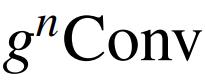
GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器中文版官网地址_gg修改器官方地址的内容,赶快来一起来看看吧。
机器之心专栏
机器之心编辑部
来自清华大学和 Meta AI 的研究者证明了视觉 Transformer 的关键,即输入自适应、长程和高阶空间交互,也可以通过基于卷积的框架有效实现。
视觉 Transformer 的最新进展表明,在基于点积自注意力的新空间建模机制驱动的各种任务中取得了巨大成功。在本文中,来自清华大学和 Meta AI 的研究者证明了视觉 Transformer 背后的关键成分,即输入自适应、长程和高阶空间交互,也可以通过基于卷积的框架有效实现。作者提出了递归门卷积(
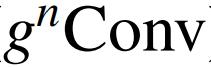
),它用门卷积和递归设计进行高阶空间交互。新操作具有高度灵活性和可定制性,与卷积的各种变体兼容,并将自注意力中的二阶交互扩展到任意阶,而不引入显著的额外计算。
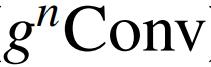
可以作为一个即插即用模块来改进各种视觉 Transformer 和基于卷积的模型。基于该操作,作者构建了一个新的通用视觉主干族,名为 HorNet。在 ImageNet 分类、COCO 对象检测和 ADE20K 语义分割方面的大量实验表明,HorNet 在总体架构和训练配置相似的情况下,优于 Swin Transformers 和 ConvNeXt。HorNet 还显示出良好的可扩展性,以获得更多的训练数据和更大的模型尺寸。除了在视觉编码器中的有效性外,作者还表明
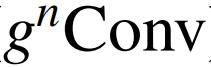
可以应用于任务特定的解码器,并以较少的计算量持续提高密集预测性能。本文的结果表明,
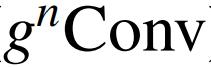
可以作为一个新的视觉建模基本模块,有效地结合了视觉 Transformer 和 CNN 的优点。

1. Motivation
自 AlexNet 在过去十年中引入以来,卷积神经网络(CNN)在深度学习和计算视觉方面取得了显著进展。CNN 有许多优良的特性,使其自然适用于广泛的视觉应用。平移等变性为主要视觉任务引入了有用的归纳偏差,并实现了不同输入分辨率之间的可传递性。高度优化的实现使其在高性能 GPU 和边缘设备上都非常有效。架构的演变进一步增加了其在各种视觉任务中的受欢迎程度。
基于 Transformer 的架构的出现极大地挑战了 CNN 的主导地位。通过将 CNN 架构中的一些成功设计与新的自注意力机制相结合,视觉 Transformer 在各种视觉任务上表现出领先的性能,如图像分类、物体检测、语义分割和视频理解。是什么让视觉 Transformer 比 CNN 更强大?通过学习视觉 Transformer 方面的新设计,已经做出了一些努力来改进 CNN 架构。然而,目前工作尚未从高阶空间交互的角度分析点积自注意力在视觉任务中的有效性。
虽然由于非线性,深度模型中的两个空间位置之间存在复杂且通常高阶的交互,但自注意力和其他动态网络的成功表明,结构设计引入的显式和高阶空间交互有利于提高视觉模型的建模能力。如上图所示,普通卷积运算没有明确考虑空间位置(即红色特征)及其相邻区域(即浅灰色区域)之间的空间交互。增强卷积运算,如动态卷积,通过生成动态权重引入显式空间交互。Transformers 中的点积自注意力操作由两个连续的空间交互组成,通过在查询、键和值之间执行矩阵乘法。视觉建模基本操作的趋势表明,可以通过增加空间交互的顺序来提高网络容量。
