GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器的框架下载中文版_专用gg修改器框架官网下载的内容,赶快来一起来看看吧。
机器之心发布
机器之心编辑部
LiBai(李白)模型库覆盖了 Hugging Face、Megatron-LM、DeepSpeed、FairSeq 这些所有主流 Transformer 库的优点,让大模型训练飞入寻常百姓家。
大模型多了去了,告诉我怎么加速?自 2018 年 BERT 诞生,到 GPT-3、ViT 等拥有数以亿计的参数规模的模型不断涌现,AI 模型参数量的爆发式增长已不足为奇,让炼丹师无暇顾及甚至感到麻木。
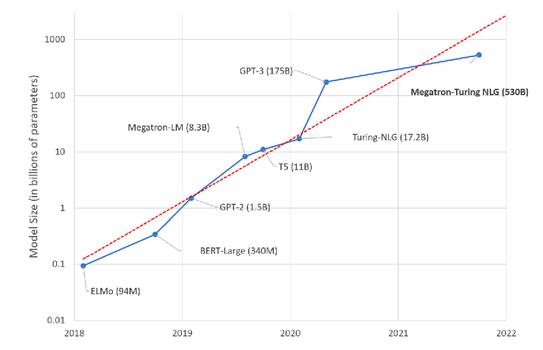
与此同时,大模型对计算和内存资源提出了巨大的挑战。训练成本急剧上升,比如用一块非常先进的 NVIDIA A100 GPU 训练千亿参数模型的 GPT-3,需要用时 100 多年。
大模型对显存的需求增长远超过 GPU 显存增长的速度,根据 OpenAI 的报告,模型大小的增长速度是每 3.5 月翻一倍,而 GPU 显存则需要 18 个月才能翻倍。受限于 GPU 显存,单个 GPU 无法再容纳大规模模型参数。
因此,业内不得不将计算扩展到多个 GPU 设备上,分布式训练则成为广大开发者的必然选择。
但是分布式训练的门槛太高,即便拥有充足的计算资源,也可能因为搞不定分布式训练而望洋兴叹。分布式并行编程通常需要工程师了解计算机系统和架构的专业知识,再加上相关的实践经验,这进一步增加了探索前沿算法和新模型的难度。凡此种种,使得大模型成为部分科技巨头的特权。如何加速模型训练效率,让更多工程师可以使用、研究大模型成为当务之急。
问题是,市面上那么多支持分布式训练的模型库,选哪个最合适?
近期,由一流科技团队研发的以高效性起家的国产开源深度学习框架 OneFlow 上线了 LiBai(李白)模型库,这个新生代模型库覆盖了 Hugging Face、Megatron-LM、DeepSpeed、FairSeq 这些所有主流 Transformer 库的优点,分布式训练性能一如既往地力压群雄,更重要的是,全局视角编程最大程度降低了分布式使用门槛,让大模型训练飞入寻常百姓家。
LiBai 模型库地址:https:///Oneflow-Inc/libai
那么,它具体是怎么做到的?以下还将从训练性能、易用性等方面对上述分布式训练工具做对比,为你在下一次做分布式训练时的工具选择提供参考指南。
一键自动分布式训练,性能超越 Megatron-LM 和 DeepSpeed
作为一个简单高效的分布式模型训练工具箱,具体而言,LiBai 有如下六大特点:
得益于 OneFlow SBP 原生支持各种并行技术,LiBai 实现了算法描述和并行系统的解耦,仅用 3 万多行代码,它就实现了英伟达 Megatron-LM 和微软 DeepSpeed 两大流行方案共计 10 万行代码才能涵盖的功能 。
