GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器数据溢出游戏崩溃_gg修改器改数据游戏崩溃的内容,赶快来一起来看看吧。
线上排查、性能优化等概念也是面试过程中的“常客”,而对于线上遇到的“疑难杂症”,需要通过理性的思维去分析问题、排查问题、定位问题、解决问题,同时,如果解决掉所遇到的问题或瓶颈后,也可以在能力范围之内尝试最优解以及适当考虑拓展性。
在本章中会先讲明线上排查问题的思路,再接着会对于JVM常用的排查工具进行阐述,最后会对于JVM线上常遇的一些故障问题进行全面剖析。
在开发过程中,如果遇到JVM问题时,通常都有各种各样的本地可视化工具支持查看。但开发环境中编写出的程序迟早会被部署在生产环境的服务器上,而线上环境偶尔也容易遇到一些突发状况,比如JVM在线上环境往往会出现以下几个问题:
当程序在线上环境发生故障时,就不比开发环境那样,可以通过可视化工具监控、调试,线上环境往往会“恶劣”很多,那当遇到这类问题时又该如何处理呢?首先在碰到这类故障问题时,得具备良好的排查思路,再建立在理论知识的基础上,通过经验+数据的支持依次分析后加以解决。
相对而言,解决故障问题也好,处理性能瓶颈也罢,通常思路大致都是相同的,步骤如下:
当然,上述过程是针对特殊问题以及经验老道的开发者而言的,作为“新时代的程序构建者”,那当然得学会合理使用工具来帮助我们快速解决问题:
前面给出了两套解决问题的步骤,面试/学习推荐前者,实际开发推荐后者,毕竟面试的时候人家问你怎么解决问题的,你总不能说靠百度。
同时还有关键一点要明白:“能够搜索出来的资料也是人写出来的,你为何不能成为写的那人呢”。
通常情况下来说,系统部署在线上出现故障,经过分析排查后,最终诱发问题的根本原因无非在于如下几点:
万变不离其宗,虽然上述中没有将所有可能会发生问题的位置写到,但总的来说,发生问题排查时,也就是这几个大的方向,先将发生问题的大体定位,然后再逐步推导出具体问题的位置,从而加以解决。
碰到问题时,首先要做的就是定位问题。而一般定位问题是都会基于数据来进行,比如:程序运行日志、异常堆栈信息、GC日志记录、线程快照文件、堆内存快照文件等。同时,数据的收集又离不开监控工具的辅助,所以当JVM在线上运行过程中出现问题后,自然避免不了使用一些JDK自带以及第三方提供的工具,如:jps、jstat、jstack、jmap、jhat、hprof、jinfo、arthas等,接下来我们逐个认识这些工具。
jps、jstat、jstack、jmap、jhat、jinfo等命令都是安装JDK后自带的工具,它们的功能主要是调用%JAVA_HOME%/lib/tools.jar包里面的Java方法来实现的,所以如果你想自己打造一个属于自己的JVM监控系统,那在Java程序内部调用该jar包的方法即可实现。
JDK官方提供的JDK工具参考文档,当然,如果你不会使用这些工具,也可以通过参数:tool -help来查看它的使用方法,如:jps -help。
PS:对于JDK提供的这些工具了解的可以直接跳到第三阶段。
jps工具的主要作用是用来查看机器上运行的Java进程,类似于Linux系统的ps -aux|grep java命令。jps工具也支持查看其他机器的Java进程,命令格式如下:
jps [ options ] [ hostid ]
查看指令的用法:jps -help
其中[options]主要有-q、-m、-l、-v、-V几个选项:
其中[hostid]是用来连接其他机器查看Java进程的远程ID。
JPS工具实际使用方式:jps [pid]。
jps工具主要用于实时查看JVM的运行参数,也可以在运行时动态的调整一些参数。命令格式如下:
jinfo [ option1 ] [ option2 ]
查看指令的用法:jinfo -help / jinfo -h
其中[option1]可选项如下:
其中[option2]可选项如下:
Jinfo工具实际使用方式:jinfo -flags [pid]。
PS:对于每个不同选项的效果就不再演示了,感兴趣的小伙伴可以自行在本地开个Java进程,然后使用上述的选项进行调试观察。
jstat工全称为“Java Virtual Machine statistics monitoring tool”,该工具可以利用JVM内建的指令对Java程序的资源以及性能进行实时的命令行的监控,监控范围包含:堆空间的各数据区、垃圾回收状况以及类的加载与卸载状态。
命令格式:jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]
其中每个参数的释义如下:
执行命令jstat -option后,可以看到存在很多选项,如下:
所以jstat的实际使用方式如下:
jstat -gc -t -h30 9895 1s 300
-gc:监控GC的状态
-t:显示系统运行的时间
-h30:间隔30行数据,输出一次表头
9895:Java进程ID
1s:时间间隔
300:本次输出的数据行数
最终执行效果如下:

统计列各字段含义如下:
|
字段名称 |
字段释义 |
|
Timestamp |
系统运行的时间 |
|
S0C |
第一个Survivor区的总容量大小 |
|
S1C |
第二个Survivor区的总容量大小 |
|
S0U |
第二个Survivor区的已使用大小 |
|
S1U |
第二个Survivor区的已使用大小 |
|
EC |
Eden区的总容量大小 |
|
EC |
Eden区的已使用大小 |
|
OC |
Old区的总容量大小 |
|
OU |
Old区的已使用大小 |
|
MC |
Metaspace区的总容量大小 |
|
MU |
Metaspace区的已使用大小 |
|
CCSC |
CompressedClassSpace空间的总大小 |
|
CCSU |
CompressedClassSpace空间的已用大小 |
|
YGC |
从程序启动到采样时,期间发生的新生代GC次数 |
|
YGCT |
从程序启动到采样时,期间新生代GC总耗时 |
|
FGC |
从程序启动到采样时,期间发生的年老代GC次数 |
|
FGCT |
从程序启动到采样时,期间年老代GC总耗时 |
|
GCT |
从程序启动到采样时,程序发生GC的总耗时 |
而除此之外,[options]指定其他选项时,也会出现不同的统计列字段,如下:
|
字段名称 |
字段释义 |
|
