GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器框架免root中文版_gg修改器免root框架下载及其使用的内容,赶快来一起来看看吧。

作者 | 王柏生、谢广军
导读:本文摘自于王柏生、谢广军撰写的《深度探索Linux系统虚拟化:原理与实现》一书,介绍了CPU虚拟化的基本概念,探讨了x86架构在虚拟化时面临的障碍,以及为支持CPU虚拟化,Intel在硬件层面实现的扩展VMX。
同时,介绍了在VMX扩展支持下,虚拟CPU从Host模式到Guest模式,再回到Host模式的完整生命周期。
Gerald J. Popek和Robert P. Goldberg在1974年发表的论文“Formal Requirements for Virtualizable Third Generation Architectures”中提出了虚拟化的3个条件:
1)等价性,即VMM需要在宿主机上为虚拟机模拟出一个本质上与物理机一致的环境。虚拟机在这个环境上运行与其在物理机上运行别无二致,除了可能因为资源竞争或者VMM的干预导致在虚拟环境中表现略有差异,比如虚拟机的I/O、网络等因宿主机的限速或者多个虚拟机共享资源,导致速度可能要比独占物理机时慢一些。
2)高效性,即虚拟机指令执行的性能与其在物理机上运行相比并无明显损耗。该标准要求虚拟机中的绝大部分指令无须VMM干预而直接运行在物理CPU上,比如我们在x86架构上通过Qemu运行的ARM系统并不是虚拟化,而是模拟。
3)资源控制,即VMM可以完全控制系统资源。由VMM控制协调宿主机资源给各个虚拟机,而不能由虚拟机控制了宿主机的资源。

陷入和模拟模型
为了满足Gerald J. Popek和Robert P. Goldberg提出的虚拟化的3个条件,一个典型的解决方案是陷入和模拟(Trap and Emulate)模型。
一般来说,处理器分为两种运行模式:系统模式和用户模式。相应地,CPU的指令也分为特权指令和非特权指令。
特权指令只能在系统模式运行,如果在用户模式运行就将触发处理器异常。操作系统允许内核运行在系统模式,因为内核需要管理系统资源,需要运行特权指令,而普通的用户程序则运行在用户模式。
在陷入和模拟模型下,虚拟机的用户程序仍然运行在用户模式,但是虚拟机的内核也将运行在用户模式,这种方式称为特权级压缩(Ring Compression)。在这种方式下,虚拟机中的非特权指令直接运行在处理器上,满足了虚拟化标准中高效的要求,即大部分指令无须VMM干预直接在处理器上运行。
但是,当虚拟机执行特权指令时,因为是在用户模式下运行,将触发处理器异常,从而陷入VMM中,由VMM代理虚拟机完成系统资源的访问,即所谓的模拟(emulate)。
如此,又满足了虚拟化标准中VMM控制系统资源的要求,虚拟机将不会因为可以直接运行特权指令而修改宿主机的资源,从而破坏宿主机的环境。

x86架构虚拟化的障碍
Gerald J. Popek和Robert P. Goldberg指出,修改系统资源的,或者在不同模式下行为有不同表现的,都属于敏感指令。
在虚拟化场景下,VMM需要监测这些敏感指令。一个支持虚拟化的体系架构的敏感指令都属于特权指令,即在非特权级别执行这些敏感指令时CPU会抛出异常,进入VMM的异常处理函数,从而实现了控制VM访问敏感资源的目的。
但是,x86架构恰恰不能满足这个准则。x86架构并不是所有的敏感指令都是特权指令,有些敏感指令在非特权模式下执行时并不会抛出异常,此时VMM就无法拦截处理VM的行为了。
我们以修改FLAGS寄存器中的IF(Interrupt Flag)为例,我们首先使用指令pushf将FLAGS寄存器的内容压到栈中,然后将栈顶的IF清零,最后使用popf指令从栈中恢复FLAGS寄存器。如果虚拟机内核没有运行在ring 0,x86的CPU并不会抛出异常,而只是默默地忽略指令popf,因此虚拟机关闭IF的目的并没有生效。