在本文中,作者总结了视觉 Transformers 成功背后的关键因素是通过自注意力操作实现输入自适应、远程和高阶空间交互的空间建模新方法。虽然之前的工作已经成功地将元架构、输入自适应权重生成策略和视觉 Transformers 的大范围建模能力迁移到 CNN 模型,但尚未研究高阶空间交互机制。作者表明,使用基于卷积的框架可以有效地实现所有三个关键要素。作者提出了递归门卷积(g nConv),它与门卷积和递归设计进行高阶空间交互。与简单地模仿自注意力中的成功设计不同,g n Conv 有几个额外的优点:1)效率。基于卷积的实现避免了自注意力的二次复杂度。在执行空间交互期间逐步增加通道宽度的设计也使能够实现具有有限复杂性的高阶交互;2) 可扩展。将自注意力中的二阶交互扩展到任意阶,以进一步提高建模能力。由于没有对空间卷积的类型进行假设,
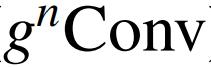
与各种核大小和空间混合策略兼容;3) 平移等变性。
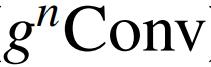
完全继承了标准卷积的平移等变性,这为主要视觉引入了有益的归纳偏置。
基于
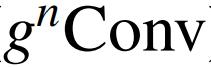
,作者构建了一个新的通用视觉主干族,名为 HorNet。作者在 ImageNet 分类、COCO 对象检测和 ADE20K 语义分割上进行了大量实验,以验证本文模型的有效性。凭借相同的 7×7 卷积核 / 窗口和类似的整体架构和训练配置,HorNet 优于 Swin 和 ConvNeXt 在不同复杂度的所有任务上都有很大的优势。通过使用全局卷积核大小,可以进一步扩大差距。HorNet 还显示出良好的可扩展性,可以扩展到更多的训练数据和更大的模型尺寸,在 ImageNet 上达到 87.7% 的 top-1 精度,在 ADE20K val 上达到 54.6% 的 mIoU,在 COCO val 上通过 ImageNet-22K 预训练达到 55.8% 的边界框 AP。除了在视觉编码器中应用
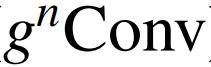
外,作者还进一步测试了在任务特定解码器上设计的通用性。通过将
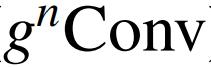
添加到广泛使用的特征融合模型 FPN,作者开发了 HorFPN 来建模不同层次特征的高阶空间关系。作者观察到,HorFPN 还可以以较低的计算成本持续改进各种密集预测模型。结果表明,
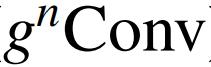
是一种很有前景的视觉建模方法,可以有效地结合视觉 Transofrmer 和 CNN 的优点。
2. 方法
2.1 gnConv: Recursive Gated Convolutions
在本节中,将介绍 g n Conv,这是一种实现长期和高阶空间相互作用的有效操作。g n Conv 由标准卷积、线性投影和元素乘法构建,但具有与自注意力类似的输入自适应空间混合功能。
Input-adaptive interactions with gated convolution