数据最具说服力,以下的所有实验数据均在相同的硬件环境、相同的第三方依赖(CUDA、 cuDNN 等)、使用相同的参数和网络结构下,全面对比了 LiBai 和 Megatron-LM 在不同模型下的性能表现(所有性能结果均公开且可复现,https://libai.readthedocs.io/en/latest/tutorials/get_started/Benchmark.html)。未来,OneFlow 团队会公布更大规模集群上 LiBai 的表现。
数据并行
注:以下每组参数的含义:
DP 数据并行、MP 模型并行、PP 流水并行、2D 并行、3D 并行
fp16:打开混合精度训练 (amp)
nl: num layers (当 Pipeline parallel size = 8 时,为了让每个 stage 有相对数量的 layer 进行计算,我们将 num layers 从 24 调整为 48)
ac: enable activation checkpointing
mb: micro-batch size per gpu
gb: global batch size total
dxmxp,其中:
d = 数据并行度(data-parallel-size)
m = 模型并行度(tensor-model-parallel-size)
p = 流水并行度(pipeline-model-parallel-size)
1n1g 表示单机单卡,1n8g 表示单机 8 卡, 2n8g 表示 2 机每机 8 卡共 16 卡, 4n8g 表示 4 机共 32 卡
grad_acc_num_step = global_batch_size / (micro_batch_size * data_parallel_size) 展示的结果为 Throughout
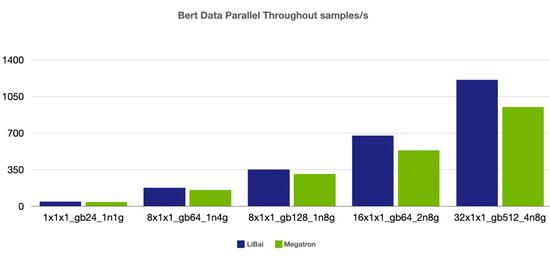
(注:本组 num layers = 24,开启 amp,1n1g micro-batch size = 24, 其余组 micro-batch size = 16)
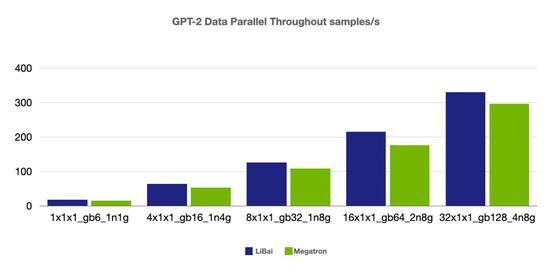
(注:本组 num layers = 24,开启 amp,1n1g micro-batch size = 6, 其余组 micro-batch size = 4)
模型并行
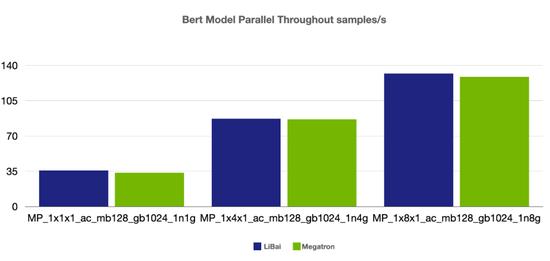
(注:本组 num layers = 24,开启 amp, 开启 activation checkpointing,
micro-batch size = 128, global batch size = 1024, grad acc step = 8)
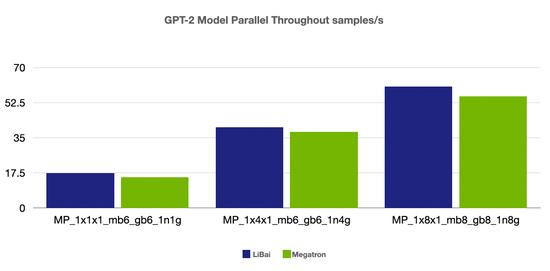
(注:本组 num layers = 24,开启 amp)
流水并行
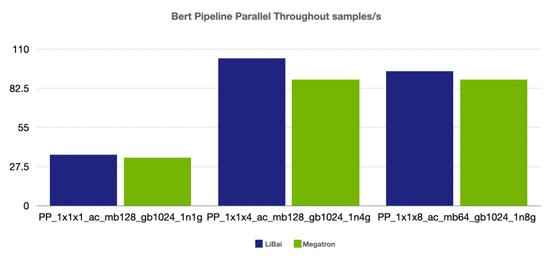