有人提出半虚拟化的解决方案,即修改Guest的代码,但是这不符合虚拟化的透明准则。后来,人们提出了二进制翻译的方案,包括静态翻译和动态翻译。静态翻译就是在运行前扫描整个可执行文件,对敏感指令进行翻译,形成一个新的文件。
然而,静态翻译必须提前处理,而且对于有些指令只有在运行时才会产生的副作用,无法静态处理。于是,动态翻译应运而生,即在运行时以代码块为单元动态地修改二进制代码。动态翻译在很多VMM中得到应用,而且优化的效果非常不错。

VMX
虽然大家从软件层面采用了多种方案来解决x86架构在虚拟化时遇到的问题,但是这些解决方案除了引入了额外的开销外,还给VMM的实现带来了巨大的复杂性。于是,Intel尝试从硬件层面解决这个问题。
Intel并没有将那些非特权的敏感指令修改为特权指令,因为并不是所有的特权指令都需要拦截处理。举一个典型的例子,每当操作系统内核切换进程时,都会切换cr3寄存器,使其指向当前运行进程的页表。
但是,当使用影子页表进行GVA到HPA的映射时,VMM模块需要捕获Guest每一次设置cr3寄存器的操作,使其指向影子页表。而当启用了硬件层面的EPT支持后,cr3寄存器不再需要指向影子页表,其仍然指向Guest的进程的页表。
因此,VMM无须再捕捉Guest设置cr3寄存器的操作,也就是说,虽然写cr3寄存器是一个特权操作,但这个操作不需要陷入VMM。
Intel开发了VT技术以支持虚拟化,为CPU增加了Virtual-Machine Extensions,简称VMX。一旦启动了CPU的VMX支持,CPU将提供两种运行模式:VMX Root Mode和VMX non-Root Mode,每一种模式都支持ring 0 ~ ring 3。
VMM运行在VMX Root Mode,除了支持VMX外,VMX Root Mode和普通的模式并无本质区别。VM运行在VMX non-Root Mode,Guest无须再采用特权级压缩方式,Guest kernel可以直接运行在VMX non-Root Mode的ring 0中,如图1所示。
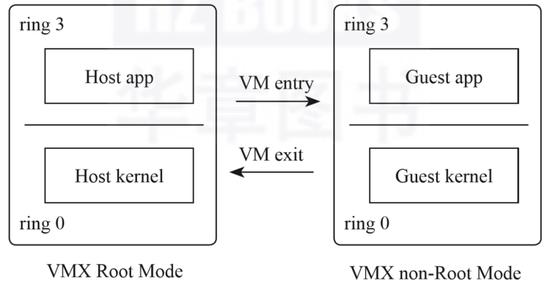
图1 VMX运行模式
处于VMX Root Mode的VMM可以通过执行CPU提供的虚拟化指令VMLaunch切换到VMX non-Root Mode,因为这个过程相当于进入Guest,所以通常也被称为VM entry。
当Guest内部执行了敏感指令,比如某些I/O操作后,将触发CPU发生陷入的动作,从VMX non-Root Mode切换回VMX Root Mode,这个过程相当于退出VM,所以也称为VM exit。
然后VMM将对Guest 的操作进行模拟。相比于将Guest的内核也运行在用户模式(ring 1 ~ ring 3)的方式,支持VMX的CPU有以下3点不同:
1)运行于Guest模式时,Guest用户空间的系统调用直接陷入Guest模式的内核空间,而不再是陷入Host模式的内核空间。
2)对于外部中断,因为需要由VMM控制系统的资源,所以处于Guest模式的CPU收到外部中断后,则触发CPU从Guest模式退出到Host模式,由Host内核处理外部中断。
处理完中断后,再重新切入Guest模式。为了提高I/O效率,Intel支持外设透传模式,在这种模式下,Guest不必产生VM exit,“设备虚拟化”一章将讨论这种特殊方式。
3)不再是所有的特权指令都会导致处于Guest模式的CPU发生VM exit,仅当运行敏感指令时才会导致CPU从Guest模式陷入Host模式,因为有的特权指令并不需要由VMM介入处理。