视觉 Transformer 最近的成功主要取决于视觉数据中空间交互的正确建模。与只需使用静态卷积核来聚合相邻特征的 CNN 不同,视觉 Transformer 应用多头自注意力动态生成权重以混合空间 token。然而,二次复杂度在很大程度上阻碍了视觉 Transformer 的应用,尤其是在下游任务中,包括需要更高分辨率特征图的分割和检测。在这项工作中,作者没有像以前的方法那样降低自注意力的复杂性,而是寻求一种更有效的方法,通过卷积和完全连接层等简单操作来执行空间交互。
本文方法的基本操作是门卷积(gConv)。

是输入特征,门卷积的输出
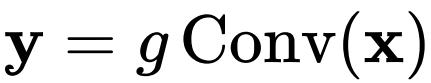
可以写成:
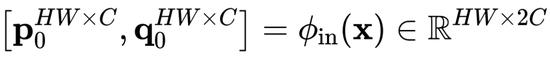
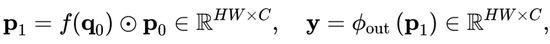
其中

,
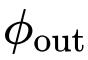
是执行通道混合的线性投影层,f 是深度卷积。
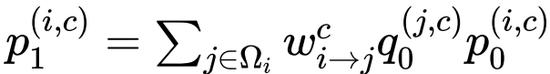
,其中
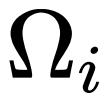
是以 i 为中心的局部窗口,w 表示 f 的卷积权重。因此,上述公式通过元素乘法明确引入了相邻特征
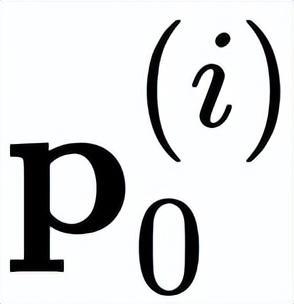
和
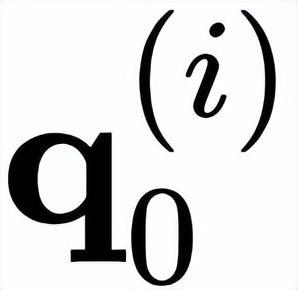
之间的相互作用。作者将 gConv 中的相互作用视为一阶相互作用,因为每个
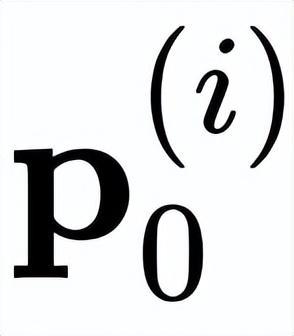
仅与其相邻特征

相互作用一次。
High-order interactions with recursive gating
在与 gConv 实现有效的 1 阶空间相互作用后,作者设计了
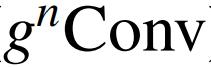
,这是一种递归门卷积,通过引入高阶相互作用来进一步增强模型容量。形式上,首先使用
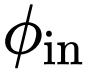
获得一组投影特征
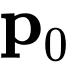
和
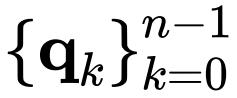
:
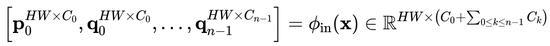
然后,作者通过以下方式递归执行 gating 卷积:
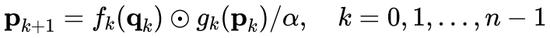
其中,将输出缩放 1/α 以稳定训练。
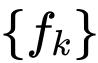
是一组深度卷积层,
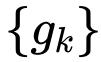
用于按不同阶匹配维数。
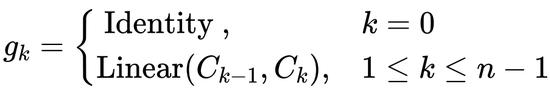
最后,作者将最后一个递归步骤
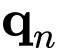
的输出馈送到投影层
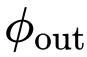
,以获得
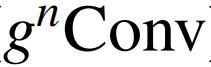
的结果。从递归公式方程可以很容易地看出,
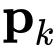