(注:前两组 num layers = 24,grad acc step = 8, 最后一组 num layers = 48, grad acc step = 16,均开启 amp,开启 activation checkpointing)
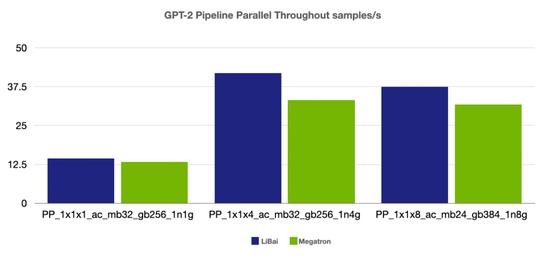
(注:前两组 num layers = 24,grad acc step = 8, 最后一组 num layers = 48, grad acc step = 16,均开启 amp,开启 activation checkpointing)
2-D 并行
数据 + 模型并行
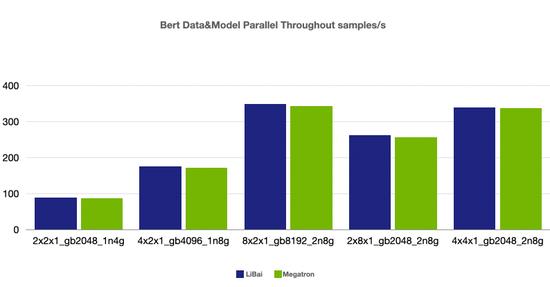
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing, micro-batch size = 128,grad acc step = 8)
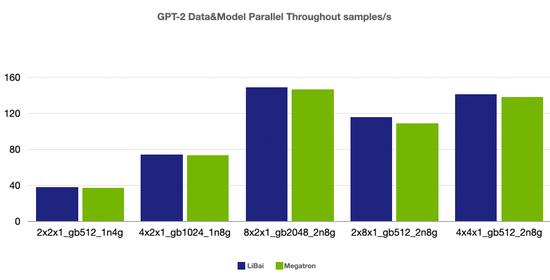
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing, micro-batch size = 32,grad acc step = 8)
数据 + 流水并行
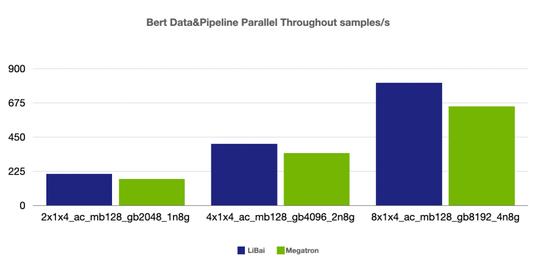
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing, micro-batch size = 128,grad acc step = 8)
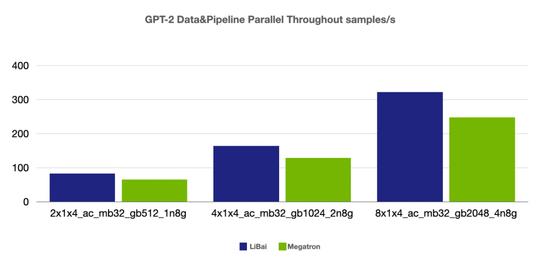
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing, micro-batch size = 32,grad acc step = 8)
3-D 并行
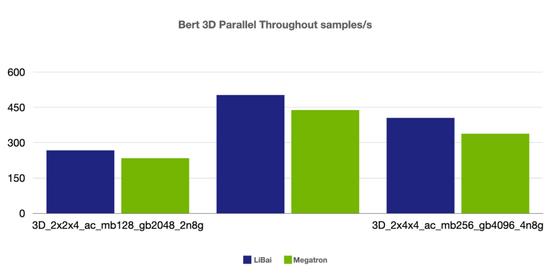
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing,grad acc step = 8)
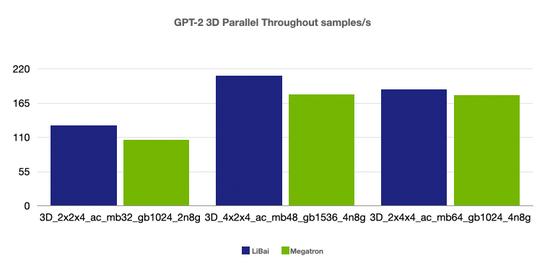
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing,grad acc step = 8)
从上述性能对比数据可以看到,在严格对齐的实验环境下,在 Bert、GPT-2 模型上,LiBai 的训练速度全方位超过 Megatron-LM。
人有我优,人无我有:LiBai vs 其他训练方案
如前所述,为了解决大模型训练的难题,业内已经有 Hugging Face、DeepSpeed 和 Megatron-LM、FairSeq 等流行方案,OneFlow 是否还有必要再研发一个 LiBai 模型库?
