
GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器专属框架中文版_gg修改器可用的框架的内容,赶快来一起来看看吧。
机器之心专栏
作者:奇虎360人工智能研究院和清华大学
对于中文社区来说,本文提出的大规模跨模态基准数据集无疑很有价值
视觉语言预训练(VLP)主要学习视觉与自然语言之间的语义对应关系。得益于海量数据、Transformer 等优秀架构、CLIP 等跨模态模型以及硬件设备的支持,一系列开创性的工作探索了 VLP 模型,并在各种视觉语言任务上取得了显著进展。
借助大规模训练语料库(主要是英语),众多 VLP 模型已被证明对下游任务有益。然而中文视觉语言数据集很少,并且存在各种局限性。针对大规模预训练模型加下游任务精调的经典模式,中文跨模态领域缺少一个包含大量优质数据,且完整定义了预训练数据集、多个下游任务训练集及下游任务测试集的数据基准。
如何构建一个完整、公平且具有高质量文本描述的中文跨模态基准成为一个亟需解决的问题。
最近,奇虎 360 人工智能研究院和清华大学的研究者在其最新论文中重点关注了大规模视觉语言数据集和跨模态表征学习模型。研究者提出了一个大规模中文跨模态基准数据集 Zero,它包含了两个被称为 Zero-Corpus 的预训练数据集和五个下游任务数据集,一定程度上填补了中文图文跨模态领域数据集的空白。进一步,研究者们还提出了一个视觉语言预训练框架 R2D2,用于大规模跨模态学习,基于所提出的 Zero-Corpus 数据集进行预训练,并在多个下游任务上进行测试,R2D2 取得了多项超越 SOTA 的结果。上述数据集和模型,均已开源。
研究者还尝试用更大的 2.5 亿内部数据集训练 R2D2 模型,相对 2300 万数据,模型效果依然有显著提升。特别是在零样本任务上,相对此前的 SOTA,在 Flickr30k-CN 数据集上,R@M 提升到 85.6%(提升了 4.7%),在 COCO-CN 数据集上,R@M 提升到 80.5%(提升了 5.4%),在 MUGE 数据集上,R@M 提升到 69.5%(提升了 6.3%)。

论文地址:https://arxiv.org/pdf/2205.03860.pdf
Zero-Corpus 预训练数据集是由一个包含 2300 万图文对的完整版本和一个包含 230 万图文对的更小子集版本组成。其中,完整的预训练数据集从搜索引擎中收集,包含有图像和对应的文本描述,并根据用户点击率(CTR)从 50 亿个图文中过滤得到。在完整版本上训练 VLP 模型可能需要大量的 GPU 资源,因此为便于学术研究,研究者还提供了具有完整版本 10% 图文对的子集 230 万版本。
除了两个预训练数据集之外,研究者还为长短文本的图文检索和图文匹配任务提供了五个高质量的下游数据集。特别值得一提的是 Flickr30k-CNA,它是一个经过人工翻译的比 Flickr30k-CN 更准确的数据集,可被用来对比中英文跨模态模型的效果,也可以用来研究翻译语料质量对于结果的影响。
对于 VLP 模型,研究者提出了一个用于跨模态学习的全新预训练框架 R2D2。这个框架将双塔模型和单塔模型结合,在图像模态表示和文本模态表示的基础上,利用交叉注意力机制,融合图文信息,并受推荐系统和在线广告等技术的启发,使用全局对比预排序(Global Contrastive Pre-Ranking, GCPR)来获得跨模态表示,最终使用细粒度排序(Fine-Grained Ranking, FGR)进一步提升模型性能。
