GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器添加游戏地址_GG游戏修改器怎么使用的内容,赶快来一起来看看吧。
|
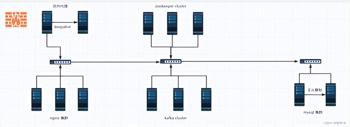
hostname |
ip |
|
web-nginx01 |
192.168.222.125 |
|
web-nginx02 |
192.168.222.126 |
|
web-nginx03 |
192.168.222.127 |
|
nginx-kafka01 |
192.168.222.134 |
|
nginx-kafka02 |
192.168.222.135 |
|
nginx-kafka03 |
192.168.222.136 |
|
zookeeper01 |
192.168.222.134 |
|
zookeeper02 |
192.168.222.135 |
|
zookeeper03 |
192.168.222.136 |
[root@nginx-kafka01 ~]# systemctl stop firewalld
[root@nginx-kafka01 ~]# systemctl disable firewalld
==============
# 关闭selinux
vim /etc/selinux/config
SELINUX=disabled
# 关闭selinux 需要重启服务器
# getenforce 查看是否生效
[root@nginx-kafka01 ~]# getenforce
Disabled
# 安装好epel源
yum install epel-release -y
yum install nginx -y
# 启动
systemctl start nginx
# 设置开机自启
systemctl enable nginx
[root@nginx-kafka01 opt]# vim /etc/nginx/nginx.conf
将
listen 80 default_server;
修改成:
listen 80;
[root@nginx-kafka01 opt]# vim /etc/nginx/conf.d/sc.conf
server {
listen 80 default_server;
server_name www.;
root /usr/share/nginx/html;
access_log /var/log/nginx/sc/access.log main;
location / {
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XeDBQbi9-1661781401038)(C:UserslenovoAppDataRoamingTypora ypora-user-imagesimage-20220822204847961.png)]
#语法检测
[root@nginx-kafka01 html]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: [emerg] open() "/var/log/nginx/sc/access.log" failed (2: No such file or directory)
nginx: configuration file /etc/nginx/nginx.conf test failed
[root@nginx-kafka01 html]# mkdir /var/log/nginx/sc
[root@nginx-kafka01 html]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
#重新加载nginx
nginx -s reload
安装java:yum install java wget -y
安装kafka: wget https://mirrors.bfsu./apache/kafka/2.8.1/kafka_2.12-2.8.1.tgz
解包: tar xf kafka_2.12-2.8.1.tgz
安装zookeeper:wget https://mirrors.bfsu./apache/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
[root@nginx-kafka01 kafka_2.12-2.8.1]# vim config/server.properties
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://nginx-kafka01:9092
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is ma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=192.168.222.134:2181,192.168.222.135:2181,192.168.222.136:2181
# 进入/opt/apache-zookeeper-3.6.3-bin/conf
[root@nginx-kafka01 conf]# cp zoo_sample.cfg zoo.cfg
# 修改zoo.cfg, t添加如下三行:
[root@nginx-kafka01 conf]# vim zoo.cfg
# 3888和4888都是端口 一个用于数据传输,一个用于检验存活性和选举
server.1=192.168.222.134:3888:4888
server.2=192.168.222.135:3888:4888
server.3=192.168.222.136:3888:4888
创建/tmp/zookeeper目录 ,在目录中添加myid文件,文件内容就是本机指定的zookeeper id内容
如:在192.168.222.134机器上
echo 1 > /tmp/zookeeper/myid
启动zookeeper:
bin/zkServer.sh start
开启zk和kafka的时候,一定是先启动zk,再启动kafka
关闭服务的时候,kafka先关闭,再关闭zk
[root@nginx-kafka03 apache-zookeeper-3.6.3-bin]# bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
bin/kafka-server-start.sh -daemon config/server.properties
# 创建topic
bin/kafka-topics.sh --create --zookeeper 192.168.0.95:2181 --replication-factor 1 --partitions 1 --topic sc
# 查看topic
bin/kafka-topics.sh --list --zookeeper 192.168.0.95:2181
# 创建生产者
[root@localhost kafka_2.12-2.8.0]# bin/kafka-console-producer.sh --broker-list 192.168.0.94:9092 --topic sc
>hello
>sanchuang tongle
>nihao
>world !!!!!!1
>
# 创建消费者
[root@localhost kafka_2.12-2.8.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.0.96:9092 --topic sc --from-beginning