如同一个CPU可以分时运行多个任务一样,每个任务有自己的上下文,由调度器在调度时切换上下文,从而实现同一个CPU同时运行多个任务。在虚拟化场景下,同一个物理CPU“一人分饰多角”,分时运行着Host及Guest,在不同模式间按需切换,因此,不同模式也需要保存自己的上下文。
为此,VMX设计了一个保存上下文的数据结构:VMCS。每一个Guest都有一个VMCS实例,当物理CPU加载了不同的VMCS时,将运行不同的Guest如图2所示。
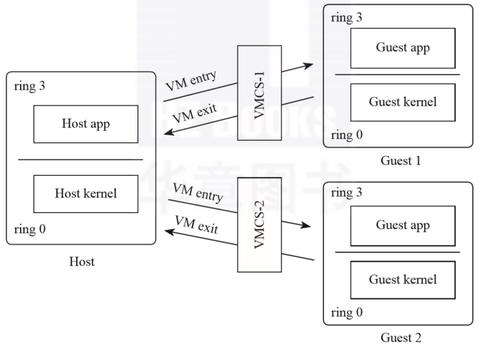
图2 多个Guest切换
VMCS中主要保存着两大类数据,一类是状态,包括Host的状态和Guest的状态,另外一类是控制Guest运行时的行为。其中:
1)Guest-state area,保存虚拟机状态的区域。当发生VM exit时,Guest的状态将保存在这个区域;当VM entry时,这些状态将被装载到CPU中。这些都是硬件层面的自动行为,无须VMM编码干预。
2)Host-state area,保存宿主机状态的区域。当发生VM entry时,CPU自动将宿主机状态保存到这个区域;当发生VM exit时,CPU自动从VMCS恢复宿主机状态到物理CPU。
3)VM-exit information fields。当虚拟机发生VM exit时,VMM需要知道导致VM exit的原因,然后才能“对症下药”,进行相应的模拟操作。为此,CPU会自动将Guest退出的原因保存在这个区域,供VMM使用。
4)VM-execution control fields。这个区域中的各种字段控制着虚拟机运行时的一些行为,比如设置Guest运行时访问cr3寄存器时是否触发VM exit;控制VM entry与VM exit时行为的VM-entry control fields和VM-exit control fields。此外还有很多不同功能的区域,我们不再一一列举,读者如有需要可以查阅Intel手册。
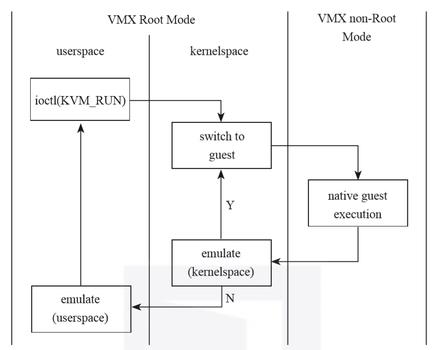
在创建VCPU时,KVM模块将为每个VCPU申请一个VMCS,每次CPU准备切入Guest模式时,将设置其VMCS指针指向即将切入的Guest对应的VMCS实例:
并不是所有的状态都由CPU自动保存与恢复,我们还需要考虑效率。以cr2寄存器为例,大多数时候,从Guest退出Host到再次进入Guest期间,Host并不会改变cr2寄存器的值,而且写cr2的开销很大,如果每次VM entry时都更新一次cr2,除了浪费CPU的算力毫无意义。因此,将这些状态交给VMM,由软件自行控制更为合理。 VCPU生命周期 对于每个虚拟处理器(VCPU),VMM使用一个线程来代表VCPU这个实体。在Guest运转过程中,每个VCPU基本都在如图3所示的状态中不断地转换。 图3 VCPU生命周期 1)在用户空间准备好后,VCPU所在线程向内核中KVM模块发起一个ioctl请求KVM_RUN,告知内核中的KVM模块,用户空间的操作已经完成,可以切入Guest模式运行Guest了。 2)在进入内核态后,KVM模块将调用CPU提供的虚拟化指令切入Guest模式。如果是首次运行Guest,则使用VMLaunch指令,否则使用VMResume指令。在这个切换过程中,首先,CPU的状态(也就是Host的状态)将会被保存到VMCS中存储Host状态的区域,非CPU自动保存的状态由KVM负责保存。然后,加载存储在VMCS中的Guest的状态到物理CPU,非CPU自动恢复的状态则由KVM负责恢复。 3)物理CPU切入Guest模式,运行Guest指令。当执行Guest指令遇到敏感指令时,CPU将从Guest模式切回到Host模式的ring 0,进入Host内核的KVM模块。