GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器暂停游戏时间_gg修改器修改游戏时间的内容,赶快来一起来看看吧。
本文的写作目的是将分布式锁这一重要的分布式基础组件的几种典型设计与实现「剔肤见骨」地展示给各位读者(老毛病了,开头先自吹自擂一下)。写作背景是笔者在过去一段时间从事过分布式锁的研发工作,期间调研过多篇分布式锁典型实现的论文,在这里挑出比较优秀的三篇介绍一下。
本文接下来的内容会围绕三篇论文涉及的三个系统展开,它们是两个为 coarse-grained locks 设计的系统:Chubby 和 Zookeeper,一个为 fine-grained locks 设计的系统:VAX/VMS DLM(DLM stands for Distributed lock manager。补充一下,据说 Oracle DLM 就是参考这个系统实现的)。
Q:coarse-grained 和 fine-grained locks 是什么鬼?
A:在本文的语境下,coarse-grained locks 指的是持有时间长,加锁频率低的锁,e.g., 在 primary-backup 系统中用于实现 primary election 的锁;fine-grained locks 恰恰与之相反,e.g., 数据库系统中的 relation lock,基于 shared disk 架构的系统中的 page lock。
是 Google 在 2006 年公开的一个分布式锁系统。
用来解决分布式系统中 coarse-grained synchronization 问题以及 low-volume 的 metadata 存储问题。
在 Google,需要 coarse-grained synchronization 的场景有:GFS 中的 master election,Map Reduce 中的 rendezvous(又叫 barrier/CountDownLatch)。需要 low-volume metadata 存储的场景有:GFS,BigTable(它们需要一个存放 group membership,ACL 等信息的地方)。
2.2.1 Design Goals
2.2.2 Architecture
Chubby 支持多集群部署,单个集群叫 Chubby cell。Chubby cell 有自己的 name,client 指定 Chubby cell name,在 DNS lookup 时解析到具体的地址,然后去访问对应的 Chubby cell(下文 「2.2.3 Data Model」一节会介绍 Chubby cell name 如何指定)。
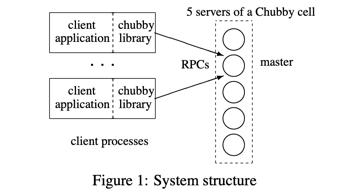
上图是一个典型 Chubby cell 的系统架构。cell 内部有 5 个 server,基于 Paxos 做 replication,用来实现 high available,其中一个 replica 是 master。 为了实现 Linearizability,Chubby 的所有读写操作都会走 master。Chubby client 是一堆进程。client applicaiton 通过 Chubby library 来和 Chubby replicas 进行 RPC 交互。由于读写操作只能走 master,client 在第一次访问 Chubby cell 时,会先根据 DNS 提供的 replicas 列表,向它们发送 master location 请求获取 master 的地址,然后和 master 建立连接,再进入到正常读写流程。
此外,Chubby 是支持 partitioning 的,一个 Chubby cell 内可以有多组 Paxos group,即多个 master,数据基于 hash 分布打散到各个 master 上(下文「Performance Stuff」一节会详细介绍 partitioning)。
2.2.3 Data Model
Chubby 的 data model 是一个极简版的文件系统,有 directory 和 file 的概念,二者亦统称为 node。
Chubby 不支持 move directory,因为跨 partition 的 move 不好做;不记录 directory modified time,不记录 node 的 last-access time,因为记了这些东西就不好做 client 端的 cache 了(下文「Performance Stuff」一节会详细介绍 client cache)。
每一个 file 会包含一段可用的空间(原文:Each file contains a sequence of un-interpreted bytes),可用来存一些数据。