S0 |
第一个Survivor区的使用率(S0U/S0C) |
|
S1 |
第二个Survivor区的使用率(S1U/S1C) |
|
E |
Eden区的使用率(EU/EC) |
|
O |
Old区的使用率(OU/OC) |
|
M |
Metaspace区的使用率(MU/MC) |
|
CCS |
CompressedClassSpace区的使用率(CCSU/CCSC) |
|
NGCMN |
新生代空间初始容量 |
|
NGCMX |
新生代空间最大容量 |
|
S0CMN |
第一个Survivor区的初始容量 |
|
S0CMX |
第一个Survivor区的最大容量 |
|
S1CMN |
第二个Survivor区的初始容量 |
|
S1CMX |
第二个Survivor区的最大容量 |
|
OGCMN |
年老代空间初始容量 |
|
OGCMX |
年老代空间最大容量 |
|
MCMN |
元数据空间初始容量 |
|
MCMX |
元数据空间最大容量 |
|
CCSMN |
类压缩空间初始容量 |
|
CCSMX |
类压缩空间最大容量 |
|
TT |
对象晋升的最小年龄阈值 |
|
MTT |
对象晋升的最大年龄阈值 |
|
DSS |
期望的Survivor区总大小 |
CCS全称为“CompressedClassSpace”,主要是指存储类压缩指针的空间,具体可以看这个。
除开堆空间和GC相关的统计列信息之外,jstat工具还可以类加载与卸载的状态、监控JIT即时编译,执行jstat -class [pid]、jstat -compiler [pid]指令即可,效果如下:

类加载与卸载相关的监控数据统计列字段解读:
|
字段名称 |
字段释义 |
|
Loaded |
JVM已经装载的类数量 |
|
Bytes |
已装载的类占用字节数大小 |
|
Unloaded |
已经卸载的类数量 |
|
Bytes |
已卸载的类占用字节数大小 |
|
Time |
卸载和装载类共耗时 |
JIT即时编译相关的监控数据统计列字段解读:
|
字段名称 |
字段释义 |
|
Compiled |
编译任务执行的总次数 |
|
Failed |
编译任务执行失败的次数 |
|
Invalid |
编译任务执行失效的次数 |
|
Bytes |
已卸载的类占用字节数大小 |
|
Time |
所有编译任务的总耗时 |
|
FailedType |
最后一个编译失败的任务类型 |
|
FailedMethod |
最后一个编译失败的任务所在的类及方法 |
对于jstat工具执行不同指令后,每个统计列的含义都已在上述中解释清楚,如若之后在线上环境采用jstat工具排查性能瓶颈时,对于不理解的统计列皆可参考如上释义。
jmap是一个多功能的工具,主要是用于查看堆空间的使用情况,通常会配合jhat工具一起使用,它可以用于生成Java堆的Dump文件。但除此之外,也可以查看finalize队列、元数据空间的详细信息,Java堆中对象统计信息,如每个分区的使用率、当前装配的GC收集器等。
命令格式:> jmap [ option1 ] [ option2 ]
其中[option1]可选项有:
其中[option2]与jinfo工具的相差无几,可选项如下:
jmap工具实际使用方式:jmap -clstats [pid]或jmap -dump:live,format=b,file=Dump.phrof [pid]等。
堆快照导出命令解析:
live:导出堆中存活对象快照;format:指定输出格式;file:指定输出的文件名及其格式(.dat、.phrof等格式)。
当然,具体的每个选项的效果也不再演示,大家感兴趣可以自行调试后观测。
不过值得一提的是:大部分JDK提供的工具与JVM通信方式都是通过的Attach机制实现的,该机制可以针对目标JVM进程进行一些操作,比如获取内存Dump、线程Dump、类信息统计、动态加载Agent、动态设置JVM参数、打印JVM参数、获取系统属性等。有兴趣可以去深入研究一下,具体源码位置位于:com.sun.tools.attach包,里面存在一系列Attach机制相关的代码。
在最后对于histo选项做个简单调试,histo选项主要作用是打印堆空间中对象的统计信息,包括对象实例数、内存空间占用大小等。因为在histo:live前会进行FullGC,所以带上live只会统计存活对象。因此,不加live的堆大小要大于加live堆的大小(因为带live会强制触发一次FullGC),如下:
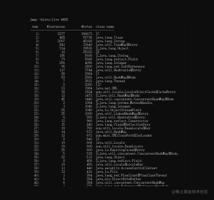
上图中,class name是对象的类型,但有些是缩写,对象的缩写类型与真实类型对比如下:
|
缩写类型 |
B |
C |
D |
F |
I |
J |
Z |
[ |
L+类型 |
|
真实类型 |
byte |
char |
double |
float |
int |
long |
boolean |
数组 |
其他对象 |
jhat工具一般配合jmap工具使用,主要用于分析jmap工具导出的Dump文件,其中也内嵌了一个微型的HTTP/HTML服务器,所以当jhat工具分析完Dump文件后,可以支持在浏览器中查看分析结果。
不过在线上环境中一般不会直接使用jhat工具对Dump文件进行解析,因为jhat解析Dump文件,尤其是大体积的Dump时,是一个非常耗时且占用硬件资源的过程。所以为了防止占用服务器过多的资源,通常都会将Dump文件copy到其他机器或本地中分析。
不过话说回来,到了本地一般也不会使用jhat,因为分析之后生成的结果通过浏览器观察时很难看,一般都会选择MAT(Eclipse Memory Analyzer)、IBM HeapAnalyzer、VisualVM、Jprofile等工具。
jhat命令格式:jhat [-stack <bool>] [-refs <bool>] [-port <port>] [-baseline <file>] [-debug <int>] [-version] [-h|-help] <file>
jhat的这条指令有点长,其中可以选择填写很多参数,释义如下:
jhat实际应用方式:jhat HeapDump.dat,效果如下:
> jmap -dump:live,format=b,file=HeapDump.dat 7452
Dumping heap to HeapDump.dat ...