进一步,研究者还介绍了一种双向蒸馏方法,包括目标导向型蒸馏(Target-guided Distillation,TgD)和特征导向型蒸馏(Feature-guided Distillation,FgD)。其中,目标导向型蒸馏提升了从噪声标签中学习的稳健性,特征导向型蒸馏旨在提升 R2D2 的泛化性。
数据集概览
预训练数据集 Zero Corpus
现有数据收集方法存在两个主要的局限。其一,仅通过爬取方式收集到的图文对图文对应关系较弱,存在较大噪声;其二,图像往往只包含一个对应文本,文本数据缺乏多样性。
为了克服上述局限,研究者为中文图文预训练创建了一个新数据集——Zero Corpus。他们对图像搜索引擎中的 50 亿张图像,按照用户点击进行排序,排序靠前的图片表明用户查询时点击次数最多,说明该图片和搜索查询文本最相关。进一步,研究者还删除了不恰当和有害的文本描述,并过滤掉有害的图片。上述流程,最大程度提高了图片和文本数据的对应关系,过滤得到高质量图片。研究者依照上述方式共处理得到大约 2.5 亿最相关且高质量的图文对,最终随机抽取其中 2300 万个图文对用于构建公开预训练数据集。
研究者还为每个图像提供了多样化的文本描述,包括标题(Title)、内容(Content)和图像查询词(ImageQuery)等。这些包含多个文本在内的信息,可以用于构建不同的跨模态任务,便于更全面地建模和研究图文之间的跨模态关系。下图显示了一些具体例子。

Zero-Corpus 图文对示例。
下游数据集
为了评估预训练模型的性能,大多数工作都会在各种下游数据集上进行实验。与现有具有英文描述的下游数据集相比,带有中文文本的下游数据集很少。
为此,研究者构建了四个中文图文数据集,分别是 ICM、IQM、ICR 和 IQR。在预训练数据处理基础上(经过点击次数排序,以及优质内容过滤),进一步通过人工标记这些下游任务的标签,保证数据的准确性。对于每个下游任务数据集,按照 8:1:1 的比例划分训练集、验证集和测试集。与预训练数据不同的是,这些下游任务的数据集,每个图像只保留一个对应的文本。
图像标题匹配数据集(Image-Caption Matching Dataset, ICM)用于长文本图文匹配分类任务。每个图像具有一个对应的标题文本,对图像进行详细描述。研究者首先使用 CTR 选择最相关的对,然后通过人工标注校准,共获得了 40 万个图文对,包括 20 万个正样本和 20 万个反样本。
图像查询匹配数据集(Image-Query Matching Dataset, IQM)用于短文本图文匹配分类任务。与 ICM 数据收集方式相近,只是使用了搜索查询来替代详细的描述文本。IQM 同样包含 20 万个正样本和 20 万个反样本
图像标题检索数据集(Image-Caption Retrieval Dataset, ICR)用于长文本图文互检任务。研究者采用与 ICM 相同的规则收集了 20 万个图文对。
图像查询检索数据集(Image-Query Retrieval Dataset, IQR)用于短文本图文互检任务。研究者采用与 IQM 相同的规则收集了 20 万个图文对。

从左到右依次为 ICM、IQM、ICR 和 IQR 数据集中的图文示例。
此前的 Flickr30k-CN 使用机器翻译翻译了 Flickr30k 的训练集和验证集,但机器翻译的结果普遍存在两类问题。一方面,部分句子存在一定的翻译错误;另一方面,一些句子的中文语义并不通顺。
