GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于如何检测游戏使用gg修改器_gg修改器如何不被手游检测的内容,赶快来一起来看看吧。
根据上一篇的讲述,我们选择了YOLOv3作为模型,那么本篇文章将继续接着上篇的内容,自己动手基于YOLOv3实现模型训练和mAP的计算。 在自己动手的这个过程中,一边解决遇到的问题,一边体会YOLOv3的原理,让我们学习起来吧。
YOLOv3使用参考官网教程:https:///darknet/yolo/
首先就是下载YOLOv3项目并安装了,如下:
git clone https:///pjreddie/darknet
cd darknet
make
接着就是下载YOLOv3已经提前训练好的一个模型体验下效果了:
wget https:///media/files/yolov3.weights
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
这个条命令运行后,可以看到在项目的安装目录下多了一个predictions.jpg的文件,这就是检查结果的图片。结果如图:

命令也输出了各个网络层的输入和输出,以及最后识别出多少个物体分类和属于这个分类的概率。如下图所示:
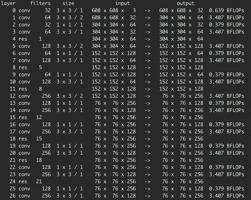
上图显示了卷积网络各层的计算过程,下图显示了整张图片检测的耗时,以及图中的物品类别和对应的概率。结果如图所示:
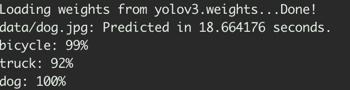
对着输出和结果图片,可以看到识别的准确率还是很高的,但是也相当耗时,耗费了18.66秒。YOLOv3提供了一个层数只有13层的tiny模型,识别速度会更快,下载体验下:
wget https:///media/files/yolov3-tiny.weights
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
识别结果如下:
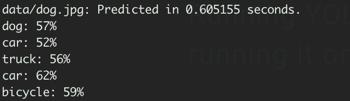
对于同样的图片,可以看到识别耗时从18.66秒直接降到了0.6秒,时间居然能下降97%,当然准确度也下降了。结果图片如图所示:

从结果中tiny的模型准确度可能的确不高,从图中能看出来把一辆truck识别成了2个car和一个truck的组合。
在体验了几次YOLOv3的检测效果后,开始思考如何才能训练自己的模型呢?很自然的想法是先按照YOLOv3开放的数据集做训练,跑通流程后再利用自己的数据集训练。接着就开始我们的第一步,利用开放的数据集进行训练。
首先使用在公开的VOC数据集上进行下验证,下载数据集:
wget https:///media/files/VOCtrainval_11-May-2012.tar
wget https:///media/files/VOCtrainval_06-Nov-2007.tar
wget https:///media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
下载完毕数据集后,我们还需要对转化数据集的标记格式为YOLOv3的标记方式,YOLOv3采用.txt文件来保存标记,格式如下:
<object-class> <x> <y> <width> <height>
其中object-class就是目标的种类index,x, y, width, height分别是图中目标的起始坐标和宽高。也就是之前提到的。
YOLOv3也提供一个脚本程序,将VOC数据转化并标记为YOLO格式的标记,我们需要下载转化程序并进行转化:
wget https:///media/files/voc_label.py
python3 voc_label.py
转化后,可以看到在项目目录下多了个VOCdevkit的文件夹,包含VOC2007,VOC2012,VOC2022 三个子文件夹,每个子文件夹格式如下:

Annotations保存了每个图片对应的xml标记文件,可以打开看看,内容还是很好理解的,定义了图片的地址,宽、高、包含的物品类别以及各个类别的坐标和宽高。JPEGImages里是图片文件,labels文件夹下的存放着每个图片对应的标记数据,比如:
19 0.482 0.4053333333333333 0.8280000000000001 0.752
表示第19类数据的坐标和宽高。但是这个第19类代表的是什么?后边的坐标信息和宽高信息和Annotations下的标记信息也不同啊,这是怎么回事?