接下来,让我们具体比较下上述模型库的优势和不足,也许你就会做出判断。
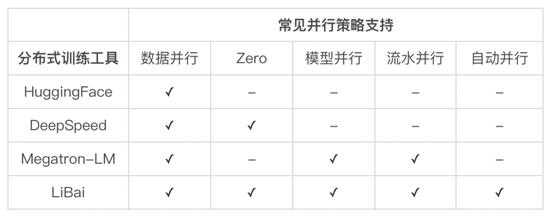
HuggingFace:提供了全面的 SOTA Transformer 模型 ,便于使用预训练好的模型进行微调,提供强大的社区和生态,方便开发者使用预训练好的模型。但它只支持数据并行的方式,如果模型超过单个 GPU 显存容量就不适用了,而且想用它做从零开始训练速度也比较受限。
FairSeq:主要针对序列模型,在 NLP 和 CV 大一统的趋势下,缺少对 CV 模型的支持。
Megatron-LM:基于 PyTorch 实现了数据并行、模型并行和流水并行,性能高,可以用来真正地训练超大规模模型。
不过它做了大量的定制化,对于不熟悉分布式训练的算法工程师而言学习和使用门槛太高,基本上只能被分布式专家所复用。另外,Megatron-LM 提供的模型也远远少于 Hugging Face,使得想使用 PyTorch 复现大模型的工程师都必须要等待其他分布式高手基于 Megatron-LM 实现了自己想用的模型才行。
DeepSpeed:基于 PyTorch 的模型显存优化相关的深度定制库,提供分布式训练、混合精度训练、ZeRO 等技术,可以有效节约内存的开销,使得在数据并行下也可以有效地训练大模型。但是,DeepSpeed 还不支持模型并行,当模型某些层的参数大到超过了单个 GPU 的显存,或是使用 DeepSpeed 的切分方式导致的通信效率不是最优时,最好还是使用模型并行(Tensor 并行、流水并行),此时,只能结合 Megetron-LM 加上侵入原代码的改造来满足需求。
除了作为 PyTorch 生态中实现大模型训练之鼻祖的 Megatron-LM 和 DeepSpeed ,来自国内外的多家知名机构也研发和推出了如 FairSeq 等若干大模型训练库,需要特别指出的是,这些库的分布式核心功能无一例外都是基于 Megatron-LM、DeepSpeed 完成的。
LiBai 模型库的与众不同之处在于,它不是以上任一分布式训练工具的简单升级或包装,而是基于 OneFlow 的分布式和图编译器能力构建的大规模预训练模型开发套件。唯有如此,LiBai 不仅在性能上无出其右,在分布式易用性上更是不遑多让:
看完上述对比,相信 LiBai 也会成为 AI 工程师做分布式训练的绝佳选择,你觉得呢?
