GG修改器破解版下载地址:https://ghb2023zs.bj.bcebos.com/gg/xgq/ggxgq?GGXGQ
大家好,今天小编为大家分享关于gg修改器对网络游戏有用吗_gg可以修改网游吗的内容,赶快来一起来看看吧。
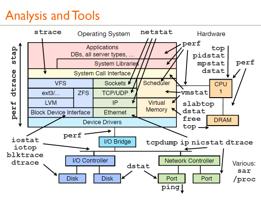
最后一列显示了符号名称。
样本可以使用多种方式进行呈现,即使用排序。例如按共享对象进行排序,使用dso:
perf report –sort=dso
# Events: 1K cycles
#
# Overhead Shared Object
# …….. …………………………
#
38.08% [kernel.kallsyms]
28.23% libxul.so
3.97% libglib-2.0.so.0.2800.6
3.72% libc-2.13.so
3.46% libpthread-2.13.so
2.13% firefox-bin
1.51% libdrm_intel.so.1.0.0
1.38% dbus-daemon
1.36% [drm]
[…]
为使输出更容易解析,可以修改列分隔符为某一个字符:
perf report -t
Perf工具不知道如何从压缩内核映像(vmlinuz)中提取符号。因此,用户必须将非压缩内核镜像的路径通过 -k传递给Perf:
perf report -k /tmp/vmlinux
当然,内核镜像只有带debug符号编译的才能工作。
在per-cpu的模式中,会从监控CPU上的所有线程上记录的样本。 这样,我们可以收集来自许多不同进程的样本。例如,如果我们监视所有CPU 5s:
perf record -a sleep 5
perf report
# Events: 354 cycles
#
# Overhead Command Shared Object Symbol
# …….. …………… …………………….. ………………………………..
#
13.20% swapper [kernel.kallsyms] [k] read_hpet
7.53% swapper [kernel.kallsyms] [k] mwait_idle_with_hints
4.40% perf_2.6.38-8 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
4.07% perf_2.6.38-8 perf_2.6.38-8 [.] 0x34e1b
3.88% perf_2.6.38-8 [kernel.kallsyms] [k] format_decode
[…]
当符号打印为十六进制地址时,这是因为ELF镜像没有符号表。当二进制文件被剥离时就会发生这种情况。我们也可以按cpu排序。这可能有助于确定工作负载是否平衡:
perf report –sort=cpu
# Events: 354 cycles
#
# Overhead CPU
# …….. …
#
65.85% 1
34.15% 0
perf收集调用链时,开销可以在两列中显示为“Children”和“Self”。“self”开销只是通过所有入口(通常是一个函数,也就是符号)的所有周期值相加来计算的。这是perf传统显示方式,所有“self”开销值之和应为100%。
“children”开销是通过将子函数的所有周期值相加来计算的,这样它就可以显示更高级别函数的总开销,即使它们不直接参与更多的执行。这里的“Children”表示从另一个(父)函数调用的函数。
所有“children”开销值之和超过100%可能会令人困惑,因为它们中的每一个已经是其子函数的“self”开销的累积。但是如果启用了这个功能,用户可以找到哪一个函数的开销最大,即使样本分布在子函数上。
考虑下面的例子,有三个函数如下所示。
void foo(void) {
/* do something */
}
void bar(void) {
/* do something */
foo();
}
int main(void) {
bar()
return 0;
}
在本例中,“foo”是“bar”的子级,“bar”是“main”的直接子级,因此“foo”也是“main”的子级。换句话说,“main”是“foo”和“bar”的父级,“bar”是“foo”的父级。
假设所有样本都只记录在“foo”和“bar”中。当使用调用链记录时,输出将在perf report的常规(仅自开销)输出中显示如下内容:
Overhead Symbol
…….. …………………
60.00% foo
|
— foo
bar
main
__libc_start_main
40.00% bar
|
— bar
main
__libc_start_main
启用–children选项时,子函数(即’foo’和’bar’)的’self’开销值将添加到父函数中,以计算’children’开销。在这种情况下,报告可以显示为:
Children Self Symbol
…….. …….. ………………..