Heap dump file created
> jhat HeapDump.dat
Reading from HeapDump.dat...
Dump file created Wed Mar 09 14:50:06 CST 2022
Snapshot read, resolving...
Resolving 7818 objects...
Chasing references, expect 1 dots.
Eliminating duplicate references.
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
复制代码
上述过程中,首先通过jmap工具导出了Java堆的内存dump文件,紧接着使用jhat工具对导出的dump文件进行分析,分析完成后可以打开浏览器,输入http://localhost:7000查看jhat分析后生成的结果,如下:

其中提供了不少选项,从上至下分别为:
其实本质上而言,jhat提供的浏览器界面也不怎么方便我们去排除问题。因此,实际分析堆Dump文件时,通常都会采用一些更为直观方便的工具,如:MAT、Jconsole、IBM HeapAnalyzer、visualVm等。
jstack工具主要用于捕捉JVM当前时刻的线程快照,线程快照是JVM中每条线程正在执行的方法堆栈集合。在线上情况时,生成线程快照文件可以用于定位线程出现长时间停顿的原因,如线程死锁、死循环、请求外部资源无响应等等原因导致的线程停顿。
当线程出现停顿时,可以通过jstack工具生成线程快照,从快照信息中能查看到Java程序内部每条线程的调用堆栈情况,从调用堆栈信息中就可以清晰明了的看出:发生停顿的线程目前在干什么,在等待什么资源等。
同时,当Java程序崩溃时,如果配置好了参数,生成了core文件,咱们也可以通过jstack工具从core文件中提取Java虚拟机栈相关的信息,从而进一步定位程序崩溃的原因。
jstack工具命令格式:jstack [-F] [option1] [option2]
其中[option1]可选项为:
其中[option2]可选项如下:
jstack工具实际使用方式:jstack -l [pid]。
同时,jstack工具的-F参数与jmap的作用相同,当正常执行失效时,加上-F可以强制执行jstack指令。
最后,jstack工具导出的Dump日志值得留意的状态:
|
状态 |
释义 |
|
Deadlock |
线程出现死锁 |
|
Runnable |
线程正在执行中 |
|
Waiting on condition |
线程等待资源 |
|
Waiting on monitor entry |
线程等待获取监视器锁 |
|
Suspended |
线程暂停 |
|
Object.wait()、TIMED_WAITING |
线程挂起 |
|
Blocked |
线程阻塞 |
|
Parked |
线程停止 |
上述分析的工具都是JDK自带的工具,每个不同的工具都拥有各自的作用,可以在不同维度对JVM运行时的状况进行监控,也能够帮助我们在线上环境时快速去定位排除问题。但除开JDK官方提供的一些工具之外,也有非常多第三方工具用起来非常顺手,如arthas、jprofilter、perfino、Yourkit、Perf4j、JProbe、MAT、Jconsole、visualVm等,这些工具往往都比前面分析提到的那些JDK工具更实用且功能更加强大。
程序上线后,线上遇到突发状况无疑是一件令人头疼的事情,但作为一位合格的开发者,不是仅会敲出一手流利的代码就足够了,线上排错这项技能也额外重要。但线上排错的能力强弱更取决于经验的丰富与否,丰富的实操经验与理论知识储备+理性的排错思路才是线上排查中最为重要的。
接下来会对线上环境中发生最为频繁的故障问题进行全方位剖析及实战,如JVM内存泄漏、内存溢出、业务线程死锁、应用程序异常宕机、线程阻塞/响应速度变慢、CPU利用率飙升或100% 等。
在排查问题时,诱发问题的原因也有可能来自于上下游系统。因此,当出现问题时,首先得定位出现问题的节点,然后针对该节点进行排错。但无论是哪个节点(Java应用、DB、上下游Java系统等),出现问题的原因无非就几个方向:代码、CPU、磁盘、内存以及网络问题,所以遇到线上问题时,合理采用OS与JVM提供的工具(如df、free、top、jstack、jmap、ps等),将这些方面依次排查一遍即可。
不过需要额外注意:JVM提供的大部分工具在使用时会影响性能,所以如果你的程序是以单机的模式部署,那最好在排查问题之前做好流量迁移(改DNS、Nginx配置等)。如果你的程序是以集群模式部署,那么可以将其中一台机器隔离出来,用于保留现场,也为了更方便的调试问题。
同时,如果线上的机器已经无法提供正常服务,那么在排查问题之前首先要做到的是“及时止损”,可以采用版本回滚、服务降级、重启应用等手段让当前节点恢复正常服务。
先来理解一下内存溢出:
举例:一个木桶只能装40L水,但此时往里面倒入50L水,多出来的水会从桶顶溢出。换到程序的内存中,这种情况就被称为内存溢出。
内存溢出(OOM)在线上排查中是一个比较常见的问题,同时在Java内存空间中,也会有多块区域会发生OOM问题,如堆空间、元空间、栈空间等,具体可参考前面的深入理解JVM运行时数据区这一章节。通常情况下,线上环境产生内存溢出的原因大致上有三类:
上述②③问题皆是由于编写的Java程序代码不严谨导致的OOM,由于Java内存中产生了大量垃圾对象,导致新对象没有空闲内存分配,从而产生的溢出。
在排查OOM问题时,核心是:哪里OOM了?为什么OOM了?怎么避免出现的OOM?