的交互阶在每一步后将增加 1。因此,可以看到,
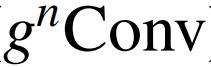
实现了 n 阶空间相互作用。还值得注意的是,只需要一个 f 来执行深度卷积,以串联特征
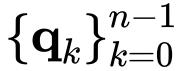
,而不是像上面等式中那样计算每个递归步骤中的卷积,这可以进一步简化实现并提高 GPU 的效率。为了确保高阶交互不会引入太多计算开销,作者将每个阶中的通道维度设置为:
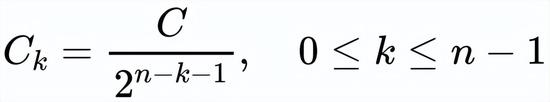
该设计表明,以从粗到细的方式执行交互,其中较低的阶数是用较少的通道计算的。此外,
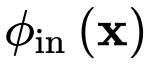
的通道维数正好为 2C,即使 n 增加,总的浮点也可以严格有界。
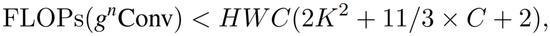
其中 K 是深度卷积的核大小。因此,
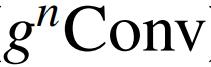
以与卷积层类似的计算成本实现高阶交互。
Long-term interactions with large kernel convolutions
视觉 Transformer 和传统 CNN 的另一个区别是感受野。传统的 CNN 通常在整个网络中使用 3×3 卷积,而视觉 Transformer 在整个特征图上或在相对较大的局部窗口(例如 7×7)内计算自注意力。视觉 Transformer 中的感受野可以更容易地捕捉长期依赖关系,这也是公认的视觉 Transformer 的关键优势之一。受这种设计的启发,最近有一些努力将大型内核卷积引入 CNN。为了使
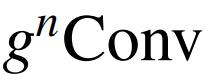
能够捕捉长期交互,作者采用了两种深度卷积 f 实现:
1)7×7 卷积。7×7 是 Swin Transformers 和 ConvNext 的默认窗口 / 内核大小。[研究表明,内核大小在 ImageNet 分类和各种下游任务上具有良好的性能。作者遵循此配置,与视觉 Transformers 和现代 CNN 的代表性工作进行了公平比较。
2)全局滤波器(GF)。GF 层将频域特征与可学习的全局滤波器相乘,这相当于具有全局核大小和圆形填充的空域卷积。通过使用全局滤波器处理一半通道和使用 3×3 深度卷积处理另一半通道来使用 GF 层的修改版本,并且仅在后期使用 GF 层来保留更多的局部细节。
Spatial interactions in vision models
作者从空间交互的角度回顾了一些有代表性的视觉模型设计。具体地说,作者对特征 x_i 与其相邻特征

之间的相互作用感兴趣。视觉 Transformer 和以前架构之间的关键区别,即视觉 Transformer 在每个基本块中具有高阶空间交互。这一结果启发作者探索一种能够以两个以上阶数实现更高效和有效空间交互的架构。如上所述,作者提出的
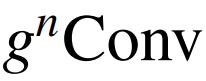
可以实现复杂度有界的任意阶交互。还值得注意的是,与深度模型(如宽度和深度)中的其他比例因子类似,在不考虑整体模型容量的情况下简单地增加空间交互的顺序将不会导致良好的权衡。在本文中,作者致力于在分析精心设计的模型的空间交互阶数的基础上,开发一种更强大的视觉建模架构。对高阶空间相互作用进行更深入和正式的讨论可能是未来的一个重要方向。