答案就在voc_label.py文件里,打开这个文件,发现类别的定义如下:
classes = [“aeroplane”, “bicycle”, “bird”, “boat”, “bottle”, “bus”, “car”, “cat”, “chair”, “cow”, “diningtable”, “dog”, “horse”, “motorbike”, “person”, “pottedplant”, “sheep”, “sofa”, “train”, “tvmonitor”]
那么第19类就是tvmonitor, 接着往下阅读此文件,发现文件是从Annotations中读入xml文件,通过函数convert把原始图片的坐标和宽高转化为了labels里的坐标和宽高数据。阅读函数,发现这个过程其实是一个归一化的过程,把原始数据映射到[0, 1]区间内,并且把坐标点移动到了图片的几何中心。
数据格式化和归一化完成后,我们还需把训练集合并成一个较大的训练集,从而获得较好的训练结果,合并命令如下:
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
接着把合并结果移动到data/voc目录下:
mv train.txt data/voc
(3). 训练VOC数据
在完成上述的数据准备后,再调整下训练模型的data文件,打开cfg/voc.data:
classes = 20
train = <path-to-voc>/train.txt
valid = <path-to-voc>/2007_test.txt
names = data/voc.names
backup = backup
替换<path-to-voc>为自己存储文件地址即可。
最后,调整下训练参数文件cfg/yolov3-voc.cfg:
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=8
把训练的batch和subdivisions参数打开,关闭测试的batch和subdivisions参数。
batch表示是更新weights和bias的基本单位,可以这样理解每经过batch数量的样本训练后,更新一遍网络参数。
subdivisions表示网络中前向传播、反向传播的基本单位,也可理解为把整个batch分作几份训练,那么一次送入训练器的样本数量实际上是batch/subdivisions。
实际上网络是batch/subdivisions张图片进行训练(前向推理和反向传播),但是升级权值是在batch数目结束后进行的。这样在比较小的显存情况下实现大batch的训练。理论上batch越大,训练效果越好,但是batch太大内存可能吃不消。
在准备完备VOC训练数据后,在正式开始训练前还需要下载一个预训练文件:
wget https:///media/files/darknet53.conv.74
在完成这些后,终于可以开始训练了,利用以下命令开始VOC数据的训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
从程序输出中可以看到,程序在完成了网络加载后开始进行了训练过程,输出如下:

从训练程序的输出分为3类信息:
一些输出信息解释如下:
训练是按照yolov3-voc.cfg中的batch和subdivisions参数一组一组地读取图片训练,每组完成后输出下列信息:

其中内容说明如下:
训练过程很漫长,很漫长,很漫长(用天为单位计算)。
我发现有2个问题需要解决:
第一个问题,如何加速训练过程?
当然是利用GPU了,YOLOv3的Makefile中可以修改gpu和cudnn的参数,有GPU的同学可以修改这两个参数后make出新的darknet程序来进行训练。强烈建议用GPU参与训练,CPU训练可能要等死人的。没GPU的话,现在很多云服务厂商都有GPU的云主机,临时租用一个也划算。
备注:我使用的是Ubuntu 20.04,如何在Ubuntu 20.04下安装gpu驱动和cuda编程组件是另一个需要解决的问题。
第二个问题,训练过程数据可以可视化吗?
肯定是可以可视化的,我们需要考虑如何可视化。简单的想法是把训练过程的输出重定向到一个日志文件,然后通过程序对日志文件中的数据进行提取,再把提取的数据可视化出来。如何完成可视化过程,我们本次不做尝试,等到我们把开始自己训练数据后再做训练过程的可视化。
到此,我们已经能够利用VOC的数据训练YOLOv3了。训练结果保存在backup目录下,可以看到有很多形如xxx_100.weights, xxx_200.weights, xxx_300.weights, … , xxx_10000.weights的模型文件,和一个最终的yolov3-voc_final.weights的模型文件。
训练模型已经完成,我们再把cfg/yolov3-voc.cfg的训练batch和subdvisions参数修改回去,用来验证下模型效果。
[net]
#Testing
batch=1
subdvisions=1
#Trainning
batch=64
subdvisions=16
运行命令进行测试:
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_final.weights test.png
如果结果显示了物品的分类,并且在项目下有predictions.jpg文件生成,那么说明模型成功了。
根据前文的讨论,我们知道通过mAP这个数值来衡量模型的性能,现在的问题是我们有模型了(官方的模型),有数据集了(VOC数据集),就差计算mAP的过程了。可以通过如下命令验证模型:
./darknet detector valid cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_final.weights
整个过程花费了135秒,验证结束后会在results目录下生成每个类的验证数据文件。验证数据现在有了,剩下的就是基于验证数据计算mAP了,这个过程需要用到一个计算脚本,这个脚本名叫voc_eval.py,在另一个faster-rcnn的项目下,下载地址:
https:///rbgirshick/py-faster-rcnn/tree/master/lib/datasets
计算mAP,主要是用到voc_eval里的一个函数voc_eval,用法如下:
rec, prec, ap = voc_eval(’results/{}.txt’, ’VOCdevkit/VOC2007/Annotations/{}.xml’, ’VOCdevkit/VOC2007/ImageSets/Main/val.txt’, ’person’, ’.’)
