效率。
历史库
该库的特点是数据量超大,QPS 较低,有复杂查询。钱包历史数据,财经历史数据都属于这类。以往的历史数据都是导出到 Hive 或者其它的分析系统,需要经过一个 ETL 过程。另外基于 MySQL 开发的一些应用,在 Hive 上需要重新开发。如果通过 veDB 来做历史库,就不会有以上问题,上层应用无需二次开发适应异构类型的历史库。
单体大库
单体库无法对分库分表进行拆分,该库的特点是数据量大,QPS 较高,时延较低。广告库和财经库都属于这类情况。此时,团队会通过 基于 RDMA 的 AEP Store 或者本地的二级读缓存,来应对该库的问题与挑战。
分片库
该库的特点是数据量超大,QPS 较高,时延较低,同时它能够分库。目前,团队上线了激励中台和 Ad-Hoc 节假日活动。

veDB(for MySQL)下一步发展方向
veDB目前往以下方向发展:
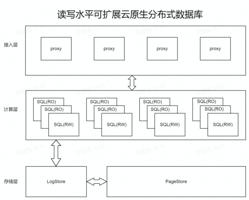
多写架构——Multi Master 2.0
Multi Master 2.0 的架构如下图所示,一共包含三层,分别是接入层、计算层、存储层。veDB主要提供了以下三方面的支持:
DDL :团队会提供一套完整的 DDL 语法(包括表、索引),之前采用分库分表的方式时,DDL 通常是通过DBA提交工单的方式去执行的,对外肯定是不行的;同时,也会提供 Online 操作,允许并发 DML;
增强分布式事务/查询:支持分布式一致性读/写,以及支持全局二级索引;
其它:还会进行一致性备份/恢复,融入 Quick Resharding。
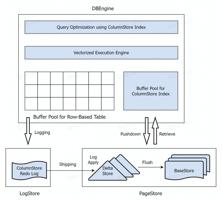
复杂查询:列存储索引和向量化引擎
MySQL 的查询能力是比较弱的,通常会把 MySQL 的数据导入到其它系统中去做查询,这会产生额外的部署成本。因此团队希望增强 MySQL 的查询能力,具体来说,会引入列存储索引、向量化引擎和一些其它的优化支持,以此来解决部分的 OLAP 场景需要的复杂查询能力。
内存优化表
在这个方向上,veDB主要提供了以下三方面的支持:
MM 事务引擎:MemTable 本质上是一个单独的存储引擎,独立于 InnoDB 之外,与 InnoDB 实现方式完全不同,但是能够达到 10 倍的 InnoDB 性能;另外,veDB提供了完整的 ACID 能力;
MM 存储引擎:深度融合了 RDMA/AEP,另外,日志和数据一体化;
编译执行:在 SQL 语句上执行了预编译优化,大幅减少了 CPU 执行指令数。
除了上述外,团队下一步还会在新硬件、无服务器方面对veDB进行迭代。新硬件方面,veDB会融合RDMA/AEP/DPU;无服务器方面,veDB会开展自主扩缩容、“自动驾驶”等。
目前, veDB 正对外开放邀测。点击“阅读原文”可访问火山引擎官网,企业注册账号即可联系工作人员,参与 veDB 邀测。
以上就是关于gg修改器找游戏物品代码_gg修改器怎么看物品代码的全部内容,希望对大家有帮助。
gg修改器ios中文版,GG修改器iOS中文版:让你的游戏生活更加丰富多彩! 大小:10.70MB9,565人安装 作为一名游戏爱好者,你是否曾经遇到过卡关、无法通过任务、被BOSS击败等等困扰?是……
下载
gg修改器中文怎么用,gg修改器中文怎么用 大小:4.88MB9,858人安装 GG修改器是一款备受玩家喜欢的游戏辅助工具,它可以帮助玩家在游戏中快速修改游戏数……
下载
gg修改器中文下载最新版无广告,gg修改器中文下载最新版无广告的神奇之处 大小:14.37MB10,046人安装 如果你是一位玩家,那么你必须想过要在游戏中卡住一些难点,或者获取一些游戏中的道……
下载
gg游戏修改器源,赞美gg游戏修改器源 大小:4.37MB9,539人安装 现代人对于游戏已经不单单是一种娱乐方式,更是一种生活方式。游戏开发者们不断推出……
下载
gg修改器 小米 root_gg修改器简洁版 大小:6.59MB10,788人安装 大家好,今天小编为大家分享关于gg修改器 小米 root_gg修改器简洁版的内容,赶快来……
下载
用gg修改器手机需要root吗,用gg修改器手机需要root吗? 大小:15.24MB9,855人安装 GG修改器手机版是一款功能强大的游戏辅助工具,它可以帮助玩家在游戏中获得更多的金……
下载
gg修改器(最新版),GG修改器,打破游戏限制的神器 大小:11.84MB9,873人安装 作为一位游戏爱好者,对于游戏本身的玩法、体验和挑战性都有着一定的追求。但有些时……
下载
gg大玩家最新版修改器,GG大玩家最新版修改器:游戏的必备神器 大小:4.08MB9,532人安装 在游戏中,往往需要花费大量的时间和精力才能升级,获取更多的装备和道具,这对于游……
下载
怎样使gg修改器免root,关键词:如何让GG修改器免Root 大小:13.15MB9,645人安装 如果你是一位游戏玩家,那么你一定知道游戏修改器在游戏中的作用。GG修改器无疑是最……
下载
gg修改器电脑版中文版_GG修改器电脑版 大小:9.62MB10,604人安装 大家好,今天小编为大家分享关于gg修改器电脑版中文版_GG修改器电脑版的内容,赶快……
下载