同时,在排查过程中,应当要建立在数据的分析之上,也就是指Dump数据。
获取堆Dump文件方式有两种:
①启动时设置-XX:HeapDumpPath,事先指定OOM出现时,自动导出Dump文件。
②重启并在程序运行一段时间后,通过工具导出,如前面的jmap或第三方工具。
模拟案例如下:
// JVM启动参数:-Xms64M -Xmx64M -XX:+HeapDumpOnOutOfMemoryError
// -XX:HeapDumpPath=/usr/local/java/java_code/java_log/Heap_OOM.hprof
public class OOM {
// 测试内存溢出的对象类
public static class OomObject{}
public static void main(String[] args){
List<OomObject> OOMlist = new ArrayList<>();
// 死循环:反复往集合中添加对象实例
for(;;){
OOMlist.add(new OomObject());
}
}
}
复制代码
在Linux上,先以后台运行的方式启动上述的Java程序:
root@localhost ~]# java -Xms64M -Xmx64M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/java/java_code/java_log/Heap_OOM.hprof OOM &
[1] 78645
复制代码
等待一段时间后,可以看到在/usr/local/java/java_code/java_log/目录下,已经自动导出了堆Dump文件,接下来我们只需要把这个Dump文件直接往Eclipse MAT(Memory Analyzer Tool)工具里面一丢,然后它就能自动帮你把OOM的原因分析出来,然后根据它分析的结果改善对应的代码即可。
其实上述这个案例中,你运行之后过一会儿就会给你输出一句OOM异常信息:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3210)
at java.util.Arrays.copyOf(Arrays.java:3181)
at java.util.ArrayList.grow(ArrayList.java:261)
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:235)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:227)
at java.util.ArrayList.add(ArrayList.java:458)
at OOM.main(OOM.java:13)
复制代码
在最后面都已经明确告诉了你,导致OOM的代码位置,因此这个案例没有太大的参考价值,其实也包括大部分他人的OOM排查过程,相对来说参考价值都并非太大,因为排查OOM问题时只需要自己具备理性的思维,步骤都大概相同的,所以接下来重点阐明排查OOM的思路即可。
线上OOM问题排查思路:
Java程序在线上出现问题需要排查时,内存溢出问题绝对是“常客”,但通常情况下,OOM大多是因为代码问题导致的,在程序中容易引发OOM的情况:
上述都是程序内代码引发OOM的几种原因,在线上遇到这类情况时,要做的就是定位问题代码,而后修复代码后重新上线即可。同时,除开代码诱发的OOM情况外,有时因为程序分配的内存过小也会引发OOM,这种情况是最好解决的,重新分配更大的内存空间就能解决问题。
不过Java程序中,堆空间、元空间、栈空间等区域都可能出现OOM问题,其中元空间的溢出大部分原因是由于分配空间不够导致的,当然,也不排除会存在“例外的类库”导致OOM。真正意义上的栈空间OOM在线上几乎很难遇见,所以实际线上环境中,堆空间OOM是最常见的,大部分需要排查OOM问题的时候,几乎都是堆空间发生了溢出。
先来理解一下内存泄漏:
举例:一个木桶只能装40L水,但此刻我往里面丢块2KG的金砖,那该水桶在之后的过程中,最多只能装38L的水。此时这种情况换到程序的内存中,就被称为内存泄漏。
PS:不考虑物体密度的情况,举例说明不要死磕!
内存泄漏和内存溢出两个概念之间,总让人有些混淆,但本质上是两个完全不同的问题。不过在发生内存溢出时,有可能是因为内存泄漏诱发的,但内存泄漏绝对不可能因为OOM引发。
线上的Java程序中,出现内存泄漏主要分为两种情况:
而一般在线上排查时并不能直接检测出内存泄漏问题,因为是否存在内存溢出问题除非监控了堆空间的对象变化,否则在正常情况下很难发觉。因此,通常情况下线上遇到泄漏问题时,都是伴随着OOM问题出现的,也就是:
排查OOM问题时,发现是由于内存泄漏一直在蚕食可用的空闲内存,最终导致新对象分配时没有空闲内存可用于分配,而造成的内存溢出。
内存溢出的模拟案例:
// JVM启动参数:-Xms64M -Xmx64M -XX:+HeapDumpOnOutOfMemoryError
// -XX:HeapDumpPath=/usr/local/java/java_code/java_log/Heap_MemoryLeak.hprof
// 如果不做限制,想要观测到内存泄漏导致OOM问题需要很长时间。
public class MemoryLeak {
// 长生命周期对象,静态类型的root节点
static List<Object> ROOT = new ArrayList<>();
public static void main(String[] args) {
// 不断创建新的对象,使用后不手动将其从容器中移除
for (int i = 0;i <= 999999999;i++) {
Object obj = new Object();
ROOT.add(obj);
obj = i;
}
}
}
复制代码
先启动该程序:
root@localhost ~]# java -Xms64M -Xmx64M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/java/java_code/java_log/Heap_MemoryLeak.hprof OOM &
[1] 78849
复制代码
等待片刻后,也会出现异常信息如下:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3210)
at java.util.Arrays.copyOf(Arrays.java:3181)
at java.util.ArrayList.grow(ArrayList.java:261)