100.00% 0.00% __libc_start_main
|
— __libc_start_main
100.00% 0.00% main
|
— main
__libc_start_main
100.00% 40.00% bar
|
— bar
main
__libc_start_main
60.00% 60.00% foo
|
— foo
bar
main
__libc_start_main
在上述输出中,“foo”的“self”开销(60%)被添加到“bar”、“main”和“__libc_start_main”的“children”开销中。同样,“bar”的“self”开销(40%)添加到“main”和“libc”的“children”开销中。
因此,首先显示’__libc_start_main’和’main’,因为它们有相同(100%)的“子”开销(即使它们没有“自”开销),并且它们是’foo’和’bar’的父级。
从v3.16开始,默认情况下会显示“children”开销,并按其值对输出进行排序。通过在命令行上指定–no-children选项或在perf配置文件中添加“report.children=false”或“top.children=false”,禁用“children”开销。
可以使用perf annotate深入到指令级分析。为此,需要使用要解析的命令的名称调用perf annotate。所有带样本的函数都将被反汇编,每条指令都将报告其样本的相对百分比:
perf record ./noploop 5
perf annotate -d ./noploop
————————————————
Percent | Source code & Disassembly of noploop.noggdb
————————————————
:
:
:
: Disassembly of section .text:
:
: 08048484 <main>:
0.00 : 8048484: 55 push %ebp
0.00 : 8048485: 89 e5 mov %esp,%ebp
[…]
0.00 : 8048530: eb 0b jmp 804853d <main+0xb9>
15.08 : 8048532: 8b 44 24 2c mov 0x2c(%esp),%eax
0.00 : 8048536: 83 c0 01 add $0x1,%eax
14.52 : 8048539: 89 44 24 2c mov %eax,0x2c(%esp)
14.27 : 804853d: 8b 44 24 2c mov 0x2c(%esp),%eax
56.13 : 8048541: 3d ff e0 f5 05 cmp $0x5f5e0ff,%eax
0.00 : 8048546: 76 ea jbe 8048532 <main+0xae>
[…]
第一列报告在该指令在捕获函数==noploop()==的样本百分比。如前所述,您应该仔细解读这些信息。
如果使用-ggdb编译应用程序,perf annotate可以生成源代码级信息。下面的代码片段显示了在使用此调试信息编译noploop时,同一次执行noploop时的更多信息输出。
————————————————
Percent | Source code & Disassembly of noploop
————————————————
:
:
:
: Disassembly of section .text:
:
: 08048484 <main>:
: #include <string.h>
: #include <unistd.h>
: #include <sys/time.h>
:
: int main(int argc, char **argv)
: {
0.00 : 8048484: 55 push %ebp
0.00 : 8048485: 89 e5 mov %esp,%ebp
[…]
0.00 : 8048530: eb 0b jmp 804853d <main+0xb9>
: count++;
14.22 : 8048532: 8b 44 24 2c mov 0x2c(%esp),%eax
0.00 : 8048536: 83 c0 01 add $0x1,%eax
14.78 : 8048539: 89 44 24 2c mov %eax,0x2c(%esp)
: memcpy(&tv_end, &tv_now, sizeof(tv_now));
: tv_end.tv_sec += strtol(argv[1], NULL, 10);
: while (tv_now.tv_sec < tv_end.tv_sec ||
: tv_now.tv_usec < tv_end.tv_usec) {
: count = 0;
: while (count < 100000000UL)
14.78 : 804853d: 8b 44 24 2c mov 0x2c(%esp),%eax
56.23 : 8048541: 3d ff e0 f5 05 cmp $0x5f5e0ff,%eax
0.00 : 8048546: 76 ea jbe 8048532 <main+0xae>
[…]
Perf工具不知道如何从压缩内核镜像(vmlinuz)中提取符号。正如perf report中的示例,用户必须通过-k传递非压缩内核镜像的路径:
perf annotate -k /tmp/vmlinux -d symbol
在一次说明,这只使用带debug符号编译的内核。
perf工具可以以类似于Linux top工具的模式运行,实时打印采样函数。默认的采样事件是cycles,默认的顺序是每个符号的采样数递减,因此perf top显示了花费大部分时间的函数。默认情况下,perf top以processor-wide模式运行,在用户和内核级别监视所有在线的CPU。使用-C选项可以只监视CPU的一个子集。
perf top
——————————————————————————————————————————————————-
PerfTop: 260 irqs/sec kernel:61.5% exact: 0.0% [1000Hz
cycles], (all, 2 CPUs)
——————————————————————————————————————————————————-
samples pcnt function DSO
_______ _____ ______________________________ ___________________________________________________________
80.00 23.7% read_hpet [kernel.kallsyms]
14.00 4.2% system_call [kernel.kallsyms]
14.00 4.2% __ticket_spin_lock [kernel.kallsyms]
14.00 4.2% __ticket_spin_unlock [kernel.kallsyms]
8.00 2.4% hpet_legacy_next_event [kernel.kallsyms]
7.00 2.1% i8042_interrupt [kernel.kallsyms]