第一个参数是刚才的验证模型结果文件地址,第二个参数是标记数据的地址,第三个参数是验证集地址,第四个参数是要计算准确度的类别名称。函数返回的第三个值就是对应类别的准确度。每次运行这个命令,都会在项目目录下生成一个annots.pkl的文件,如果更换验证集或者类别,需要删除这个文件重新计算。
有了准确度,mAP 就是所有类别的准确度相加,再除以所有类别的数量了。
但是在调用voc_eval的时候有些地方需要修改,voc_eval是根据python2的语法写的,里边用到了python2的cPickle和print的地方,我使用的时候python3,所以在调用的时候修改下几个关于cPickle的地方和print的地方:
import _pickle as cPickle
...
print("Reading annotation for {:d}/{:d}".format(i+ 1, let(imagenames)))
print("Saving cached annotations to {:s}".format(cachefile))
with open(cache file, ’wb’) as f:
cPickle.dump(recs, f)
...
with open(cachefile, ’rb’) as f:
recs = cPickle.load(f)
一个类一个类的输入计算ap再去计算平均值有点费劲,可以写一个简单的脚本程序来完成这个过程,文件如下:
from voc_eval import voc_eval
import os
sub_files = os.listdir("results")
mAPs = []
for i in range(len(sub_files)):
class_name = sub_files[i].split(".txt")[0]
rec, prec, ap = voc_eval(’results/{}.txt’, ’VOCdevkit/VOC2007/Annotations/{}.xml’, ’VOCdevkit/VOC2007/ImageSets/Main/val.txt’, class_name, ’.’)
print("{} : {}".format(class_name, ap))
mAPs.append(ap)
mAP = tuple(mAPs)
print("mAP : {}".format(float(sum(mAP)/len(mAP))))
经过计算,yolov3.weights在VOC数据集上的mAP达到了0.82。
到此,基于VOC数据的准备、训练、验证、mAP计算就已经完成了。我们可以进入在自己的数据集上做这些流程的工作了。
要开始用我们自己的数据训练了,这个过程有5步:
这个步骤就是生成VOC数据时的Animiations、ImagesSets、JPEGImages、labels的过程。在之前VOC数据训练的时候,我们已经知道了这几个文件夹的作用:
那么我们要怎么生成这些数据呢?之前用到的voc_label.py文件就是生成VOC数据的程序,打开参考了下,形成了思路:
在这里我就不展示生成这些数据所用到的脚本程序了,总之就是生成和VOC数据格式一样的文件就行。注意voc_label.py里的classes分类是你要分类的命名,和后面的my.names里的文件中的命名一致。
复制一份voc的.data文件,供修改用,这样也不至于破坏voc的文件。
cp cfg/voc.data cfg/my.data
打开my.data:
classes = 6 # 我要识别6种分类
train = data/my_train.txt # 训练集保存位置
valid = data/my_test.txt # 验证集保存位置
names = data/my.names # 类别名称存储文件
backup = backup # 模型文件输出地址
参考voc的训练文件和验证文件,发现其中内容就是训练图片和验证图片的保存位置。同样通过一个脚本根据我的数据生成这2个文件。接着建立my.names文件,保存类别名称,一行一个,注意要和Animations里标注的类名一致。这里我的my.names文件如下:
Pedestrian
Cyclist
Car
Truck
Tram
Tricycle
好了,my.data文件制作到此结束,接着要制作.cfg了。同样复制一份voc的cfg:
cp cfg/yolov3-voc.cfg cfg/my.cfg
修改如下参数:
[net]
batch=64
subdivisions=16
max_batches=2000
...
[convolutional]
filters=33
[yolo]
classes=6
random=1
...
[convolutional]
filters=33
[yolo]
classes=6
random=1
...
