GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器暂停游戏进程_gg修改器怎么暂停游戏没用的内容,赶快来一起来看看吧。

开宗明义
现阶段,CPU与GPU搭配的异构计算组合仍然是AI算力中心的首选。在业界AI实际应用中,GPU硬件在业务弹性支撑能力、资金投入产出、能耗和IT架构等方面仍然痛点明显。
CPU和GPU的地位区别较大,一个是必需品,一个是加速器。CPU时刻都在运行,而GPU作为附加在计算机当中的设备(device),只有在需要时才被调用。因此,高效利用GPU资源的关键就在于按需调用、用完释放,且不用关心GPU资源够不够、从哪儿来。

GPU虚拟化 vs GPU池化
业界一直在对如何更优化地使用GPU资源进行探索。然而,大多数方案都没有解决上述最关键的问题。
这条不断探索的道路,可按技术突破分为简单虚拟化、任意虚拟化、远程调用和资源池化四个阶段。
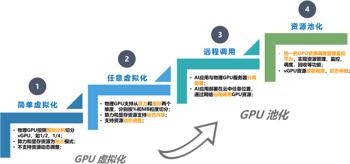
阶段一,简单虚拟化:将物理GPU按固定比例切分成多个虚拟GPU,比如1/2或1/4,每个虚拟GPU的显存相等,算力轮询。
阶段二,任意虚拟化:仍然是以单机GPU虚拟化为目标,但是通过一些技术手段支持物理GPU的从算力和显存两个维度灵活切分,实现自定义大小,满足AI应用差异化需求。
阶段三,远程调用:重要技术突破在于支持GPU的跨节点调用,AI应用可以部署到数据中心的任意位置,不管所在的节点上有没有GPU。在该阶段,资源纳管的范围从单个节点扩展到由网络互联起来的整个数据中心,是从GPU虚拟化向GPU资源池化进化的里程碑。
阶段四,资源池化:关键点在于按需调用,动态伸缩,用完释放。借助池化能力,AI应用可以根据负载需求调用任意大小的GPU,甚至可以聚合多个物理节点的GPU;在容器或虚机创建之后,仍然可以调整虚拟GPU的数量和大小;在AI应用停止的时候,立刻释放GPU资源回到整个GPU资源池,以便于资源高效流转,充分利用。
通过以上技术分析可见,传统的GPU虚拟化技术,或者叫GPU切片技术,基本上还是基于硬件的思维,只能对本地物理机上的GPU进行虚拟切割。而基于整个数据中心范围的GPU资源池化,不仅可以支持本地GPU虚拟化,而且还能打破单机资源调度的物理边界,让用户透明使用任意物理机上、任意数量的GPU资源,按需灵活调用,用完立即释放,极大地提升了昂贵GPU的利用率和业务的灵活度。