在这个切换过程中,首先,CPU的状态(也就是Guest的状态)将会被保存到VMCS中存储Guest状态的区域,然后,加载存储在VMCS中的Host的状态到物理CPU。同样的,非CPU自动保存的状态由KVM模块负责保存。 4)处于内核态的KVM模块从VMCS中读取虚拟机退出原因,尝试在内核中处理。如果内核中可以处理,那么虚拟机就不必再切换到Host模式的用户态了,处理完后,直接快速切回Guest。这种退出也称为轻量级虚拟机退出。 5)如果内核态的KVM模块不能处理虚拟机退出,那么VCPU将再进行一次上下文切换,从Host的内核态切换到Host的用户态,由VMM的用户空间部分进行处理。VMM用户空间处理完毕,再次发起切入Guest模式的指令。在整个虚拟机运行过程中,步骤1~5循环往复。 下面是KVM切入、切出Guest的代码: 在从Guest退出时,KVM模块首先调用函数kvm_handle_exit尝试在内核空间处理Guest退出。函数kvm_handle_exit有个约定,如果在内核空间可以成功处理虚拟机退出,或者是因为其它干扰比如外部中断导致虚拟机退出等无须切换到Host的用户空间,则返回1; 否则返回0,表示需要求助KVM的用户空间处理虚拟机退出,比如需要KVM用户空间的模拟设备处理外设请求。 如果内核空间成功处理了虚拟机的退出,则函数kvm_handle_exit返回1,在上述代码中即直接跳转到标签again处,然后程序流程会再次切入Guest。 如果函数kvm_handle_exit返回0,则函数vmx_vcpu_run结束执行,CPU从内核空间返回到用户空间,以kvmtool为例,其相关代码片段如下: 根据代码可见,kvmtool发起进入Guest的代码处于一个for的无限循环中。当从KVM内核空间返回用户空间后,kvmtool在用户空间处理Guest的请求,比如调用模拟设备处理I/O请求。 在处理完Guest的请求后,重新进入下一轮for循环,kvmtool再次请求KVM模块切入Guest。 福利 CSDN 携手【机械工业出版社】送出 《深度探索Linux系统虚拟化:原理与实现》一本 截至11月25日18:00点 作者简介: 王柏生 资深技术专家,先后就职于中科院软件所、红旗Linux和百度,现任百度主任架构师。在操作系统、虚拟化技术、分布式系统、云计算、自动驾驶等相关领域耕耘多年,有着丰富的实践经验。 著有畅销书《深度探索Linux操作系统》(2013年出版)。 谢广军 计算机专业博士,毕业于南开大学计算机系。 资深技术专家,有多年的IT行业工作经验。现担任百度智能云副总经理,负责云计算相关产品的研发。多年来一直从事操作系统、虚拟化技术、分布式系统、大数据、云计算等相关领域的研发工作,实践经验丰富。 以上就是关于gg修改器框架免root中文版_gg修改器免root框架下载及其使用的全部内容,感谢大家的浏览观看,如果你喜欢本站的文章可以CTRL+D收藏哦。[PATCH] kvm: userspace interfacelinux.git/drivers/kvm/vmx.cstatic struct kvm_vcpu *vmx_vcpu_load(struct kvm_vcpu *vcpu){ u64 phys_addr = __pa(vcpu->vmcs); int cpu; cpu = get_cpu; … if (per_cpu(current_vmcs, cpu) != vcpu->vmcs) { … per_cpu(current_vmcs, cpu) = vcpu->vmcs; asm volatile (ASM_VMX_VMPTRLD_RAX "; setna %0" : "=g"(error) : "a"(&phys_addr), "m"(phys_addr) : "cc"); … } …}