给一个具体的例子:
/ls/cellfoo/appfoo/filefoo
在这个例子中,ls 表示 lock service,固定前缀。cellfoo 就是上文提到的 Chubby cell name,会在 DNS lookup 时解析成 Chubby cell 的地址。/appfoo/filefoo 是这个 Chubby cell 中具体的一个 application(appfoo) 下的一个 file(filefoo),filefoo 中可以存一些 metadata。
Chubby 中 node 的类型有两种:ephemeral 和 permanent。ephemeral nodes 在 client 的 session 断开或过期(下文「2.2.4 API」一节会详细介绍 session)的情况下会被 master 自动清理,而 permanent nodes 必须由 client 显式地清理。(前者通常用于实现 pirmary election,挂掉的 primary 持有的锁会被自动释放,replica 就有机会拿到锁成为新的 primary。)
任意一个 node 都可以作为 read/write lock。(下文「2.2.4 API」一节会详细介绍锁的用法。)
此外,Chubby 自身也有一些 metadata,包括:
2.2.4 API
笔者为保留原(懒)汁(病)原(犯)味(了),直接从论文中把 API 介绍复制过来了:
我们可以看到,API 的用法思路大致和文件系统一样,通过 Open() 获得文件的 handle,然后调用其他 API 对这个 handle 进行操作,最后使用完毕对 handle 进行 Close()。
client 通过 Acquire()/TryAcquire() 针对 handle 进行加锁,通过 Release() 主动释放锁。注意 Chubby 中的锁是 advisory lock,不是 mandatory lock,因此即使对某一个 file 加了写锁,也不会禁止其他 client 读写这个 file。做成这样的一个重要原因是,Chubby 锁常见的使用场景不是来实现 Chubby file 的并发控制,而是实现 client application 侧资源的并发控制,做成 mandatory lock 必须改 client application 代码,这是做不到的。
这里有一个分布式锁必须面对的一个问题:client 加锁成功后,挂掉/联系不上了怎么办?如何释放锁?谁来释放锁?
Chubby 引入 session 和 KeepAlive 机制来解决这个问题。
session + KeepAlive 这个方案实际上还存在问题:client A 的 session lease 过期,master 就会清理这个 session,并释放这个 session 持有的锁,接下来另外一个 client B 就有机会拿到这把锁(说白了,就是要保证锁的 liveness property)。如果 client A 确实挂掉了,这样做没啥问题。但是,如果 client A 实际还活着(可能由于 GC 或者进程暂停导致一段时间没有发送 KeepAlive RPC),就会出现 client A 和 client B 同时拿到了锁的异象(锁的 safety property 被打破)。设想这样一个场景,这把锁是用来保护某个共享的资源服务器不会被并发操作的,结果 client A 和 B 都拿到了锁,都去操作资源服务器,很大可能导致资源服务器的数据被写坏。
Chubby 为解决这个问题引入了两种解决方案:
Chubby 的 API 都支持同步和异步两种调用方式,可以通过 API 参数指定。如果是异步调用,client 会告知 master 自己关注哪些 event,master 会在这些 event 触发后通知 client(通过提前回复 KeepAlive RPC)。
Chubby 支持的 event 主要分为两类:
最后举个用 Chubby 来实现 primary election 的例子来更加具体的说明下 API 的用法,parimary election 的主要流程如下:
2.2.5 Reliability & Availability Stuff
Chubby 侧重于 reliability 和 availability,上文已经提到过的 replication 就是一个提升 reliability 和 availability 的有效手段。这里我们再看一下,Chubby 如何通过的优雅(grace)的 fail-over 机制来提升 reliability。
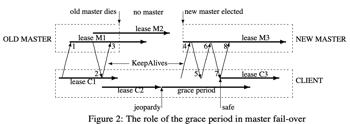