OrionX与其他开源方案的对比
在这条技术探索道路上,业界已经提出一些解决GPU共享问题的开源方案,接下来让我们从不同角度来探究这些方案的利弊。
1、基础架构对比
开源方案解决的是GPU共享问题,最多仅做到阶段二(任意虚拟化)。这类方案基本都是基于NVIDIA官方插件(NVIDIA/ K8S -device -plugin)进行改造,在保留官方功能的基础上,通过device-plugin插件对业务容器内注入vGPU配置参数,实现对GPU的显存和计算单元进行限制的目的,从而在一个物理GPU上模拟出多张小的vGPU卡。在K8S集群中,采用扩展调度器(Scheduler)对这些切分后的vGPU进行调度,使不同的容器可以共享同一张物理GPU,提高GPU的利用率。
由此,我们可以看到,这类方案①仅支持K8S平台,②仅单机虚拟化。
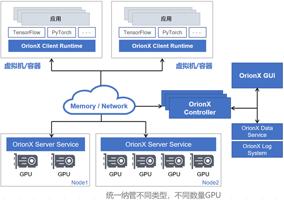
趋动科技OrionX AI算力资源池化解决方案已经实现了GPU资源池化,即阶段四。它在软件架构上采用数据面+控制面结合的方式——数据面包括OrionX Client Runtime(即AI应用或用户进程)与OrionX Server Service(即接管GPU之后将GPU虚拟化抽象)两个组件,两者之间交换计算信令,一个Client可以与本机的Server通信,也可以与远端的Server通信,甚至可以同时与多个Server通信,通信的过程其实就是调用GPU计算的过程。如此一来,从OrionX Client的视角看到的就是一个大资源池,任一Client都可以实现前面所说的按需灵活调用的效果。
控制面包括OrionX Controller和OrionX GUI两个组件,用于与前面的Client和Server交换控制信令,达到分配、调度并管理整个集群内部所有GPU资源的目的。
由此,我们可以看到:①OrionX AI算力资源池化解决方案的这套架构不仅可以支持K8S,还能全面支持KVM及物理机,适用范围更广。②突破了传统GPU虚拟化技术只能支持单机GPU共享的限制,融合了GPU共享、聚合和远程使用等多种能力,打造全能型软件定义GPU。
2、安全性对比
开源方案采用的是CUDA调用拦截。通常情况下,用户的AI应用程序会调用CUDA API,进而调用GPU硬件进行并行计算。libcuda.so 是用户态下最终会被调用的Driver API 库,它的接口公开但是实现细节闭源。开源方案实现了一个类似的动态库,例如libvendor-cuda.so ,劫持了应用程序对CUDA Driver API的调用,并且把调用转发给真实的GPU原厂的libcuda.so。在转发的过程中,绝大部分的API可以直接透传,而对少量API进行流控和修改。具体如下图所示:
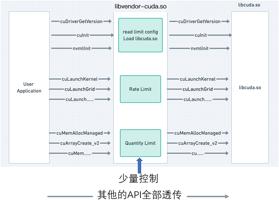
为了实现这样的效果,这类开源方案的左、中、右三层必须处在同一个容器内部,而且访问权限一致。那么,问题来了,由于处在同一容器,用户是完全有可能绕过中间的限制,去直接触达原生CUDA的,进而霸占整个物理GPU。这个行为不一定是高深的黑客技术,也许用户只是出于业务需要,从外面挂载一个libcuda.so文件,或者只是重定向一下链接库的路径,比如:export LD_LIBRARY_PATH等。然后,开源方案所谓的“限制”、“隔离”、“共享”就瞬间破防了。破防的后果显而易见,GPU原本是可以被多用户共享的,现在该用户可以肆意挤占其他用户的资源,其他用户的程序会因为资源不足而报错(比如OOM)。
OrionX AI算力资源池化解决方案同样有CUDA调用拦截,但是相较于开源方案,由于采用了C/S架构(OrionX Client Runtime与OrionX Server Service),它将用户应用与底层原生的CUDA分别封装在了两个进程空间内。首先,这从根源上杜绝了用户直接触达原生CUDA的可能性,因为他们分属在两个不同的进程空间中。其次,OrionX对GPU进行虚拟化抽象,且细粒度切分与供给是在Server端进行的,OrionX Server实时与控制端OrionX Controller保持心跳,全方位监控所有OrionX Client端的行为,任何非法的操作都会被拒绝。所以,用户的任何行为仅仅只在自己所在的进程空间生效,他做的任何篡改行为都是无效的,资源的分配还是按OrionX AI算力资源池化解决方案的既定逻辑执行。篡改行为最恶劣的后果就是自己的程序出错、无法运行,其他用户压根不受影响。因此,OrionX的安全性是其他方案无法比拟的。
3、资源复用对比
共享方案最直接的目的就是提高GPU的利用率,实现降本增效。利用率的提高,除了把物理GPU切分成更细小的虚拟GPU外,还有更重要的一点就是资源的动态释放。如果虚拟GPU分配出去之后依然是被独占的,哪怕AI业务处于闲置状态也无法动态释放资源,那么GPU利用率的提升是很有限的。
具体来看一下开源方案,在前文<基础架构>中,我们介绍过,这类方案是通过device-plugin插件对业务容器内注入vGPU配置参数的形式来定义这个业务用多少GPU资源的。那么这个注入的动作是要在容器运行前就进行的,换句话说就是容器一启动,这个vGPU就要被挂载进去。容器启动之后就依靠里面的libvcuda.so进行资源限制,device-plugin就不再介入容器的运行了。因此,可以看到挂载进去的这个vGPU是一个“静态”的形式,既不能动态调节它的大小,也不能动态释放资源,直到这个容器消亡。
OrionX AI算力资源池化解决方案刚好克服了这些缺陷。由于提供算力分配与供给的是OrionX Server Service这个组件,它既能分配,也能回收。OrionX Server可以根据业务需求提供“静态”与“动态”两种分配形式。
所谓“动态”,就是在这个容器的生命周期当中,虚拟GPU是可以被调节大小与数量的,一旦任务运行结束(CUDA指令发送完成),那么被占用的虚拟GPU资源立即释放。这是由于OrionX Server与OrionX Client保持数据面的通信,会实时感知来自OrionX Client的需求变化、任务启动等动作,并给出相应反馈。通过这些动态的特性,GPU资源可以更加高效地流转,实现GPU用完立即释放。