LiBai 支持所有常见并行训练策略
分布式训练大模型是个复杂问题,涉及到数据并行(data parallel),模型并行(tensor/model parallel),流水并行(pipeline parallel)等多种并行策略,LiBai 模型库支持这三种常见的并行策略以及这些并行策略的任意组合(并行策略的基本概念:https://docs.oneflow.org/master/parallelism/01_introduction.html)。
自行实现这些并行策略让人十分头疼,比如以前为了使用自动混合精度训练,需要学习配置 Apex;为了支持数据加载流水线,需要学习配置 DALI;为了使用 ZeRO 减少显存占用,需要学习配置 DeepSpeed …… 但用 LiBai 就完全不用担心这类问题,它内置了多种并行策略且具备良好的可扩展性。
以下是 LiBai 中各类并行方法的实例。
万能并行的实现方式
借助 OneFlow 的 SBP 接口,用户可以很方便地根据自身的需求,依照 GPU 的分组排布情况对网络中的输入或者权重进行切分,以实现数据或张量并行。
在 LiBai 的 layers 模块(libai.layers)下,已内置一系列可自适应不同并行策略的网络层,包括常用的 Linear、MLP、Transformer 模块等,使用 LiBai 的 layers 搭建的神经网络, 只需调整配置文件中关于分布式配置的超参,就可以轻松实现纯数据并行、纯张量并行以及数据 & 张量混合并行的训练策略。
关于分布式配置的格式如下:
# mon/train.py
# Distributed arguments
dist=dict(
data_parallel_size=1,
tensor_parallel_size=1,
pipeline_parallel_size=1,
)
通过 data_parallel_size 与 tensor_parallel_size 来控制输入数据与模型权重在不同 GPU 组上的切分方式,当用户使用 LiBai 的内置 layers 模块搭建好神经网络后,可以在自己的训练配置文件中修改分布式超参, 以实现不同的并行训练策略,上图所有值都取为 1 表示在单卡上运行。假设用户拥有一台 8 卡机器,下面介绍一下如何通过修改此配置文件实现数据并行、张量并行以及流水并行训练。
具体操作可参考 LiBai 分布式配置文档:https://libai.readthedocs.io/en/latest/tutorials/basics/Distributed_Configuration.html
纯数据并行 & 纯模型并行
当用户要在 8 卡上进行纯数据(或模型)并行训练, 只需要在训练配置文件中对分布式超参进行覆写即可:
# your config.py
from libai.config import get_config
train = get_config("common/train.py").train
train.dist.data_parallel_size = 8
训练时,在不同的 rank 上会复制一份相同的模型,每个 rank 会分别处理一部分的输入数据, 以实现数据并行训练。
# your config.py
from libai.config import get_config
train = get_config("common/train.py").train
train.dist.tensor_parallel_size = 8
在这种情况下, 模型会自动在 8 个 GPU 上进行切分, 每个 GPU 仅包含整体模型结构的一部分, 以实现模型并行训练。
数据 & 模型混合并行训练
当用户要在 8 卡上进行数据与模型混合并行训练, 只需要在训练配置文件中对分布式超参进行以下简单改动:
# your config.py
from libai.config import get_config
train = get_config("common/train.py").train
train.dist.data_parallel_size = 2
train.dist.tensor_parallel_size = 4
这种情况下, LiBai 会自动对 GPU 进行分组, 我们以 [0, 1, 2, 3, 4, 5, 6, 7] 对 8 个 GPU 进行编号,当设置了 data_parallel_size=2 以及 tensor_parallel_size=4 后,在执行时,会自动将 8 个 GPU 进行分组,可以表示为 [[0, 1, 2, 3], [4, 5, 6, 7]], 其中[0, 1, 2, 3] 为一组,[4, 5, 6, 7]为一组,执行时,会在组之间进行数据并行训练,在组内进行模型并行训练。
流水并行的配置
流水并行的核心概念可以简单总结为:将网络分为多个阶段(stage), 不同的 stage 被分发到不同的 GPU 上, 每个 stage 的计算结果传递给下一个 stage 进行计算,最终按接力的方式完成训练。关于流水并行的具体内容可参考:https://docs.oneflow.org/master/parallelism/01_introduction.html#_6。