bin/kafka-console-consumer.sh --bootstrap-server 192.168.222.134:9092 --topic nginxlog --from-beginning
[zk: localhost:2181(CONNECTED) 0] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /brokers
[ids, seqid, topics]
[zk: localhost:2181(CONNECTED) 2] ls /brokers/ids
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 3] get /brokers/ids
null
[zk: localhost:2181(CONNECTED) 4] get /brokers/ids/0
{
"listener_security_protocol_map":{
"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://nginx-kafka02:9092"],"jmx_port":9999,"features":{
},"host":"nginx-kafka02","timestamp":"1642300427923","port":9092,"version":5}
[zk: localhost:2181(CONNECTED) 5] ls /brokers/ids/0
[]
[zk: localhost:2181(CONNECTED) 6] get /brokers/ids/0
{
"listener_security_protocol_map":{
"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://nginx-kafka02:9092"],"jmx_port":9999,"features":{
},"host":"nginx-kafka02","timestamp":"1642300427923","port":9092,"version":5}
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
systemctl enable filebeat
# 修改配置文件/etc/filebeat/filebeat.yml
[root@nginx-kafka01 conf]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/sc/access.log
#--------------------kafka-------------------------
output.kafka:
hosts: ["192.168.222.134:9092","192.168.222.135:9092","192.168.222.136:9092"]
topic: nginxlog
keep_alive: 10s
bin/kaa-topics.sh --create --zookeeper 192.168.77.132:2181 --replication-factor 3 --partitions 1 --topic nginxlog
systemctl start filebeat
[root@nginx-kafka01 opt]# ps -ef |grep filebeat
root 5537 1 0 15:32 ? 00:00:08 /usr/share/filebeat/bin/filebeat --environment systemd -c /etc/filebeat/filebeat.yml --path.home /usr/share/filebeat --path.config /etc/filebeat --path.data /var/lib/filebeat --path.logs /var/log/filebeat
[root@nginx-kafka01 conf]# cd /var/lib/filebeat/registry/filebeat/
[root@nginx-kafka01 filebeat]# ls
log.json meta.json
[root@nginx-kafka01 filebeat]# less log.json
1、需求分析
需要nginx日志的ip,时间,带宽字段
将ip字段解析成相应的省份、运营商
存入数据库的字段: id, 时间, 省份, 运营商, 带宽
#步骤
1、创建数据表
2、编写python脚本, 从kafka获取nginx日志
3、获取好的nginx日志,提取出ip,时间,带宽字段
4、提取出的ip字段通过淘宝的一个接口解析出省份和运营商
url = "https://ip./outGetIpInfo?accessKey=alibaba-inc&ip=114.114.114.114"
5、格式化时间字段 "2021-10-12 12:00:00"
6、存入数据库
#创建表
create table nginxlog (
id int primary key auto_increment,
dt datetime not null,
prov int ,
isp int,
bd float
) CHARSET=utf8;
create table prov_index(
id int primary key auto_increment,
prov_name varchar(256)
) charset=utf8;
create table isp_index(
id int primary key auto_increment,
isp_name varchar(256)
) charset=utf8;
import json
import requests
import time
taobao_url = "https://ip./outGetIpInfo?accessKey=alibaba-inc&ip="
#查询ip地址的信息(省份和运营商isp),通过taobao网的接口
def resolv_ip(ip):
response = requests.get(taobao_url+ip)
if response.status_code == 200:
tmp_dict = json.loads(response.text)
prov = tmp_dict["data"]["region"]
isp = tmp_dict["data"]["isp"]
return prov,isp
return None,None
#将日志里读取的格式转换为我们指定的格式
def trans_time(dt):
#把字符串转成时间格式
timeArray = time.strptime(dt, "%d/%b/%Y:%H:%M:%S")
#timeStamp = int(time.mktime(timeArray))
#把时间格式转成字符串
new_time = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return new_time
#从kafka里获取数据,清洗为我们需要的ip,时间,带宽
from pykafka import KafkaClient