写在最后
OrionX AI算力资源池化解决方案完全支持裸机、虚拟机、容器以及K8S等多种环境的完整的资源池化,支持CPU和GPU解耦、弹性适配、按需调用,是一套完善的企业级GPU池化解决方案,站在整个数据中心的高度解决GPU利用率低、成本高、分配与管理难等问题。这一套方案与开源方案不在同一维度,其技术优势及安全性远不是基于容器的开源方案通过K8S的2个插件做到卡的切分就能比肩的。
以上就是关于gg修改器暂停游戏进程_gg修改器怎么暂停游戏没用的全部内容,希望对大家有帮助。

gg游戏修改器百晓生,神器出世gg游戏修改器百晓生 大小:15.67MB9,645人安装 游戏中的一些关卡或者任务让玩家感到棘手、难以完成,甚至会让人因此而放弃游戏。但……
下载
gg免root修改器有吗_gg修改器免root版使用 大小:18.63MB10,659人安装 大家好,今天小编为大家分享关于gg免root修改器有吗_gg修改器免root版使用的内容,……
下载
gg修改器改蹲地辅助最新版,介绍GG修改器改蹲地辅助最新版 大小:8.59MB9,626人安装 GG修改器改蹲地辅助最新版是一款针对游戏中蹲地操作的修改器,帮助玩家快速改变蹲地……
下载
gg修改器中的root什么意思_gg修改root,是什么意思 大小:9.87MB10,533人安装 大家好,今天小编为大家分享关于gg修改器中的root什么意思_gg修改root,是什么意思的……
下载
gg修改器root怎么用,探究gg修改器root的神奇功能 大小:16.86MB9,490人安装 在游戏玩家中,有种现象被称为“瞎子打野”,指的是游戏玩家因为对游戏角色的技能不了……
下载
安卓最新版gg修改器怎么用,安卓最新版gg修改器怎么用 大小:11.04MB9,756人安装 安卓最新版gg修改器是一款十分好用的手机游戏辅助工具,它能够帮助用户在手机游戏中……
下载
我的勇者gg修改器版最新,我的勇者gg修改器版最新:突破极限,无尽欢乐! 大小:6.50MB9,635人安装 谁说游戏只是一个消遣娱乐的方式?在我看来,它更是一种享受与挑战,更是一种测试自……
下载
最新gg修改器怎么下载教程,最新gg修改器怎么下载教程 大小:10.88MB9,545人安装 如果你是一个玩游戏的人,那么你肯定会对游戏中的一些难关感到十分困惑和烦躁。有时……
下载
gg修改器最新版使用教程,GG修改器最新版使用教程 大小:19.43MB9,813人安装 GG修改器是一个功能强大的游戏修改工具,可以帮助玩家修改游戏中的各种参数,让游戏……
下载
gg修改器与root_gg修改器与脚本整合 大小:9.80MB10,748人安装 大家好,今天小编为大家分享关于gg修改器与root_gg修改器与脚本整合的内容,赶快来……
下载