因此,研究者邀请了六位中英文语言学专业人士重新翻译了 Flickr30k 的所有数据,并对每个句子进行了双重检查,最终生成新数据集 Flickr30k-Chinese All(Flickr30k-CNA),用于进行图文跨模态任务评测。

Flickr30k、Flickr30k-CN 和本文提出的 Flickr30k-CNA 的示例对比。
方法概述
模型架构
下图 1 为 R2D2 预训练框架的架构概览,它包含一个文本编码器、一个图像编码器和两个交叉编码器。其中,文本编码器和图像编码器分别将文本和图像转换为隐藏状态的序列。然后,文本和图像隐藏状态通过交叉注意力在两个交叉编码器中交互。
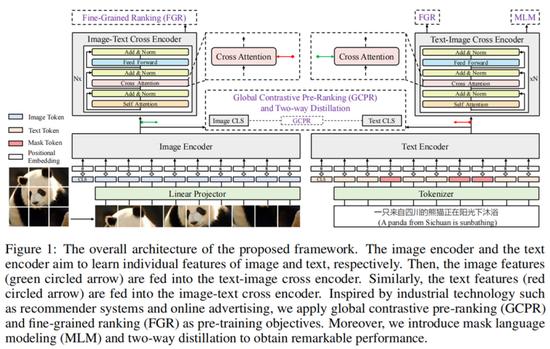
研究者使用 RoBERTa 作为文本编码器。给定文本序列,他们首先使用 RoBERTa-wwm-ext 的 tokenizer 进行 tokenize 处理。在这里,特殊的[CLS] token 被附加到 tokenized 文本的 head,同时[SEP] token 被附加到 tail。然后,tokenized 文本被输入到文本编码器中。
研究者使用 ViT 作为图像编码器。他们首先将输入图像缩放到标准尺寸,并将该图像分成多个 patch。然后每个 patch 进行线性映射并添加位置嵌入。此外,一个可学习的[CLS] token 与 patch 向量串联。最后,序列向量被输入到标准 Transformer 模型以获得图像隐藏状态向量。
研究者将图像和文本隐藏向量融合并输入到交叉编码器。具体来说,他们使用线性映射层来更改每个文本特征和图像特征的维度以使它们保持一致。多层 Transformer 借助交叉注意力融合了两种模态的特征信息,并产生了最终的跨模态输出。
预训练方法
为了探索图文对之间的匹配关系,研究者设计了一种预排序 + 排序的机制,即全局对比预排序(GCPR)和细粒度排序(FGR)。他们还采用掩码语言建模(MLM)有效地学习跨模态模型的表示。
首先是全局对比预排序。传统的对比学习旨在对齐多模态数据的表示(如成对图文),它最大化了正对的相似度分数并最小化了负对的分数。研究者则使用全局对比学习来完成预排序任务,他们在 k 个 GPU 上执行完整的反向传播。对于每个图像 I_i 和对应的文本 T_i,图文和文图的 softmax 归一化相似度分数可以如下定义:

全局对比预排序损失通过交叉熵损失 L_c(·)来计算,如下公式 (2) 所示:
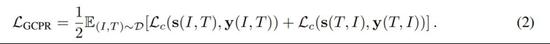
然后是细粒度排序。如上所述,研究者使用全局对比预排序来获得图像和文本的单个表示。基于这些表示,进一步借助细粒度排序损失来执行细粒度排序任务。这是一个二元分类任务,旨在预测图文是否匹配。
研究者将 h_I_[CLS] 和 h_T_[CLS]作为两个交叉编码器的输出表示。给定一个图像表示 h_I_[CLS]和一个文本表示 h_T_[CLS],研究者将它们输入到一个全连接层 g(·)以得到各自的预测概率。令 y 表示为二元分类的 ground-truth 标签,研究者对细粒度排序损失进行如下的计算。
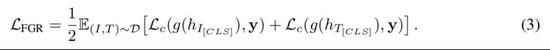
研究者将掩码语言建模损失应用于文图交叉编码器,以提高在 token 级别建模文本和图像之间关系的能力。15% 的文本 token 在输入中被遮盖,所有这些 token 被替换成了[MASK] token。
在研究者的模型中,掩码语言建模任务利用掩码文本和对应的图像一起进行去噪,从而增强了文本和图像之间的交互。由于细粒度排序严重依赖这种交互能力,因此研究者提出了增强训练(ET),它将掩码语言建模任务集成到了正向图文对的细粒度排序前向操作中。