朴素流水并行配置
在 LiBai 下可以通过设置 placement 参数,将网络的不同层分配到不同的 GPU 上,placement 参数的值可以通过 libai.utils.distributed 下的 get_layer_placement()接口轻松配置,LiBai 会自动根据配置文件(config)中的分布式配置,来做 stage 的切分,将不同的 placement 自动分配到不同的 stage 上,所以只需要为网络的每一层配置好 placement,再结合分布式配置,便可以轻松实现流水并行配置。
在大部分网络中,往往用一层 Linear 层作为网络的头部(head), 产生网络的最终结果用作分类或者其他任务, 所以以 Linear 层为例, 简要介绍 LiBai 中最简单的流水并行配置方法:
from libai.layers import Linear
self.head = Linear(hidden_size, num_classes)
配置网络模块(module)的 placement
在 LiBai 中可以通过两种方式将一层网络分配到对应的 placement 上:
1、通过 to_global 接口结合 get_layer_placement()来手动指定 placement, 这里通过设置 get_layer_placement(-1)来将 head 层配置到最后一组接力的 placement 上。
from libai.layers import Linear
import libai.utils.distributed as dist
self.head = Linear(hidden_size, num_classes).to_global(placement=dist.get_layer_placement(-1))
2、(mended) 在 libai.layers 中实现的 module 自带 layer_idx 参数, 可以直接设置 layer_idx 参数来指定这一层的 placement
from libai.layers import Linear
self.head = Linear(hidden_size, num_classes, layer_idx=-1)
配置输入数据的 placement
在配置好了网络中模块的 placement 后, 还需要指定输入数据的 placement, 因为只有当输入和网络在同一个 stage 的时候才可以进行计算, 最直观的方式就是为输入和网络配置相同的 placement, 可以结合 to_global 与 get_layer_placement()实现:
class MyModule(nn.Module):
def __init__(self, ... *, layer_idx):
...
self.layer_idx = layer_idx
...
def forward(self, input_data):
input_data = input_data.to_global(placement=dist.get_layer_placement(self.layer_idx))
...
结合配置文件轻松实现朴素流水并行
在配置好网络中不同层的 placement 以及输入的 placement 后,在执行流水并行前,用户只需要调整配置文件(config)即可,需要提前知道网络中的层数,并且调整配置文件中的 pipeline_num_layers:
# set the number of pipeline stages to be 2
train.dist.pipeline_parallel_size = 2
# set model layers for pipeline
train.dist.pipeline_num_layers = hidden_layers
1F1B 是在 PipeDream(https://arxiv.org/pdf/1806.03377.pdf)中介绍的一种新的流水并行训练方式,可以更好地节省显存与利用资源。LiBai 也可以比较容易地支持这种 1F1B 的策略(https:///Oneflow-Inc/libai/blob/main/docs/source/tutorials/advanced_tutorials/customize_dataloader.md)
3D 并行的实现
掌握了数据 & 模型混合并行,以及流水并行以后,配置数据 + 模型 + 流水并行也只是综合一下上述各种并行的改动即可。
# your config.py
from libai.config import get_config
train = get_config("common/train.py").train
train.dist.data_parallel_size = 2
train.dist.tensor_parallel_size = 2
train.dist.pipeline_parallel_size = 2
hidden_layers = 8 #网络的层数
train.dist.pipeline_num_layers = hidden_layers