Relation to dot-product self-attention
尽管本文的
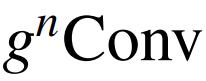
的计算与点积自注意有很大差异,但作者将证明
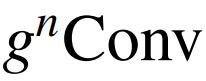
也实现了输入自适应空间混合的目标。假设 M 是通过多头自注意力(MHSA)获得的注意力矩阵,将 M 写为(
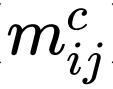
),因为混合权重可能在通道中变化。位置 i 处第 c 个通道的空间混合结果(在最终通道混合投影之前)为:
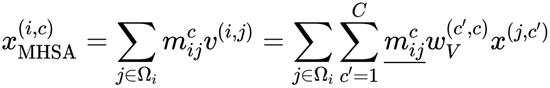
其中,w_V 是 V 投影层的权重。注意,通过点积运算获得的m_ij包含一阶相互作用。另一方面,
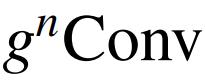
的输出(在
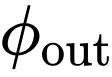
之前)可以写成:
下图总结了
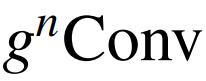
的细节实现:
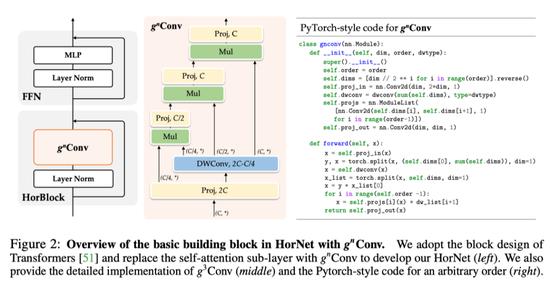
2.2 Model Architectures
HorNet
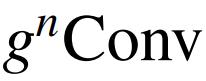
可以替代视觉 Transformer 或现代 CNN 中的空间混合层。作者遵循与以前的元架构来构建 HorNet,其中基本块包含空间混合层和前馈网络(FFN)。根据模型大小和深度卷积 f_k 的实现,有两个模型变体系列,分别命名为 HorNet-T/S/B/L 7×7 和 HorNet-T/S/B/L GF。作者将流行的 Swin Transformer 和 ConvNeXt 视为视觉 Transformer 和 CNN 基线,因为本文的模型是基于卷积框架实现的,同时具有像视觉 Transformer 一样的高阶交互。为了与基线进行公平比较,作者直接遵循 Swin Transformers-S/B/L 的块数,但在第 2 阶段插入一个额外的块,以使整体复杂度接近,从而在所有模型变体的每个阶段中产生 [2、3、18、2] 个块。只需调整通道 C 的基本数量,以构建不同大小的模型,并按照惯例将 4 个阶段的通道数量设置为[C、2C、4C、8C]。对于 HorNet-T/S/B/L,分别使用 C=64、96、128、192。默认情况下,将每个阶段的交互顺序(即
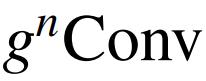
中的 n)设置为 2,3,4,5,这样最粗阶C_0的通道在不同阶段中是相同的。
HorFPN
除了在视觉编码器中使用
之外,作者发现本文的
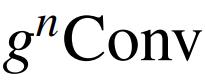
可以是标准卷积的增强替代方案,该方案考虑了基于卷积的各种模型中的高阶空间相互作用。因此,
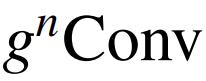
替换 FPN 中用于特征融合的空间卷积,以改善下游任务的空间交互。具体来说,作者在融合不同金字塔级别的特征后添加了
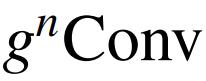
。对于目标检测,作者在每个级别用 替换自顶向下路径后的 3×3 卷积。对于语义分割,作者简单地将多阶特征映射串联后的 3×3 卷积替换为