client = KafkaClient(hosts="192.168.222.134:9092,192.168.222.135:9092,192.168.222.136:9092")
topic = client.topics[’nginxlog’]
balanced_consumer = topic.get_balanced_consumer(
consumer_group=’testgroup’,
mit_enable=True,
managed=True
# zookeeper_connect=’nginx-kafka01:2181,nginx-kafka02:2181,nginx-kafka03:2181’
)
#consumer = topic.get_simple_consumer()
for message in balanced_consumer:
if message is not None:
line = json.loads(message.value.decode("utf-8"))
log = line["message"]
tmp_lst = log.split()
ip = tmp_lst[0]
dt = tmp_lst[3].replace("[","")
bt = tmp_lst[9]
dt = trans_time(dt)
prov, isp = resolv_ip(ip)
if prov and isp:
print(prov, isp,dt)
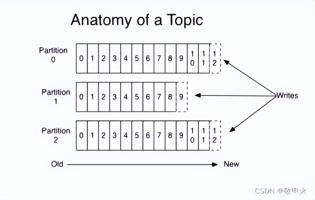
生产者生产的消息会不断追加到 .log文件的末尾, 为防止log文件过大导致数据定位效率低下 , kafka采用 分片 和 索引 的机制,将每个partition分为多个 segment ,每个segment对应 2 个文件, index文件和log文件
[root@nginx-kafka01 data]# cd nginxlog-0/
[root@nginx-kafka01 nginxlog-0]# ls
00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex 00000000000000000209.snapshot leader-epoch-checkpoint partition.metadata
[root@nginx-kafka01 nginxlog-0]# pwd
/data/nginxlog-0
[root@nginx-kafka01 nginxlog-0]#
index 和 log 的文件的文件名是当前这个索引是最小的数据的offset
kafka的topic分区的原因主要就是 提供并发,提高性能 ,因为读写是以partition为单位读写的
A . 在客户机中指定partition
B . 轮询 消息1去p1 , 消息2 去 p2 , 消息3 去 p3 , 消息4 去p1, 消息5 去 p2, 消息6 去 p3
保证生产者发送的数据,能可靠的发送到指定的topic, topic 的每个partition收到生产者发送的数据后, 都需要向生产者发送 ack (确认收到),如果生产者收到 ack ,就会进行下一轮的发送, 否则重新发送数据。
那么kafka什么时候向生产者发送ack
确保follower和leader同步完成,leader在发送ack给生产者,这样才能确保leader挂掉之后,能再follower中选举出新的leader后,数据不会丢失
那么多少个follower同步完成后发送ack
方案1: 半数已经完成同步, 就发送ack
方案2 :全部完成同步,才发送ack(kafka采用这种方式)

LEO :指每个follower的最大的offset
HW (高水位):消费者能看到的最大的offset,LSR队列中最小的LEO,也就是说消费者只能看到 1~ 6的数据,后面的数据看不到,也消费不了
避免leader挂掉后,比如当前消费者消费8这个数据后,leader挂 了, 此时比如 f2成为 leader, f2 根本就没有 9 这条数据,那么消费者就会报错,所以设计了 HW 这个参数, 只暴露最少的数据给消费者,避免上面的问题
A . Follower 故障
Follower发生故障后会被临时踢出LSR,待该follower恢复后,follower会读取本地的磁盘记录的上次的HW,并将该log文件高于HW的部分截取掉,从HW开始向leader进行同步,等该follower的LEO大于等于该Partition的hw,即follower追上leader后,就可以重新加入LSR
B . Leader 故障
Leader发生故障后,会从ISR中选出一个新的leader, 之后, 为了保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉(新leader自己不会截掉),然后从新的leader同步数据。
注意:这个是为了保证多个副本间的数据存储的一致性,并不能保证数据不丢失或者不重复
Ack设置为 -1,则可以保证数据不丢失,但是会出现数据重复(at least once)
Ack设置为0,则可以保证数据不重复,但是不能保证数据不丢失(at most once)
如何做到鱼和熊掌兼得呢? 引入了 Exactl one (精确一次)
如果启用幂等性,则ack默认就是 -1 ,kafka就从每个生产者分配一个pid,并为每条消息分配 seqnumber,如果pid, partition, seqnumber三者一样,则kafka认为是数据重复,就不会落盘保存;但是如果生产者挂掉后,也会出现有数据重复的现象;所以幂等性解决在单次会话的单个分区的数据重复,但是在分区间或者跨会话的数据重复 问题是无法解决的
kafka集群中有一个broker会被选举为controller,负责管理集群broker的上下线,所有的topic的分区 副本分配和leader选举等工作
确定消息的读写是在哪个replica上完成。
但是,为了保证较高的处理效率,消息的读写都是固定的一个副本上完成。这个副本就是所谓的leader,而其他副本则是follower。follower则会定期的到leader上同步数据。
假如某个分区所在的服务器出来问题, 不可用, kafka会从该分区的其他的副本中选择一个作为新的leader。之后所有的读写就会转移到这个新的leader上。现在的问题是应当选择哪个作为新的leader。显然,只有哪些根leader保持同步的follower才应该被选举为新的leader。
kafka会在Zookeeper上针对每个Topic维护一个称为ISR(in-sync replica, 已同步的副本)的集合,该集合中时一些分区的副本。只有当这些副本都跟leader中的副本同步了之后,kafka才会认为消息已提交,并反馈给消息的生产者。如果这个集合有增减,kafka会跟新zookeeper上的记录。
如果某个分区的leader不可用,kafka就会从ISR集合中选择一个副本作为新的leader
显然通过ISR,kafka需要的冗余度较低,可以容忍的失败数比较高。假设某个topic有 f+1 个副本。kafka可以容忍 f 个服务器不可用。
选择leader时也是从超过半数的同步的副本中选择
这种算法需要较高的冗余度
譬如只允许一台机器失败,需要有三个副本;而如果只容忍两台机器失败,则需要五个副本
多个broker + 多个partition + 多个 replica
ISR (in-sync-replica) 集合列表 需要同步的follower集合
比如说 5 个副本, 1个leader, 4个follower 都在ISR中
有一条消息来了, leader怎么知道要同步哪些副本呢?