双向蒸馏
大部分图文预训练数据由半自动化程序所收集,从而导致其数据带有噪声。不准确的标签可能会误导模型训练。为此,研究者提出目标导向型蒸馏(TgD),一种带软目标的基于教师 – 学生的蒸馏。为了进一步提高预训练模型的泛化性能,研究者引入了特征导向型蒸馏(FgD)。为方便起见,他们将这两种蒸馏的组合称为双向蒸馏(TwD)。
目标导向型蒸馏:为了降低从噪声标签中学习的风险,研究者建议采用动量更新编码器产生的软目标(soft target)。这里,动量更新编码器作为蒸馏的教师模型,由指数移动平均权重得到。
研究者通过系数 α 将相似度得分 s(·,·) 与 one-hot 标签 y(·,·) 相结合,以生成最终的 soft 标签。将
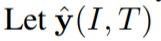
和
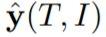
表示为最终 soft 标签。以
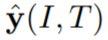
为例,可定义为:
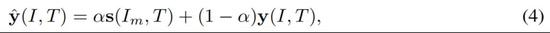
考虑到队列中特征的有效性随着时间步长的增加而降低,研究者还维护了一个加权队列 w 来标记相应位置特征的可靠性。具体来说,除了新传入的项之外,该研究每次迭代都将队列中的每个元素衰减 0.99 倍。因此,研究者将
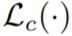
替换为等式 2 中的加权交叉熵损失
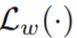
。使用目标导向型蒸馏,
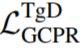
定义为:
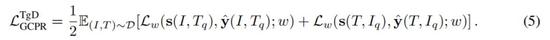
特征导向型蒸馏:与 TgD 类似,研究者采用教师 – 学生范式进行特征导向型蒸馏。以文本编码器为例,学生模型是文本编码器,而教师模型是通过动量更新的编码器。
为了进一步提高模型性能,研究者对输入采用掩码策略。在具体实现中,将完整的输入提供给教师模型,将经过遮盖的输入提供给学生。依靠动量机制,目标是让学生的特征更接近教师的特征。形式上,教师和学生模型的预测分布分别定义如下:
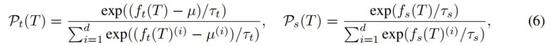
研究者利用交叉熵损失进行特征导向型蒸馏,损失 L_FgD 定义为:
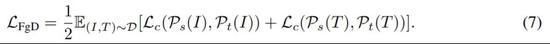
最后用整体预训练目标进行模型训练:
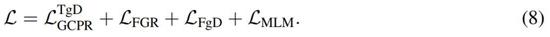
实验结果
从下表 2 中可以看出,研究者提出的模型在绝大多数任务中都超越了此前的 SOTA,即使仅使用 2.3M 样本(约为 Wukong 数据大小的 2.3%)进行训练时也是如此。对 23M 样本进行预训练时,结果更好。在模型层面,R2D2ViT-L 也在所有数据集中都优于 R2D2ViT-B,表明随着预训练模型变大,算法效果会变好。
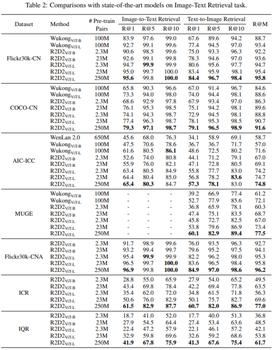