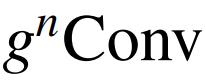
,因为最终结果直接从该串联特征预测。作者同样提供了两个实现,称为 HorFPN 7×7 和 HorFPN GF,由f_k的选择决定。
3. 实验
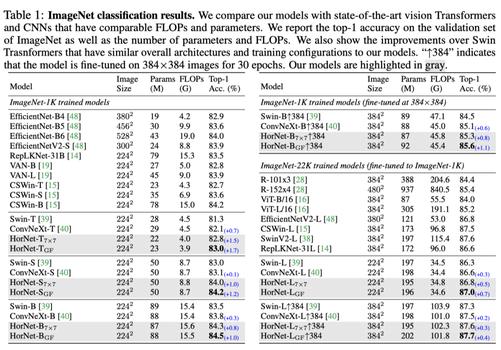
ImageNet 分类实验结果总结在上表中。本文的模型通过最先进的视觉 Transformer 和 CNNs 实现了非常有竞争力的性能。值得注意的是,HorNet 超越了 Swin Transformers 和 ConvNeXt,它们在各种模型尺寸和设置上都具有相似的整体架构和训练配置。
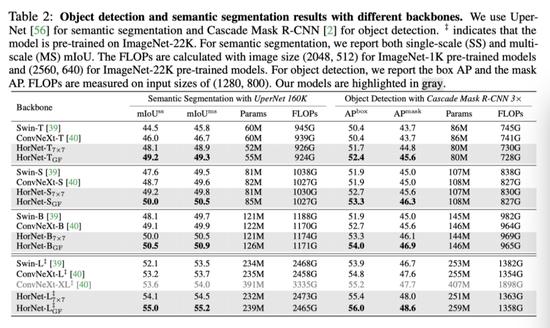
作者使用常用的 UperNet 框架评估了 ADE20K 数据集上的 HorNet 语义分割任务。所有模型都使用 AdamW 优化器训练 160k 次迭代,全局 batch 处理大小为 16。训练期间的图像大小对于 ImagNet-1k (HorNet-T/S/B) 预训练模型为 512 × 512,对于 ImageNet-22K 预训练模型 (HorNet-L) 为 640 × 640。结果总结在上表的左侧部分,其中报告了验证集上的单尺度 (SS) 和多尺度 (MS) mIoU。作者还在 COCO 数据集上评估了本文的模型。作者采用级联 Mask R-CNN 框架使用 HorNet-T/S/B/L 主干进行对象检测和实例分割。继 Swin 和 ConvNeXt 之后,作者使用了具有多尺度训练的 3× schedule。上表的右侧部分比较了本文的 HorNet 模型和 Swin/ConvNeXt 模型的 box AP 和 mask AP。
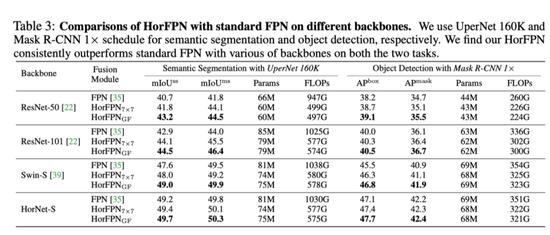
作者现在展示了所提出的
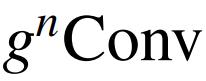
的另一个应用,即作为更好的融合模块,可以更好地捕获密集预测任务中不同级别特征之间的高阶交互。具体而言,作者直接修改了分别用于语义分割和对象检测的 FPN,如 SuperNet 和 Mask R-CNN。在上表中显示了结果,其中作者比较了本文的 HorFPN 和标准 FPN 在不同主干上的性能,包括 ResNet-50/101、Swin-S 和 HorNet-S 7×7。对于语义分割,作者发现 HorFPN 可以显著减少 FLOPs(∼50%),同时实现更好的 mIoU。
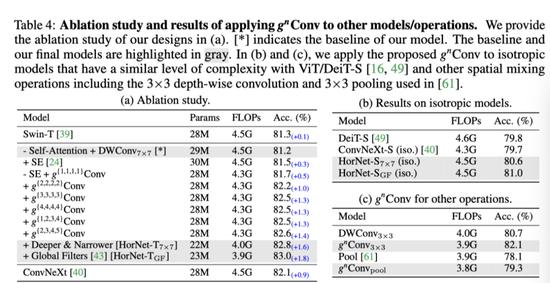
上表展示了本文方法的消融实验结果。
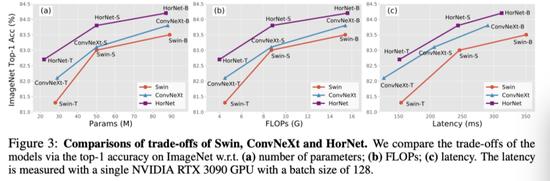
上图展示了 Swin、ConvNeXt 和 HorNet 的权衡比较。
4. 总结
作者提出了递归门卷积(
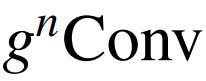
),它与门卷积和递归设计进行有效、可扩展和平移等变的高阶空间交互。在各种视觉 Transformer 和基于卷积的模型中,
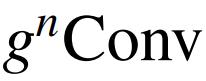
可以作为空间混合层的替代品。在此基础上,作者构建了一个新的通用视觉骨干 HorNet 家族。大量实验证明了
和 HorNet 在常用视觉识别基准上的有效性。
最后笔者已经将 HorNet 网络代码 汇总整理在以下 Github 库中,地址为:
https:///xmu-xiaoma666/External-Attention-pytorch
该库是一个面向小白的顶会论文核心代码库。里面汇总诸多顶会论文核心代码,包括 Attention、Self-Attention、Backbone、MLP、Conv 等。
5. 将 HorNet 结合 YOLOv5 模型应用
YOLOAir 库中 已经将 HorNet 网络应用在 YOLO 模型中,分别以下三种方式与 YOLOv5 模型 结合:
1. 在 YOLOv5 中 使用 gnconv 模块示例
2. 在 YOLOv5 中 使用 HorBlock 模块示例
3. 在 YOLOv5 中 使用 HorNet 主干网络示例
由于篇幅有限,具体改进代码及方式可以在以下 GitHub 库中获取:
面向科研小白的 YOLO 目标检测库:https:///iscyy/yoloair
参考链接:
https://arxiv.org/abs/2207.14284
https:///raoyongming/HorNet
https:///xmu-xiaoma666/External-Attention-pytorch
https:///iscyy/yoloair
以上就是关于gg修改器中文版官网地址_gg修改器官方地址的全部内容,感谢大家的浏览观看,如果你喜欢本站的文章可以CTRL+D收藏哦。

奥特曼gg修改器最新版教程,奥特曼GG修改器最新版教程:如何轻松修改游戏数据 大小:12.21MB9,577人安装 奥特曼GG修改器是一款非常实用的游戏修改工具,可以帮助玩家快捷地修改游戏数据。最……
下载
gg修改器2免root下载_gg修改器免root版中文下载 大小:9.29MB10,685人安装 大家好,今天小编为大家分享关于gg修改器2免root下载_gg修改器免root版中文下载的内……
下载
gg游戏修改器改无尽, gg游戏修改器改无尽:一个令人惊叹的游戏改造工具 大小:3.37MB9,838人安装 当今社会,游戏经常被视为一种休闲娱乐方式。然而,有时我们会遇到一些让我们无法通……
下载
GG修改器中文版教学,GG修改器中文版的卓越功能 大小:4.01MB9,555人安装 GG修改器中文版是一个非常好用的游戏修改工具,它可以帮助玩家修改游戏中的各种属性……
下载
gg游戏修改器怎么弄,gg游戏修改器:让游戏更加激动人心 大小:5.65MB9,505人安装 gg游戏修改器是一款非常流行的游戏辅助工具,它可以为玩家提供众多的游戏修改功能,……
下载
gg修改器设置中文_gg修改器怎么改成中文 大小:9.47MB10,736人安装 大家好,今天小编为大家分享关于gg修改器设置中文_gg修改器怎么改成中文的内容,赶……
下载
没root可以用gg修改器么,GG修改器没有Root也能轻松修改游戏 大小:8.83MB9,363人安装 在游戏中摆脱限制、获得更多好处是多数玩家的夙愿,但是要实现这个愿望经常需要玩家……
下载
免root版GG修改器_gg修改器免root版 使用 大小:8.75MB10,687人安装 大家好,今天小编为大家分享关于免root版GG修改器_gg修改器免root版 使用的内容,赶……
下载
gg修改器下载中文无病毒,GG修改器下载中文无病毒,优秀的游戏辅助利器! 大小:5.69MB9,424人安装 在现代高科技时代,许多游戏已经达到了非常惊人的水平,精美的画面和逼真的动作让我……
下载
gg修改器脚本最新,赞美gg修改器脚本最新的理由 大小:7.56MB9,746人安装 在当今的游戏社区中,使用gg修改器是很常见的一件事情。而在这样的情况下,gg修改器……
下载