根据ISR来,如果一个follower挂了。那就从这个列表里删除
如果一个follower卡住了或者同步过慢, 它也会从ISR里删除
eeper上的记录。
如果某个分区的leader不可用,kafka就会从ISR集合中选择一个副本作为新的leader
显然通过ISR,kafka需要的冗余度较低,可以容忍的失败数比较高。假设某个topic有 f+1 个副本。kafka可以容忍 f 个服务器不可用。
选择leader时也是从超过半数的同步的副本中选择
这种算法需要较高的冗余度
譬如只允许一台机器失败,需要有三个副本;而如果只容忍两台机器失败,则需要五个副本
多个broker + 多个partition + 多个 replica
ISR (in-sync-replica) 集合列表 需要同步的follower集合
比如说 5 个副本, 1个leader, 4个follower 都在ISR中
有一条消息来了, leader怎么知道要同步哪些副本呢?
根据ISR来,如果一个follower挂了。那就从这个列表里删除
如果一个follower卡住了或者同步过慢, 它也会从ISR里删除
以上就是关于gg修改器添加游戏地址_GG游戏修改器怎么使用的全部内容,希望对大家有帮助。
GG修改器免root版最新下载,GG修改器免root版 大小:4.59MB11,057人安装 人应该要为梦想追逐,不管现实给了你多少黑眼圈。勇敢的追求自己的梦想吧!早上好!……
下载
gg修改器中文版下载安卓_gg修改器官网下载安卓版最新版下载 大小:18.60MB10,775人安装 大家好,今天小编为大家分享关于gg修改器中文版下载安卓_gg修改器官网下载安卓版最……
下载
九黎最新gg修改器下载,九黎最新gg修改器下载:天才般的游戏辅助 大小:9.75MB9,758人安装 如果你是一名玩家,你一定知道九黎最新gg修改器下载。它是一个功能强大,易于使用的……
下载
gg修改器root过保护,掌握最强改游戏神器 gg修改器root过保护 大小:11.64MB9,706人安装 为什么很多玩家热衷于使用修改器?因为它可以为其游戏造成深刻的改变。gg修改器root……
下载
gg修改器中文官方文档, gg修改器:游戏玩家必备神器 大小:12.23MB9,661人安装 随着游戏越来越流行,玩家们对游戏的需求也越来越高。然而,游戏体验并不总是完美的……
下载
gg修改器暴走大侠,gg修改器修改暴走大侠代码 大小:18.03MB10,018人安装 1.画面很吸引人,而且游戏的广告打的非常不错,小伙伴们可以尽情的玩耍; 2.这款游戏……
下载
gg游戏修改器框架怎么下载,如何下载 gg游戏修改器框架? 大小:16.16MB9,845人安装 游戏修改器是一个非常实用的工具,它可以让玩家在游戏过程中修改游戏内部的数据,提……
下载
gg游戏修改器忍者必须死,不可缺少的工具:gg游戏修改器让忍者必须死更加精彩 大小:18.96MB9,860人安装 在玩游戏时,我们总是期待能够获得最好的游戏体验,让自己在游戏中能够更加过瘾。如……
下载
gg修改器最新免root版中文_gg修改器免root版下载中文 大小:3.88MB10,976人安装 大家好,今天小编为大家分享关于gg修改器最新免root版中文_gg修改器免root版下载中……
下载
GG虚拟空间游戏修改器下载,GG虚拟空间游戏修改器下载:一场游戏改变人生的体验 大小:11.50MB9,771人安装 在玩游戏的过程中,总会遇到一些棘手的问题,比如无法突破关卡、无法获得足够的资源……
下载