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:235)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:227)
at java.util.ArrayList.add(ArrayList.java:458)
at MemoryLeak.main(MemoryLeak.java:14)
复制代码
乍一看,这跟之前分析的OOM问题没啥区别,但却并非如此。在Java程序中,理论上那些创建出来的Object对象在使用完成后,内存不足时,GC线程会将其回收,不过由于这些创建出来的对象在最后与静态的成员ROOT建立起了引用关系,而静态成员在JVM中又被作为GcRoots节点来对待的。
因此,所有创建出来的Object对象在使用完成后,因为与ROOT成员存在引用关系,所以都是可以通过根可达的对象,最终导致GC机制无法回收这些“无效”对象。
该案例中,从程序的执行结果来看,表象是内存溢出,但实则却是内存泄漏。
当然,上述案例只是简单模拟复现内存泄漏这种情况,实际开发过程中可能会更为复杂很多,如:
一个对象在某次业务逻辑执行过程中,与某个静态成员建立了连接,但该对象使用一次后不会再次使用,但因为没有手动去断开与静态成员的引用,因此导致这个“废弃对象”所占用的内存空间一直不会被GC回收。
所以,大家在开发编码过程中,应当刻意留意:当自己创建出的对象需要与静态对象建立连接,但使用一次之后明确清楚该对象不会再被使用,应当手动清空该对象与静态节点的引用,也就是手动置空或移除。如上述案例中,最后应该要ROOT.remove(obj)才可。
如果线上遇到因内存泄露而造成的OOM问题时,应当首先确认是堆内存泄漏,还是堆外内存泄漏,毕竟堆空间和元空间都有可能存在内存泄漏的隐患,搞清楚内存溢出的位置后再进行排查,处理问题会事半功倍。
常见的内存泄漏例子:
①外部临时连接对象使用后未合理关闭,如DB连接、Socket连接、文件IO流等。
②程序内新创建的对象与长生命周期对象建立引用使用完成后,未及时清理或断开连接,导致新对象一直存在着引用关系,GC无法回收。如:与静态对象、单例对象关联上了。
③申请堆外的直接内存使用完成后,未手动释放或清理内存,从而导致内存泄漏,如:通过魔法类Unsafe申请本地内存、或使用Buffer缓冲区后未清理等。
不过在理解内存泄漏时有个误区,大家千万不要被误导,先来看这么个说法:
“在Java中,多个非根对象之间相互引用,保持着存活状态,从而造成引用循环,导致GC机制无法回收该对象所占用的内存区域,从而造成了内存泄漏。”
上述这句话乍一听好像没太大问题,但实则该说法在Java中并不成立。因为Java中GC判断算法采用的是可达性分析算法,对于根不可达的对象都会判定为垃圾对象,会被统一回收。因此,就算在堆中有引用循环的情况出现,也不会引发内存泄漏问题。
死锁是指两个或两个以上的线程(或进程)在运行过程中,因为资源竞争而造成相互等待的现象,若无外力作用则不会解除等待状态,它们之间的执行都将无法继续下去。举个栗子:
某一天竹子和熊猫在森林里捡到一把玩具弓箭,竹子和熊猫都想玩,原本说好一人玩一次的来,但是后面竹子耍赖,想再玩一次,所以就把弓一直拿在自己手上,而本应该轮到熊猫玩的,所以熊猫跑去捡起了竹子前面刚刚射出去的箭,然后跑回来之后便发生了如下状况:
熊猫道:竹子,快把你手里的弓给我,该轮到我玩了…..
竹子说:不,你先把你手里的箭给我,我再玩一次就给你…..
最终导致熊猫等着竹子的弓,竹子等着熊猫的箭,双方都不肯退步,结果陷入僵局场面…….
这个情况在程序中发生时就被称为死锁状况,如果出现后则必须外力介入,然后破坏掉死锁状态后推进程序继续执行。如上述的案例中,此时就必须第三者介入,把“违反约定”的竹子手中的弓拿过去给熊猫,从而打破“僵局”。
上个简单例子感受一下死锁情景:
public class DeadLock implements Runnable {
public boolean flag = true;
// 静态成员属于class,是所有实例对象可共享的
private static Object o1 = new Object(), o2 = new Object();
public DeadLock(boolean flag){
this.flag = flag;
}
@Override
public void run() {
if (flag) {
synchronized (o1) {
System.out.println("线程:" + Thread.currentThread()
.getName() + "持有o1....");
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("线程:" + Thread.currentThread()
.getName() + "等待o2....");
synchronized (o2) {
System.out.println("true");
}
}
}
if (!flag) {
synchronized (o2) {
System.out.println("线程:" + Thread.currentThread()
.getName() + "持有o2....");
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("线程:" + Thread.currentThread()
.getName() + "等待o1....");
synchronized (o1) {
System.out.println("false");
}
}
}
}
public static void main(String[] args) {
Thread t1 = new Thread(new DeadLock(true),"T1");
Thread t2 = new Thread(new DeadLock(false),"T2");
// 因为线程调度是按时间片切换决定的,
// 所以先执行哪个线程是不确定的,也就代表着:
// 后面的t1.run()可能在t2.run()之前运行
t1.start();
t2.start();
}
}
复制代码
如上是一个简单的死锁案例,在该代码中:
执行结果如下:
D:> javac -encoding utf-8 DeadLock.java
D:> java DeadLock
线程:T1持有o1....
线程:T2持有o2....
线程:T2等待o1....
线程:T1等待o2....