研究者还在所提出的下游数据集上进行实验,这些实验结果成为所提出数据集的基线。特别地,在 Flickr30k-CNA 上进行实验时,研究者使用 Flickr30k-CNA 的训练集精调预训练模型,并在 Flickr30k-CN 的测试集上测试以进行公平比较。从表 2 可以看出,在 Flickr30k-CNA 上微调的 R2D2 优于在 Flickr30k-CN 上微调的 R2D2,因为人工翻译的 Flickr30k-CNA 的质量远高于机器翻译的 Flickr30k-CN。
与图文检索不同,有关中文的图文匹配 (ITM) 任务的数据集很少。研究者提出了针对中文 ITM 任务的图像标题匹配数据集 (ICM) 和图像查询匹配数据集(IQM),并给出了相应的结果。
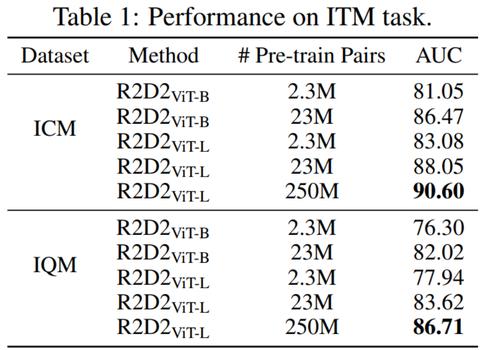
研究者使用了 AUC 作为评价指标。从下表 1 中可以看出,R2D2ViT-L 比 R2D2ViT-B 取得了更好的结果。此外,R2D2ViT-L (23M) 在 ICM 和 IQM 上的表现分别比 R2D2ViT-L (2.3M) 高出约 4.97% 、5.68%。这意味着更多的中文高质量数据能够提高 R2D2 的泛化能力。
为了进一步提高性能,研究者用从 50 亿样本中提取的 2.5 亿个图文对进行预训练。从表 2 可以看出,以最综合的评估指标 R@M 来衡量,该模型在 Flickr30k-CN、COCO-CN、AIC-ICC、MUGE、Flickr30k-CNA、ICR、IQR 等数据集的所有结果中都超过了 23M 数据训练的模型,这意味着增加数据量可以增强预训练模型的能力。同时,这些结果也显著超越了有公开结果批露的 WenLan2.0 以及 WuKong 的结果,成为最新的 SOTA。下表 1 中数据则展示了在图文匹配任务 ICM、IQM 中,更大量的数据训练的预训练模型会取得更好的结果。
为了表明各个机制的作用,研究者在 Zero-Corpus 的子集上(230 万图文预训练数据)进行消融实验。为方便起见,在消融实验中研究者将 R2D2ViT-L 定义为 R2D2。
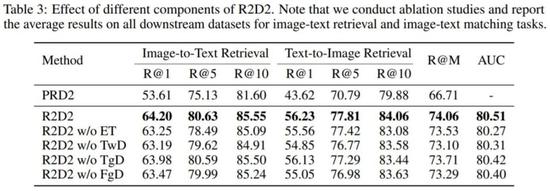
细粒度排序 (FGR) 的效果。首先,研究者使用全局对比预排序(GCPR)和双向蒸馏(TwD)训练模型,并定义为 PRD2。PRD2 的设置类似于 CLIP。从下表 3 的第一行和第二行可以看出,R2D2 在图文检索任务上的表现显著优于 PRD2,可以推测出该结果显著好于 CLIP,这说明了提出的全局对比预排序 + 细粒度排序框架的有效性。
增强训练 (ET) 的效果。研究者对比了去掉增强训练后的结果。从下表 3 的第三行可以看出,R2D2 (带 ET) 在图文检索任务上使 recall@1 提高了 0.95%,AUC 从 80.27% 提高到 80.51%。R2D2 的另一个优点是比 R2D2 w/o ET 使用更少的计算资源。R2D2 需要 154.0 GFLOPs 计算量,能够以每秒 1.4 次迭代的速度运行,而没有增强训练的 R2D2 则需要 168.8 GFLOPs 计算量,每秒只能运行 1.1 次迭代。上述结果证明了增强训练的有效性。
双向蒸馏的效果。研究者提出的双向蒸馏包含了目标导向型蒸馏和特征导向型蒸馏。当移除双向蒸馏(TwD)时,R@M 从 74.06% 降到 73.10%,AUC 从 80.51% 降到 80.31%。当移除特征导向型蒸馏(FgD)时,R@M 从 74.06% 降到 73.29%,性能下降明显,说明在训练中进行特征对齐很重要。同时,移除目标导向型蒸馏(TgD)也会导致模型的性能下降。上述结果说明双向蒸馏是一种提升预训练模型泛化性的有效方法。