上图描述了当 master 发生 fail-over(从 old master 切到 new master)时发生了什么。时间线是从左到右的,我们也从左到右看。在 lease C1 的有效期内 client 发送 KeepAlive 请求(1)到 old master,old master block 住这个请求直到 client lease 快要过期才回复(2),同时 old master 视角的 client lease(这个 lease 是从回复 KeepAlive RPC 的时刻算起的,考虑到 RPC 传输的时间,实际会大于真实的 client lease 一点点) 变成了 M2,收到 KeepAlive 回复后,client lease 变成了 C2,紧接着 client 立即发起下一个 KeepAlive 请求(3)。不幸的是,old master 挂了,KeepAlive 请求很久没有得到回复,client lease C2 过期后进入 grace period(默认时长为 45s),同时会产生一个 jeopardy event(client application 可以观测到这个 event,可按需做一些处理逻辑)。在 grace period 期间 client 的所有请求都被 pending(相当于我们的静态*管理)。万幸,new master 在此期间选举成功了,new master 直接为 client 分配上它认为的 old master 可能为 client 分配的最大 lease(lease 时长是由 master 控制的,下文「 2.2.6 Performance Stuff」会详细介绍)。一段时间后,client 再次发起的 KeepAlive 请求(4)终于联系上了 new master。不过由于 epoch number (下面会介绍)错误,请求被拒绝并告知最新的 epoch number(5)。接着 client 拿着新的 epoch number 再次发起 KeepAlive 请求(6),收到回复(7)后,grace period 结束,产生一个 safe event(同样,client application 可按需处理。如果没有从 grace period 幸存下来,就会产生一个 expired event。)。这时 client lease 变成了 C3,然后立即发起 下一个KeepAlive 请求(8),后续就是正常流程了。
通过引入上面这个 grace period 机制,很大程度上减小了 master fail-over 对 client 影响,虽然搞了一通静态*管理,但是 client 没有报错啊!可以说很 reliable!
这里说一下上面提到的 epoch number,这个值其实就是 Paxos 里面的 round(aka ballot) number,每选举一轮递增一下。new master 的 epoch number 会大于 old master 的 epoch number。new master 通过拒绝小于自己的 epoch number 的请求,实现拒绝发送给 old master 的太老的请求(太老是多老?没能在 grace period 期间通过 KeepAlive RPC「上车」new master,拿不到新 epoch number 的请求都算)。
补充一下 handle 和 session 的 fail-over recovery:
2.2.6 Performance Stuff
Chubby 通过让读写请求都走 master 来实现 Lineariziablity,显然 master 干活太多,容易成为瓶颈。尽管 Chubby 更侧重 reliability 和 availability,这不妨碍用各种「骚操作」去优化 performance。
总结一下优化点,主要有:
笔者认为 Chubby 是一个成功的系统,针对分布式系统「coarse-grained synchronization,low-volume metadata storage」问题给出了实用的解决方案,它在 Big Table,Map Reduce,GFS 这三驾马车上都应用得不错也侧面证明了它的价值。
笔者看到的 Chubby 的一个缺点:资源利用率不够高,master 一个人在干活(尤其是以一己之力对抗所有 KeepAlive RPC,令人起敬),replicas 都在看戏。
笔者想到的 Chubby 的一个优化点:其实 locks 可以不持久化,只记在内存里,做成像 session 一样,fail-over 时让 client 上报过来,在内存里重建。如果搞了这个优化,Chubby 甚至有能力支持中轻度的 fine-grained locks,不过,这好像背离了 Chubby 的 design goals 🙂