复制代码
在上述案例中,实际上T1永远获取不到o1,而T2永远也获取不到o2,所以此时发生了死锁情况。那假设如果在线上我们并不清楚死锁是发生在那处代码呢?其实可以通过多种方式定位问题:
当然你也可以通过其他一些第三方工具排查问题,但前面方式都是JDK自带的工具,不过一般Java程序都是部署在Linux系统上,所以对于后面两种可视化工具则不太方便使用。因此,线上环境中,更多采用的是第一种jps+jstack方式排查。
接下来我们用jps+jstack的方式排查死锁,此时保持原先的cmd/shell窗口不关闭,再新开一个窗口,输入jps指令:
D:> jps
19552 Jps
2892 DeadLock
复制代码
jps作用是显示当前系统的Java进程情况及其进程ID,可以从上述结果中看出:ID为2892的进程是刚刚前面产生死锁的Java程序,此时我们可以拿着这个ID再通过jstack工具查看该进程的dump日志,如下:
D:> jstack -l 2892
复制代码
显示结果如下:
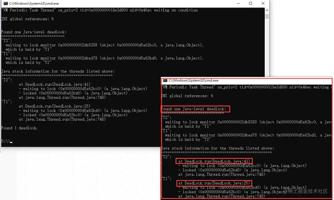
可以从dump日志中明显看出,jstack工具从该进程中检测到了一个死锁问题,是由线程名为T1、T2的线程引起的,而死锁问题的诱发原因可能是DeadLock.java:41、DeadLock.java:25行代码引起的。而到这一步之后其实就已经确定了死锁发生的位置,我们就可以跟进代码继续去排查程序中的问题,优化代码之后就可以确保死锁不再发生。
Java程序中的死锁问题通常都是由于代码不规范导致的,所以在排查死锁问题时,需要做的就是定位到引发死锁问题的具体代码,然后加以改进后重新上线即可。
Java应用被部署上线后,程序宕机情况在线上也不是个稀罕事,但程序宕机的原因可能是由于多方面引起的,如:机房环境因素、服务器本身硬件问题、系统内其他上下游节点引发的雪崩、Java应用自身导致(频繁GC、OOM、流量打崩等)、服务器中被植入木马或矿机脚本等情况,都有可能导致程序出现异常宕机问题。
处理这类宕机情况,由于原因的不确定性,这个问题更多的是由开发、运维和网安人员来协同解决的,我们需要做的就是能够保证出现情况时,确保程序可以立即重启且能够及时通知运维人员协助排错。所以这种情况下,你可以采用keepalived来解决该问题。
keepalived是个做热备、高可用不错的程序,大家可以自行安装一下,该程序的主要功能:可定期执行脚本、出现故障时给指定邮箱发送信件、主机宕机可以做漂移等,我们主要使用它的警报以及定期执行脚本功能。
安装keepalived完成后,可以使用vi命令编辑一下keeplived.conf文件,然后将其内部的监控脚本配置的模块改为如下:
vrrp_script chk_nginx_pid {
# 运行该脚本,脚本内容:Java程序宕机以后,自动开启服务
script "/usr/local/src/scripts/check_java_pid.sh"
interval 4 #检测时间间隔(4秒)
weight -20 #如果条件成立的话,则权重 -20
}
复制代码
check_java_pid.sh文件的脚本代码如下:
java_count=`ps -C java --no-header | wc -l`
if [ $java_count -eq 0 ];then
java /usr/local/java_code/HelloWorld
sleep 1
# 这个是用来做漂移的(不用管)
if [ `ps -C java --no-header | wc -l` -eq 0 ];then
/usr/local/src/keepalived/etc/rc.d/init.d/keepalived stop
fi
fi
复制代码
HelloWorld.java文件代码如下:
public class HelloWorld{
public static void main(String[] args){
System.out.println("hello,Java!");
for(;;){}
}
}
复制代码
上述的环境搭建完成后,可以测试效果,先启动一个Java应用HelloWorld:
# 启动Java应用
[root@localhost ~]# java /usr/local/java_code/HelloWorld
# 查看Java进程
[root@localhost ~]# ps aux | grep java
root 69992 0.1 0.7 153884 7968 ? SS 16:36 0:21 java
root 73835 0.0 0.0 112728 972 pts/0 S+ 16:37 0:00 grep --color=auto java
复制代码
然后再开启脚本执行权限并启动keeplived:
# 开启脚本执行权限(我的是root用户,这步其实可以省略)
[root@localhost ~]# chmod +x /usr/local/src/scripts/check_java_pid.sh
# 进入到keepalived安装目录并启动keepalived应用
[root@localhost ~]# cd /usr/local/src/keepalived/
[root@localhost keepalived]# keepalived-1.2.22/bin/keepalived etc/keepalived
# 查看keepalived后台进程
[root@localhost keepalived]# ps aux | grep keepalived
root 73908 0.0 0.1 42872 1044 ? Ss 17:01 0:00 keepalived
root 73909 0.0 0.1 42872 1900 ? S 17:01 0:00 keepalived
root 73910 0.0 0.1 42872 1272 ? S 17:01 0:00 keepalived
复制代码
前面所有程序都跑起来之后,现在手动默认Java应用宕机,也就是使用kill杀掉Java进程,如下:
# kill -9 69992:强杀Java进程(69992是前面启动Java应用时的进程ID)
[root@localhost ~]# kill -9 69992
# 查询Java后台进程(此时已经没有Java进程了,因为刚刚被kill了)
[root@localhost ~]# ps aux | grep java
root 76621 0.0 0.0 112728 972 pts/0 S+ 17:03 0:00 grep --color=auto java
# 间隔三秒左右再次查询Java后台进程
[root@localhost ~]# ps aux | grep java
root 79921 0.1 0.7 153884 7968 ? SS 17:08 0:21 java
root 80014 0.0 0.0 112728 972 pts/0 S+ 17:08 0:00 grep --color=auto java
复制代码
此时你可以观测到结果,本来被强杀的Java进程,过了几秒后再次查询,会发现后台的Java应用再次复活了!