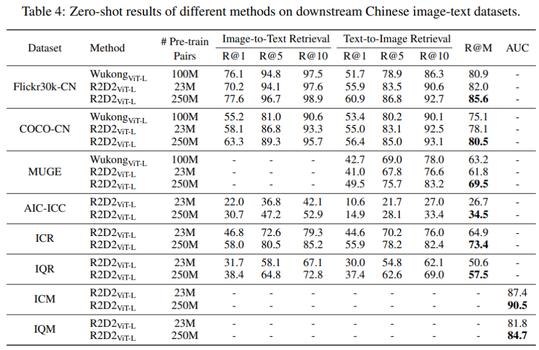
零样本任务。为了证明模型的泛化性能,研究者还进行了零样本迁移实验。从下表 4 中可以看出,与目前 SOTA 性能的 WukongViT-L 相比,R2D2ViT-L(23M)仅使用了不到 1/4 的数据,却在 Flickr30k-CN、COCO-CN 上都取得了更好的性能。当引入 2.5 亿级别的预训练数据时,R2D2 的精度获得进一步提升,相对 WukongViT-L,在 Flickr30k-CN 数据集上,R@M 提升到 85.6%(提升了 4.7%),在 COCO-CN 数据集上,R@M 提升到 80.5%(提升了 5.4%),在 MUGE 数据集上,R@M 提升到 69.5%(提升了 6.3%)。
基于实体的图像注意力可视化。在本实验中,研究者尝试在 COCO-CN 上可视化图像的注意力。具体来说,他们首先从中文文本中提取一个实体,并计算图像与实体对的注意力得分。下图 2 展示了四个不同实体在图像上的可视化解释。这表明 R2D2 很好地学会了将文本与图像中的正确内容对齐。
以上就是关于gg修改器专属框架中文版_gg修改器可用的框架的全部内容,感谢大家的浏览观看,如果你喜欢本站的文章可以CTRL+D收藏哦。

gg助手修改器免root_Gg修改器最新版 大小:7.91MB10,602人安装 大家好,今天小编为大家分享关于gg助手修改器免root_Gg修改器最新版的内容,赶快来……
下载
gg修改器下载中文v99_gg修改器下载中文迷你世界 大小:9.99MB10,623人安装 大家好,今天小编为大家分享关于gg修改器下载中文v99_gg修改器下载中文迷你世界的内……
下载
这是我的战争gg修改器中文,这是我的战争gg修改器中文:让你轻松畅玩游戏 大小:5.85MB9,474人安装 在许多游戏中,我们经常会遇到难以攻克的关卡、恼人的繁琐操作等等问题,而这些问题……
下载
GG修改器一拳超人,一拳超人gg修改器脚本 大小:13.91MB10,735人安装 GG修改器教程(以少女咖啡枪为例) 1.1 设置内存范围 选择内存范围改为图一图二 有用……
下载
gg修改器 免root视频_gg修改器免root视频 大小:19.60MB10,652人安装 大家好,今天小编为大家分享关于gg修改器 免root视频_gg修改器免root视频的内容,赶……
下载
gg修改器一定要用root么_gg修改器需要root 大小:6.95MB10,673人安装 大家好,今天小编为大家分享关于gg修改器一定要用root么_gg修改器需要root的内容,……
下载
华为 gg修改器免root_华为能用gg修改器吗 大小:14.71MB10,592人安装 大家好,今天小编为大家分享关于华为 gg修改器免root_华为能用gg修改器吗的内容,赶……
下载
在哪下载gg修改器最新版,在哪下载gg修改器最新版? 大小:3.27MB9,537人安装 GG修改器是一款非常出名的游戏辅助工具,可以帮助玩家修改游戏内的各种参数,让游戏……
下载
GG修改器免root版32位,GG修改器免root版32位最好的游戏辅助工具 大小:10.26MB9,457人安装 作为游戏爱好者,大家都知道游戏辅助工具的重要性。而GG修改器免root版32位则是最好……
下载
root如何打开gg修改器,使用root来打开GG修改器:多重效用的完美融合 大小:12.23MB9,291人安装 在安卓设备中使用第三方应用和软件是一件很平常的事情。而其中一款备受欢迎的应用就……
下载