[PATCH] kvm: userspace interfacelinux.git/drivers/kvm/vmx.cstatic int vmx_vcpu_run(struct kvm_vcpu *vcpu, …){ u8 fail; u16 fs_sel, gs_sel, ldt_sel; int fs_gs_ldt_reload_needed;again: … /* Enter guest mode */ "jne launched
" ASM_VMX_VMLAUNCH "
" "jmp kvm_vmx_return
" "launched: " ASM_VMX_VMRESUME "
" ".globl kvm_vmx_return
" "kvm_vmx_return: " /* Save guest registers, load host registers, keep flags */ … if (kvm_handle_exit(kvm_run, vcpu)) { … goto again; } } return 0;}
Dump KVM_EXIT_IO detailskvmtool.git/kvm.cint main(int argc, char *argv[]){ … for (;;) { kvm__run(kvm); switch (kvm->kvm_run->exit_reason) { case KVM_EXIT_IO: … } …}

GG修改器破解版下载,GG游戏修改器破解版免费下载 大小:15.17MB10,811人安装 无需root权限,已汉化成中文 1、首先打开修改器,再进入游戏。 2、点击修改器浮标切……
下载
用gg游戏修改器修改愤怒小鸟,愤怒小鸟升级魔法:用gg游戏修改器让你成为强大的指挥官 大小:14.30MB9,628人安装 愤怒小鸟是一款由Rovio公司开发的休闲游戏,在全球范围内都受到了很多玩家的喜爱。……
下载
我的勇者GG修改器免root下载,我的勇者GG修改器脚本 大小:5.17MB10,694人安装 一个人几乎能够在任何他怀有无限热忱的事情上成功。 大家好,今天小编为大家分享关……
下载
gg修改器免root克隆不了_gg修改器免root版贴吧 大小:10.05MB10,523人安装 大家好,今天小编为大家分享关于gg修改器免root克隆不了_gg修改器免root版贴吧的内……
下载
gg游戏修改器会不会被封号,GG游戏修改器的强大功能 大小:15.09MB9,569人安装 GG游戏修改器是目前市面上最流行的游戏修改器之一。它的功能十分强大,可以让玩家轻……
下载
gg修改器苹果最新版下载,GG修改器苹果最新版 下载独享无限畅玩 大小:10.85MB9,723人安装 无论是手机游戏还是电脑游戏,都有一些难以攻克的关卡,让玩家十分头疼。解决这些问……
下载
gg修改器中文下载怎么用_GG修改器下载中文 大小:7.97MB10,766人安装 大家好,今天小编为大家分享关于gg修改器中文下载怎么用_GG修改器下载中文的内容,……
下载
gg修改器虚拟空间怎么root,GG修改器虚拟空间是什么? 大小:19.85MB9,732人安装 GG修改器虚拟空间是一款帮助用户修改游戏内存的工具软件,其内置虚拟空间可以让用户……
下载
gg修改器不root下载_gg修改器免root版下载教程 大小:10.85MB10,485人安装 大家好,今天小编为大家分享关于gg修改器不root下载_gg修改器免root版下载教程的内……
下载
gg修改器noroot,GG修改器无需Root,让你畅玩游戏 大小:16.80MB9,422人安装 随着游戏的发展,越来越多的游戏采用付费道具或装备来增强玩家的游戏体验。很多玩家……
下载