keepalived是一个比较好用的工具,你还可以配置它的邮件提醒服务,当出现问题或重启时,都可以发送邮件给指定邮箱。但这种重启是治标不治本的手段,如果要彻底解决宕机的问题,还需要从根源点出发,从根本上解决掉导致程序宕机的原因。
响应速度变慢和线程出现阻塞,这两者之间的关系的密不可分的,Java服务中的线程由于执行过程中遇到突发状况导致阻塞,那么对于客户端而言,直接反馈过去的就是响应的速度变慢,所以线程阻塞时必然会造成客户端响应缓慢甚至无响应,但反过来,线程阻塞却不是造成响应速度变慢唯一原因。
响应速度变慢和Java应用宕机同样,属于“复合型”的问题,Java应用中线程阻塞、TCP连接爆满、SQL执行时间过长、硬件机器硬盘/CPU/内存资源紧张、上游系统流量过大、第三方中间件或接口出现异常情况、应用并非处理静态资源或同一时刻加载资源过多等情况都可能造成响应速度变慢,所以排查这类问题时,也是个靠经验来处理的问题。不过排查无响应或响应速度过慢问题时,也有规律可言:
上述两种其实可以理解为点和面的区别,一个是“全面”性质的,而另外一种则是“单点”性质的。除开可以从范围角度区分外,也可以从发生阶段的角度划分,如可分为:持续性响应缓慢、间接性响应缓慢、偶发性响应缓慢。
因为响应缓慢这个问题,诱发的原因有多种,所以在线上遇到这类情况时,理性的分析出问题诱发的原因,再在不同层面根据不同情况加以优化,如:多线程执行、异步回调通知、引入缓存中间件、MQ削峰填谷、读写分离、静态分离、集群部署、加入搜索引擎…….,都可被理解成是优化响应速度的方案。
CPU飙升100%和OOM内存溢出是Java面试中老生常谈的话题,CPU100%倒是个比较简单的线上问题,因为毕竟范围已经确定了,CPU100%就只会发生在程序所在的机器上,因此省去了确定问题范围的步骤,所以只需要在单台机器上定位具体的导致CPU飙升的进程,然后再排查问题加以解决即可。
模拟的Java案例代码如下:
public class CpuOverload {
public static void main(String[] args) {
// 启动十条休眠线程(模拟不活跃的线程)
for(int i = 1;i <= 10;i++){
new Thread(()->{
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(10*60*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
},"InactivityThread-"+i).start();
}
// 启动一条线程不断循环(模拟导致CPU飙升的线程)
new Thread(()->{
int i = 0;
for (;;) i++;
},"ActiveThread-Hot").start();
}
}
复制代码
首先新建一个shell-SSH窗口,启动该Java应用模拟CPU飙升的情景:
[root@localhost ~]# javac CpuOverload.java
[root@localhost ~]# java CpuOverload
复制代码
紧接着再在另外一个窗口中,通过top指令查看系统后台的进程状态:
[root@localhost ~]# top
top - 14:09:20 up 2 days, 16 min, 3 users, load average: 0.45, 0.15, 0.11
Tasks: 98 total, 1 running, 97 sleeping, 0 stopped, 0 zombie
%Cpu(s):100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 997956 total, 286560 free, 126120 used, 585276 buff/cache
KiB Swap: 2097148 total, 2096372 free, 776 used. 626532 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
77915 root 20 0 2249432 25708 11592 S 99.9 2.6 0:28.32 java
636 root 20 0 298936 6188 4836 S 0.3 0.6 3:39.52 vmtoolsd
1 root 20 0 46032 5956 3492 S 0.0 0.6 0:04.27 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.07 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:04.21 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.0 0.0 0:11.97 rcu_sched
.......
复制代码
从如上结果中不难发现,PID为77915的Java进程对CPU的占用率达到99.9%,此时就可以确定,机器的CPU利用率飙升是由于该Java应用引起的。
此时可以再通过top -Hp [PID]命令查看该Java进程中,CPU占用率最高的线程:
[root@localhost ~]# top -Hp 77915
.....省略系统资源相关的信息......
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
77935 root 20 0 2249432 26496 11560 R 99.9 2.7 3:43.95 java
77915 root 20 0 2249432 26496 11560 S 0.0 2.7 0:00.00 java
77916 root 20 0 2249432 26496 11560 S 0.0 2.7 0:00.08 java
77917 root 20 0 2249432 26496 11560 S 0.0 2.7 0:00.00 java
77918 root 20 0 2249432 26496 11560 S 0.0 2.7 0:00.00 java
77919 root 20 0 2249432 26496 11560 S 0.0 2.7 0:00.00 java
77920 root 20 0 2249432 26496 11560 S 0.0 2.7 0:00.00 java
77921 root 20 0 2249432 26496 11560 S 0.0 2.7 0:00.01 java
.......
复制代码
从top -Hp 77915命令的执行结果中可以看出:其他线程均为休眠状态,并未持有CPU资源,而PID为77935的线程对CPU资源的占用率却高达99.9%!