[convolutional]
filters=33
[yolo]
classes=6
random=1
注意:[yolo]和[convolutional]的修改一共有3处,都需要修改。
batch和subdivisions之前说过含义了,就不再讲述了。
其他cfg参数都没有修改,我们先跑通训练自己的数据,然后再回头来调整一些参数。
至此,.cfg文件也准备好了。我们可以开始训练自己的模型了,建议刚开始自己训练的时候不要准备过大的数据集数量,可以有个50张左右的图片先开始执行就行,先完整体验下后边的训练、测试等步骤,没有错误后,再修改训练集数据量,逐步放大这个过程。
准备好以上文件后,通过命令开始训练:
./darknet detector train data/my.data cfg/my.cfg darknet53.conv.74
如果训练到一半终止了,想继续训练可以利用命令:
./darknet detector train data/my.data cfg/my.cfg darknet53.conv.74 backup/xxx.backup
程序输出样式和之前VOC数据训练的输出一样,说明正常开始了。要是没正常开始,会报一些错误,比如有的文件找不到之类的,检查文件名看看是否正确。修改报错,重新训练即可。
一个完备的数据集合训练非常耗时,我用max_batches=50200的配置,在Geforce RTX 2070的GPU下,1.7GB的训练数据,训练了4天才完成。
这个过程我自己在小规模数据集合和小的max_batches上尝试训练了2次,这个过程有助于调整一些配置文件的错误,如果文件有错,最后的.weights文件是不能测试出结果的。可能遇到的错误有:
跟VOC数据集上的验证步骤一样,我们需要先修改my.cfg的参数:
[net]
#Testing
batch=1
subdvisions=1
#Trainning
#batch=64
#subdvisions=16
然后使用命令进行测试:
./darknet detector test cfg/my.data cfg/my.cfg backup/my_final.weights data/test.jpg
同VOC数据集的效果一样,如果成功,会在项目目录下生成predictions.jpg文件,显示目标识别结果。如下图所示:
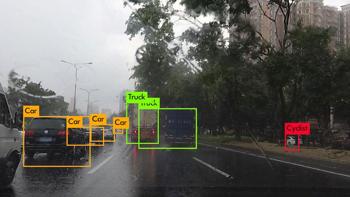
这一步跟刚才基于VOC数据的mAP计算过程一样,先通过命令计算验证集的数据,然后再通过脚本计算mAP。如下:
./darknet detector valid cfg/my.data cfg/my.cfg backup/my_final.weights
在调用计算mAP的脚本前,注意修改代码里的验证集、数据集的路径就行。
最后,自己模型的mAP达到了0.71。
本系列文章共两篇,总结记录了如何从0开始实现一个目标检测算法的过程。关于算法原理的部分可以参看这篇文章。我们在这个过程中先学习了目标检测任务的主要原理,找到了衡量模型的指标mAP,接着在众多的模型中选取了YOLOv3作为项目的实现方式,然后在VOC数据集上体验了YOLOv3的训练、测试、验证、计算mAP的全过程,接着在自己的数据集上也造作了训练、测试、验证、计算mAP的全过程,最后得到的模型mAP是0.71。这个过程中的数据集准备是非常重要和关键的,然后我们也积累了一些用于数据集生成和结果验证的脚本。
接着有什么可以进一步提高的吗?在这里我也列出一个TODO List,后续有时间会相继完成,到时候再总结记录下来分享给大家。
以上就是关于如何检测游戏使用gg修改器_gg修改器如何不被手游检测的全部内容,希望对大家有帮助。

gg游戏修改器怎么导入,gg游戏修改器如何导入? 大小:11.46MB9,702人安装 gg游戏修改器是一款十分实用且功能强大的游戏辅助软件,可以帮助玩家在玩游戏时获得……
下载
迷你gg修改器下载中文_迷你gg修改器下载 大小:14.78MB10,548人安装 大家好,今天小编为大家分享关于迷你gg修改器下载中文_迷你gg修改器下载的内容,赶……
下载
gg修改器要用那个root_gg修改器干什么用的 大小:16.37MB10,404人安装 大家好,今天小编为大家分享关于gg修改器要用那个root_gg修改器干什么用的的内容,……
下载
gg修改器最新版汉化,GG修改器:一款强大的游戏辅助工具 大小:8.91MB9,146人安装 GG修改器最新版汉化是一款功能强大的游戏辅助工具,可以让玩家在游戏中获得更多的优……
下载
gg修改器秒root版本,让你的手机秒变超级玩家gg修改器秒root版本 大小:15.53MB9,330人安装 在现今的智能手机世界里,游戏玩家已经占据了很大一部分的用户群体,而想要在手机上……
下载
gg游戏修改器修改数量,GG游戏修改器让您轻松游戏,搞定数量修改 大小:6.77MB9,487人安装 作为一名游戏爱好者,游戏的乐趣自然不言而喻。但是,有时候我们为了获得更多的胜利……
下载
gg修改器rootoppo,便捷高效的gg修改器rootoppo 大小:15.82MB9,219人安装 随着游戏产业的不断发展,越来越多的玩家对于游戏的要求也越来越高,而gg修改器就成……
下载
gg修改器最新版87.3,GG修改器最新版87.3:革新游戏体验 大小:3.12MB9,577人安装 游戏爱好者们,你们是否曾经遇到过游戏操作不顺畅、游戏玩法过于单一、游戏难度过高……
下载
gg修改器获取root视频_gg修改器免root教程视频 大小:9.48MB10,632人安装 大家好,今天小编为大家分享关于gg修改器获取root视频_gg修改器免root教程视频的内……
下载
怎么下载gg修改器最新版,如何轻松下载最新版GG修改器? 大小:19.09MB9,254人安装 随着游戏的日益火爆,越来越多的玩家开始使用GG修改器来提升游戏体验。然而,很多玩……
下载