笔者发现的 Chubby paper 中的一个问题:sequencer 其实不能彻底解决上文提到的 client A 和 B 同时拿到锁去操作资源服务器的问题。如果资源服务器先处理 client B 的请求,再处理 client A 的请求,由于 B 的 sequencer(中的 lock generation number)大于 A 的 sequencer,因此 client A 请求被拒绝,这种场景是没问题的。如果资源服务器先处理 client A 的请求,处理过程中又收到了 client B 的请求,client B 的请求不会被拒绝,client A 和 B 并发操作,照样导致资源服务器的数据被写坏。要解决这种情况,笔者能想到的解决方案,要么把资源服务器上的操作放在 critical section 中,保证不会并发,要么资源服务器收到 client B 的请求时,检查发现 client A 的请求还在处理,就等 client A 请求执行完毕或者把它直接 abort 掉,再处理 client B 的请求。
笔者个人从 Chubby 这里学习到的系统设计小技巧都是关于 KeepAlive RPC 的骚操作的:
警(敬)告一下读到此处的读者,非常抱歉,本文尚未写完,笔者后续会补上本文的 PART II 和 PART III 介绍一下 Zookeeper 和 VAX/VMS DLM。
在这里提前预告下 PART II 和 PART III 的内容:
PART II:介绍同样是为 coarse-grained locks 设计的分布式锁系统 Zookeeper,相较于 Chubby,Zookeeper 是一个更加通用的 coordination service,不止于分布式锁。此外,Zookeeper 采用了更弱的 consistency 解决了上文提到了「master 干活,replicas 看戏」的问题。详情见 PART II 为您分解。
PART III:介绍为 fine-grained locks 设计的分布式锁系统 VAX/VMS DLM,它的独特之处在于它是一个纯内存(volatile)的高性能分布式锁系统。高性能是多高?简直是丧心病狂,令人发指。详情见 PART III 为您分解。
本文首发于 hhwyt,在知乎亦有发布,毫无疑问,来自知乎点赞的鼓励是笔者迅速码字的重要原因之一。
本文作者:hhwyt
本文链接:https://hhwyt.xyz/2022-05-15-dlm-all-in-one
以上就是关于gg修改器暂停游戏时间_gg修改器修改游戏时间的全部内容,希望对大家有帮助。
gg修改器免root检测,gg修改器免root检测:让你尽情享受游戏快感 大小:5.18MB10,079人安装 如果你是一名游戏玩家,那么你一定不会陌生于各种游戏修改器,它们可以让你轻松获得……
下载
平行空间免ROOT下载,平行空间免root优化版 大小:3.62MB10,794人安装 而是在一齐,就算不说话也不会感到尴尬。这份自在,连恋人都无法给予。 大家好,今……
下载
gg修改器 免root方法,介绍GG修改器 大小:8.27MB9,759人安装 GG修改器是一款在移动游戏中非常流行的工具。它允许玩家在游戏中修改各种数值,以获……
下载
gg修改器中文版使用教程_gg修改器中文版怎么用教学 大小:13.16MB10,788人安装 大家好,今天小编为大家分享关于gg修改器中文版使用教程_gg修改器中文版怎么用教学……
下载
免root开gg修改器_gg修改器免root怎么使用 大小:18.93MB10,561人安装 大家好,今天小编为大家分享关于免root开gg修改器_gg修改器免root怎么使用的内容,……
下载
gg修改器破解版和中文版,为什么 GG修改器破解版和中文版是游戏达人的必备之选 大小:13.65MB9,733人安装 作为一名游戏爱好者,你一定也经常遇到一些游戏中的难题,如无法继续进行、找不到游……
下载
gg游戏修改器最新,瞬间让你游戏高手!GG游戏修改器最新版,让游戏变得更加刺激 大小:17.30MB9,868人安装 无论你是一个游戏达人还是一个新手,你都希望自己能够在游戏中有更好的表现。可是,……
下载
gg修改器刷迷你币中文版,GG修改器刷迷你币中文版:改变游戏世界的神器 大小:19.62MB9,301人安装 作为一名游戏爱好者,大家都知道迷你世界,一个非常受欢迎的沙盒游戏。在这个游戏中……
下载
gg修改器下载中文96.1_gg修改器下载中文迷你世界 大小:7.49MB10,716人安装 大家好,今天小编为大家分享关于gg修改器下载中文96.1_gg修改器下载中文迷你世界的……
下载
gg修改器最新正版下载,gg修改器轻松畅玩游戏的必备神器 大小:11.51MB9,748人安装 对于爱玩游戏的玩家们来说,可能会遇到一些困扰,比如游戏中的某些操作需要大量的时……
下载