到此时,导致CPU利用率飙升的“罪魁祸首”已经浮现水面,此时先将该线程的PID转换为16进制的值,方便后续好进一步排查日志信息:
[root@localhost ~]# printf %x 77935
1306f
复制代码
到目前为止,咱们已经初步获得了“罪魁祸首”的编号,而后可以再通过前面分析过的jstack工具查看线程的堆栈信息,并通过刚刚拿到的16进制线程ID在其中搜索:
[root@localhost ~]# jstack 77915 | grep 1306f
"ActiveThread-Hot" #18 prio=5 os_prio=0 tid=0x00007f7444107800
nid=0x1306f runnable [0x00007f7432ade000]
复制代码
此时,从线程的执行栈信息中,可以明确看出:ID为1306f的线程,线程名为ActiveThread-Hot。同时,你也可以把线程栈信息导出,然后在日志中查看详细信息,如下:
[root@localhost ~]# jstack 77915 > java_log/thread_stack.log
[root@localhost ~]# vi java_log/thread_stack.log
-------------然后再按/,输入线程ID:1306f-------------
"ActiveThread-Hot" #18 prio=5 os_prio=0 tid=0x00007f7444107800
nid=0x1306f runnable [0x00007f7432ade000]
java.lang.Thread.State: RUNNABLE
at CpuOverload.lambda$main$1(CpuOverload.java:18)
at CpuOverload$Lambda$2/531885035.run(Unknown Source)
at java.lang.Thread.run(Thread.java:745)
复制代码
在线程栈的log日志中,对于线程名称、线程状态、以及该线程的哪行代码消耗的CPU资源最多,都在其中详细列出,接下来要做的就是根据定位到的代码,去Java应用中修正代码重新部署即可。
当然,如果执行jstack 77915 | grep 1306f命令后,出现的是““VM Thread” os_prio=0 tid=0x00007f871806e000 nid=0xa runnable”这类以“VM Thread”开头的信息,那么则代表这是JVM执行过程中,虚拟机自身的线程造成的,这种情况有需要进一步排查JVM自身的线程了,如GC线程、编译线程等。
CPU100%问题排查步骤几乎是死的模板:
CPU飙升这类问题,一般而言只会有几种原因:
①业务代码中存在问题,如死循环或大量递归等。
②Java应用中创建的线程过多,造成频繁的上下文切换,因而消耗CPU资源。
③虚拟机的线程频繁执行,如频繁GC、频繁编译等。
前面的内容中详细的阐述了线上的多种故障问题及其解决方案,但实则线上也同样还会出现各种各样的“毛病”,如磁盘使用率100%、DNS劫持、数据库被勒索、木马病毒入侵、矿机脚本植入、网络故障等等。同时,处理这些问题的手段都需要从经验中去积累,这也是开发者在工作中应当学习的 “宝贵财富”。
线上排查这项技能更多的是根据经验而谈的,经验越丰富的开发者遇到这类问题时,处理起来会更为得心应手,当线上排查的经验丰富后,就算遇到一些没碰到过的问题,也能排查一二,而不会茫然的束手无策。
总归而言,线上排查各类问题,没有所谓的千篇一律的方法可教,丰富的经验+强大的工具+理性的思维才是处理这类问题的唯一办法,但排查的思路却是不会变化的,步骤也大致相同,也既是开篇所提及到的:
分析问题、排查问题、定位问题、解决问题、尝试最优解。
以上就是关于gg修改器数据溢出游戏崩溃_gg修改器改数据游戏崩溃的全部内容,希望对大家有帮助。

gg修改器下载中文香肠派对_gg修改器修改香肠派对代码 大小:15.17MB10,536人安装 大家好,今天小编为大家分享关于gg修改器下载中文香肠派对_gg修改器修改香肠派对代……
下载
gg开罗游戏修改器下载,GG开罗游戏修改器下载,让游戏更加畅快体验 大小:11.22MB9,926人安装 游戏,在现代人的生活中扮演着重要的角色。无论是娱乐、放松还是挑战自我,游戏都能……
下载
gg修改器中文官网苹果版,GG修改器中文官网苹果版:专业修改游戏,为你赢得胜利 大小:5.81MB9,858人安装 如果你是一位游戏爱好者,那么一定会经常遇到游戏中遇到的各种问题,比如游戏中的种……
下载
gg修改器2022最新版下载,最新版GG修改器官方版下载 大小:4.82MB11,080人安装 最新版gg修改器是2022年推出的新版本,来自官方版修改汉化而来,小伙伴们可以轻松使……
下载
Gg修改器汉化版下载,gg修改器汉化版下载安装 大小:5.88MB10,983人安装 当你不能成就伟业,请你把握住平凡的幸福;当你不能让自己辉煌灿烂,请保持恒久的微……
下载
gg修改器中文下载新版_gg修改器下载中文最新版下载 大小:17.17MB10,675人安装 大家好,今天小编为大家分享关于gg修改器中文下载新版_gg修改器下载中文最新版下载……
下载
gg修改器修改中文内容,GG修改器助力中文内容创作的利器 大小:7.01MB10,017人安装 无论是从事网络写作还是游戏玩家,都深知一个事实,那就是修改器对于中文内容创作来……
下载
gg修改器如何改艾琳最新版,如何使用gg修改器改艾琳最新版? 大小:3.37MB9,786人安装 艾琳是一款非常受欢迎的游戏,但是有些玩家可能会发现游戏中存在的一些问题会影响到……
下载
gg大师修改器最新版下载,GG大师修改器最新版下载让你畅玩游戏 大小:4.92MB9,702人安装 GG大师修改器是一款非常实用的游戏辅助工具,它可以帮助玩家解决游戏中的烦恼,比如……
下载
gg游戏修改器皇室战争,gg游戏修改器皇室战争:打造全新战局的利器 大小:11.62MB9,802人安装 作为手游类王者之作,皇室战争一直以来都备受关注。而随着节奏和玩法的不断升级,为……
下载