还是以 8 卡作为例子,在设置 data_parallel_size,tensor_parallel_size, pipeline_parallel_size 都为 2 以后,在执行时,模型将根据用户设置的 pinepine_num_layers 在 GPU 上自动进行划分。
以上述配置为例,模型将在 [0, 1, 2, 3] 和[4, 5, 6, 7]号 GPU 上拆分为 2 个 stage。其中,stage0 会在 [0, 2] 和[1, 3]号 GPU 上数据并行;在 [0, 1] 和[2, 3]号 GPU 上模型并行;stage1 会在 [4, 6] 和[5, 7]号 GPU 上数据并行;在 [4, 5] 和[6, 7]号 GPU 上模型并行。
自定义并行训练
根据上文的介绍,LiBai 在 libai/layers / 下提供了封装好的模块供用户调用。通过这些模块的组合,用户可以拼凑出自己的并行网络。
当 LiBai 中的模块无法满足用户需求时,用户也可以非常方便地自定义并行策略。不同于 PyTorch 下需要手工插入 scatter -> forward -> reduce 等一系列复杂的通信操作,在 LiBai 中,用户只需在初始化 tensor 时定义 sbp 和 placement,便可像写单机运行的代码一样跑起来自己的并行代码。(sbp 和 placement 的详情可参考:https://docs.oneflow.org/master/parallelism/04_2d-sbp.html)。
举例来说,在用户进行 4 卡训练时,网络的中间结果有一个 shape 为 (16, 8) 的 2D Parallel 的 tensor 在 GPU 上的划分方式为如下图, 在 LiBai 中。该 tensor 的 placement 分布为 ranks=[[0, 1],[2, 3]],SBP 为 (S[0], S[1]) 或(S[1], S[0])。
[ |
X00 gpu0 | X01 gpu1
--------------------------
X10 gpu2 | X11 gpu3
| ]
其中, Xij 的 shape 都为 (8, 4) 均匀的分布在每张卡上, 如果你想对这个 tensor 加入一些随机噪声,那么在 LiBai 中可以非常方便地加上如下代码:
LiBai 中封装 dist.get_nd_sbp()是为了兼容 1D parallel 的需求,同时 dist.get_layer_placement()是为了方便配置 pipeline parallel。大多数情况下,用户可以直接参照以下代码:
# test.py
import oneflow as flow
from omegaconf import DictConfig
from oneflow import nn
from libai.utils import distributed as dist
cfg = DictConfig(
dict(data_parallel_size=2, tensor_parallel_size=2, pipeline_parallel_size=1))
dist.setup_dist_util(cfg)
class Noise(nn.Module):
def __init__(self):
super().__init__()
self.noise_tensor = flow.randn(
16, 8,
sbp=dist.get_nd_sbp([flow.sbp.split(0), flow.sbp.split(1)]),
placement=dist.get_layer_placement(layer_idx=0)
)
# 也可以换成以下的写法
# self.noise_tensor = flow.randn(
# 16, 8,
# sbp=(flow.sbp.split(0), flow.sbp.split(1)),
# placement=flow.placement("cuda", ranks=[[0, 1],[2, 3]])
# )
def forward(self, x):
return x + self.noise_tensor
Noise = Noise()
x = flow.zeros(
16, 8,
sbp=(flow.sbp.split(0), flow.sbp.split(1)),
placement=flow.placement("cuda", ranks=[[0, 1],[2, 3]])
)
y = Noise(x)
print(f"rank: {flow.env.get_rank()}, global tensor: shape {y.shape} sbp {y.sbp} placement {y.placement}, local tensor shape: {y.to_local().shape}")
运行指令:
python3 -m oneflow.distributed.launch --nproc_per_node 4 test.py
以下显示输出,根据 shape 可以看到每个 rank 下 tensor 的分布,以及在 global 视角下该 tensor 的信息。
