GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器修改文字游戏_gg修改器的游戏的内容,赶快来一起来看看吧。
最终训练得到四个encoder-decoder模型:

1、PEER-Edit的输入为文本x和一组文档,模型输出为计划和编辑后的文本,其中p为计划文本。
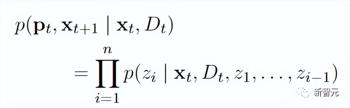
2、PEER-Undo的输入为编辑后的文本和一组文档,模型输出结果为是否撤销该次编辑。
3、PEER-Explain用来生成该次编辑的解释,输入为源文本、编辑后的文本和一组相关文档。
4、 PEER-Document输入源文本、编辑后的文本和计划,模型输出为该次编辑中最有用的背景信息。
PEER的所有变体模型都用来生成合成数据,既生成缺失的部分来补充的训练数据,也用来替换现有数据中的「低质量」部分。
为了能够对任意文本数据进行训练,即使该段文本没有编辑历史,也使用PEER-Undo来生成合成的「后向」编辑,即对源文本反复应用PEER-Undo直到文本为空,再调用PEER-Edit在相反的方向进行训练。
在生成计划时,使用PEER-Explain来修正语料库中许多低质量的评论,或者处理没有评论的文本。从PEER-Explain的输出中随机采样多个结果作为「潜在的计划」,通过计算实际编辑的似然概率,并选择概率最高的作为新计划。
如果对于特定编辑操作无法找到相关文档,则使用PEER-Document生成一组合成的文档,包含执行该次编辑操作的信息。最关键的是,仅在训练PEER-Edit这么做,在推理阶段并不提供任何合成文档。
为了提高生成的计划、编辑和文档的质量和多样性,研究人员还实现了一个控制机制,即在模型被训练生成的输出序列中预置特定的控制标记,然后在推理过程中使用这些控制标记来指导模型的生成,标记包括:
1、type用来控制PEER-Explain生成的文本类型,可选值为instructon(输出必须以不定式开头to ….)和other;
2、length, 控制PEER-Explain的输出长度,可选值包括s(少于2个词), m(2-3个词),l(4-5个词)和xl(多于或等于6个词);
3、overlap, 是否PEER-Explain生成的词可以与编辑文本重复,可选值为true和false;
4、words,用来控制PEER-Undo在源文本和编辑后文本之间不同词的个数,可选值为所有整数;
5、contains,用来确保PEER-Document输出的文本包含某个substring
PEER没有对PEER-edit引入控制符,即没有假定用户可能会用模型解决编辑任务的类型,使得模型更加通用。
在实验对比阶段,PEER使用LM-Adapted T5的3B参数版本预训练初始化。
为了评估了PEER在不同领域中遵循一系列计划、利用所提供的文档和进行编辑的能力,特别是在没有编辑历史的领域中的表现,文中引入了一个新的数据集Natural Edits,一个针对不同文本类型和领域的自然发生的编辑的集合。
数据从三个英文网络资源中收集获得:从维基百科中收集百科全书式的页面,从Wikinews收集新闻文章,从StackExchange的烹饪、园艺、法律、电影、政治、旅游和工作场所子论坛收集问题,所有这些网站都提供了带有评论的编辑历史,这些评论详细说明了编辑的意图,并将其作为计划提供给模型。
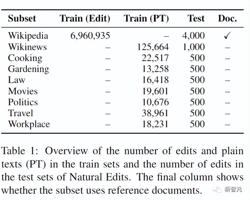
在Wikinews和StackExchange子集的训练中,只提供纯文本数据,而非实际的编辑,从而测试在没有编辑历史的领域的编辑能力。
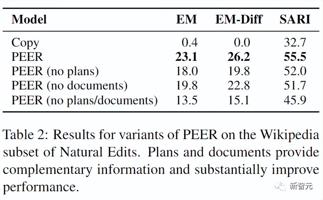
实验结果可以看出PEER的表现在一定程度上超过了所有的基线,并且计划和文档提供了模型能够使用的互补信息
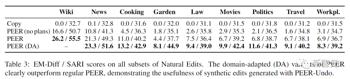
在Natural Edits的所有子集上评估PEER后可以发现,计划对各领域都有很大的帮助,这表明理解维基百科编辑中的计划的能力可以直接转移到其他领域。重要的是,在Natural Edits的所有子集上,PEER的领域适应性变体明显优于常规的PEER,尤其是在园艺、政治和电影子集上有很大的改进(分别为84%、71%和48%的EM-Diff),也显示了在不同领域中应用PEER时,生成合成编辑的有效性。
参考资料:
https://arxiv.org/abs/2208.11663
以上就是关于gg修改器修改文字游戏_gg修改器的游戏的全部内容,希望对大家有帮助。
gg修改器中文版苹果_正版GG修改器苹果 大小:7.24MB12,975人安装 大家好,今天小编为大家分享关于gg修改器中文版苹果_正版GG修改器苹果的内容,赶快……
下载
纵横兔root框架gg修改器,纵横兔root框架gg修改器:带你进入无尽乐趣的世界 大小:17.97MB11,430人安装 作为一个喜欢游戏的人,我们总是期待能够更轻松地卡关、更快地升级、更轻松地学习新……
下载
gg修改器root要不要,为什么GG修改器ROOT是绝佳的选择? 大小:17.50MB11,608人安装 我们都知道,在游戏当中,修改器可以让游戏变得更加有趣。不过,获取ROOT权限并使用……
下载
gg修改器免root咋用_如何用gg修改器免root 大小:3.55MB12,770人安装 大家好,今天小编为大家分享关于gg修改器免root咋用_如何用gg修改器免root的内容,……
下载
gg游戏修改器模拟城市,掌握游戏规则,爽快体验gg游戏修改器模拟城市 大小:17.16MB12,001人安装 例如模拟城市,是一款非常经典的游戏。在这款游戏中,玩家扮演市长,需要全面管理整……
下载
无root的GG修改器_无root如何使用GG修改器 大小:13.72MB12,836人安装 大家好,今天小编为大家分享关于无root的GG修改器_无root如何使用GG修改器的内容,……
下载
gg修改器开挂教程中文,GG修改器游戏助手的必备工具 大小:17.24MB11,856人安装 作为游戏爱好者,我们不仅会享受到游戏带来的乐趣,还会不断探索游戏的内部机制,以……
下载
迷你世界gg修改器下载中文,迷你世界gg修改器下载中文小巧实用的游戏改造工具 大小:14.94MB11,863人安装 如果你是一位迷你世界的忠实玩家,你是否厌倦了无限重复的玩法和缺少趣味的游戏体验……
下载
gg修改器一定要用root么,GG修改器:王者荣耀好帮手 大小:9.04MB11,645人安装 GG修改器是一款广受玩家欢迎的修改工具,尤其是在王者荣耀中,为玩家们提供了极大的……
下载
gg修改器最新版本在哪下载,GG修改器最新版本助你畅游游戏世界 大小:7.04MB11,653人安装 作为一名游戏玩家,你是否曾经碰到过这样的场景,想要在游戏中获得更多资源、更好的……
下载