rank: 2, global tensor: shape oneflow.Size([16, 8]) sbp (oneflow.sbp.split(axis=0), oneflow.sbp.split(axis=1)) placement oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]]), local tensor shape: oneflow.Size([8, 4])
rank: 3, global tensor: shape oneflow.Size([16, 8]) sbp (oneflow.sbp.split(axis=0), oneflow.sbp.split(axis=1)) placement oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]]), local tensor shape: oneflow.Size([8, 4])
rank: 1, global tensor: shape oneflow.Size([16, 8]) sbp (oneflow.sbp.split(axis=0), oneflow.sbp.split(axis=1)) placement oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]]), local tensor shape: oneflow.Size([8, 4])
rank: 0, global tensor: shape oneflow.Size([16, 8]) sbp (oneflow.sbp.split(axis=0), oneflow.sbp.split(axis=1)) placement oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]]), local tensor shape: oneflow.Size([8, 4])
未来计划
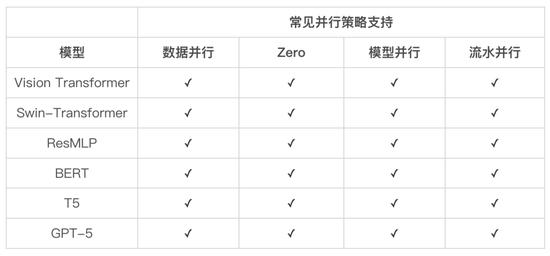
LiBai 目前已支持 BERT、GPT、ViT、Swin-Transformer、T5 等常见模型,以及 MoCoV3、MAE 等最新研究,开箱即用,并且可以很方便地在下游任务上进行微调。
此外,OneFlow 也会更好地兼容 Hugging Face 的模型,接入其生态,同时再利用 OneFlow 自动并行功能,帮助用户享受只写单卡代码即自动扩展到分布式系统的一劳永逸的激爽体验。
未来,在支持更多模型训练的基础上,OneFlow 也会持续完善推理和 Serving 相关的功能,从而打通训练和部署的全流程,让 OneFlow 成为用户的一站式开发平台。
以上就是关于gg修改器的框架下载中文版_专用gg修改器框架官网下载的全部内容,感谢大家的浏览观看,如果你喜欢本站的文章可以CTRL+D收藏哦。
gg修改器很多游戏修改不了,为什么GG修改器是改游戏的不二选择? 大小:8.64MB9,429人安装 很多游戏玩家都喜欢在游戏中使用各种修改器,来让游戏体验更有趣,更丰富。但是,很……
下载
免gg修改器root版框架,如何用免gg修改器root版框架实现完美游戏 大小:6.12MB9,467人安装 在移动游戏中,我们有时会遇到一些困难或者阻碍我们前进的障碍,比如金币不够、能量……
下载
gg修改器安卓下载最新,GG修改器安卓下载最新:让游戏愉悦无比 大小:19.01MB9,556人安装 作为一名游戏爱好者,一定会遇到各式各样的游戏难关和升级瓶颈。这时候,我们最需要……
下载
gg修改器网站怎么变成中文_gg修改器官网怎么调成中文? 大小:5.37MB10,775人安装 大家好,今天小编为大家分享关于gg修改器网站怎么变成中文_gg修改器官网怎么调成中……
下载
gg修改器中文网站,探寻GG修改器中文网站的神奇之处 大小:17.72MB9,750人安装 GG修改器是许多游戏玩家所青睐的一款游戏辅助软件。可是,对于那些不熟悉英语或是被……
下载
gg修改器最新版下载安装,gg修改器最新版下载安装 大小:4.44MB9,803人安装 作为游戏爱好者,我们总是希望在游戏中能够享受更好的体验,但是有些游戏的设定过于……
下载
gg修改器免root,gg修改器免root版中文下载无病毒 大小:4.77MB11,103人安装 gg修改器免root版中文下载无病毒即GG修改器的免root版本,很多玩家在玩游戏的时候由……
下载
GG修改器中文正版_正版GG修改器 大小:13.24MB10,775人安装 大家好,今天小编为大家分享关于GG修改器中文正版_正版GG修改器的内容,赶快来一起……
下载
gg免root使用修改器_GG免root修改器 大小:13.54MB10,927人安装 大家好,今天小编为大家分享关于gg免root使用修改器_GG免root修改器的内容,赶快来……
下载
gg修改器中文版92_gg修改器中文版下载安装 大小:12.97MB10,861人安装 大家好,今天小编为大家分享关于gg修改器中文版92_gg修改器中文版下载安装的内容,……
下载