7.00 2.1% strcmp [kernel.kallsyms]
6.00 1.8% _raw_spin_unlock_irqrestore [kernel.kallsyms]
6.00 1.8% pthread_mutex_lock /lib/i386-linux-gnu/libpthread-2.13.so
6.00 1.8% fget_light [kernel.kallsyms]
6.00 1.8% __pthread_mutex_unlock_t /lib/i386-linux-gnu/libpthread-2.13.so
5.00 1.5% native_sched_clock [kernel.kallsyms]
5.00 1.5% drm_addbufs_sg /lib/modules/2.6.38-8-generic/kernel/drivers/gpu/drm/drm.ko
默认情况下,第一列显示自运行开始以来的总样本数。通过按“Z”键,可以将其更改为打印自上次刷新以来的样本数。当处理器不处于暂停状态(即不空闲)时,cycle事件也会统计CPU周期。因此,这不等于墙面时间。此外,事件还受频率扩展的影响。
也可以深入到单个函数中,查看哪些指令具有最多的样本。要深入到指定函数,请按“s”键并输入函数名。这里我们选择了顶部函数noploop(上面没有显示):
——————————————————————————————————————————————
PerfTop: 2090 irqs/sec kernel:50.4% exact: 0.0% [1000Hz cycles], (all, 16 CPUs)
——————————————————————————————————————————————
Showing cycles for noploop
Events Pcnt (>=5%)
0 0.0% 00000000004003a1 <noploop>:
0 0.0% 4003a1: 55 push %rbp
0 0.0% 4003a2: 48 89 e5 mov %rsp,%rbp
3550 100.0% 4003a5: eb fe jmp 4003a5 <noploop+0x4>
perf bench命令包含多个多线程微内核基准测试,用于在Linux内核和系统调用中执行不同的子系统。这使得黑客可以轻松地测量更改的影响,从而帮助缓解性能衰退。
它还充当一个通用的基准框架,使开发人员能够轻松地创建测试用例、透明进行整合和使用富性能工具子系统。
测量多个任务之间的pipe(2)和socketpair(2)操作。允许测量线程与进程上下文切换的性能。
$perf bench sched messaging -g 64
# Running ’sched/messaging’ benchmark:
# 20 sender and receiver processes per group
# 64 groups == 2560 processes run
Total time: 1.549 [sec]
处理futex内核实现的细粒度方面。它对于内核黑客非常有用。它目前支持唤醒和重新排队/等待操作,并强调私有和共享futexes的哈希方案。下面时nCPU线程运行的一个示例,每个线程处理1024个futex来测量哈希逻辑:
$ perf bench futex hash
# Running ’futex/hash’ benchmark:
Run summary [PID 17428]: 4 threads, each operating on 1024 [private] futexes for 10 secs.
[thread 0] futexes: 0x2775700 … 0x27766fc [ 3343462 ops/sec ]
[thread 1] futexes: 0x2776920 … 0x277791c [ 3679539 ops/sec ]
[thread 2] futexes: 0x2777ab0 … 0x2778aac [ 3589836 ops/sec ]
[thread 3] futexes: 0x2778c40 … 0x2779c3c [ 3563827 ops/sec ]
Averaged 3544166 operations/sec (+- 2.01%), total secs = 10
本节列出了很多建议来避免使用Perf时常见的陷阱。
Perf工具所使用的perf_event内核接口的设计是这样的:它为per-thread或per-cpu的每个事件使用一个文件描述符。
在16-way系统上,当您这样做时:
perf stat -e cycles sleep 1
您实际上创建了16个事件,从而消耗了16个文件描述符。
在per-thread模式下,当您在同一16-way系统上对具有100个线程的进程进行采样时:
perf record -e cycles my_hundred_thread_process
然后,一旦创建了所有的线程,您将得到100*1(event)*16(cpus)=1600个文件描述符。Perf在每个CPU上创建一个事件实例。只有当线程在该CPU上执行时,事件才能有效地度量。这种方法加强了采样缓冲区的局部性,从而减少了采样开销。在运行结束时,该工具将所有样本合计到一个输出文件中。
如果Perf因“打开的文件太多”错误而中止,有以下几种解决方案:
超级用户可以更改进程打开的文件限制,使用 ulimit shell内置命令:
ulimit -a
[…]
open files (-n) 1024
[…]
ulimit -n 2048
ulimit -a
[…]
open files (-n) 2048
[…]
perf record命令在perf.data中保存者与测量相关的所有ELF镜像的唯一标识符。在per-thread模式下,这包括被监视进程的所有ELF镜像。在cpu-wide模式下,它包括系统上运行的所有进程。如果使用-Wl,–build-id选项,则链接器将生成这些唯一标识符。因此,它们被称为build-id。当将指令地址与ELF映像关联时,build id是一个非常有用的工具。要提取perf.data文件中使用的所有生成id项,请发出:
perf buildid-list -i perf.data
06cb68e95cceef1ff4e80a3663ad339d9d6f0e43 [kernel.kallsyms]
e445a2c74bc98ac0c355180a8d770cd35deb7674 /lib/modules/2.6.38-8-generic/kernel/drivers/gpu/drm/i915/i915.ko
83c362c95642c3013196739902b0360d5cbb13c6 /lib/modules/2.6.38-8-generic/kernel/drivers/net/wireless/iwlwifi/iwlcore.ko
1b71b1dd65a7734e7aa960efbde449c430bc4478 /lib/modules/2.6.38-8-generic/kernel/net/mac80211/mac80211.ko
ae4d6ec2977472f40b6871fb641e45efd408fa85 /lib/modules/2.6.38-8-generic/kernel/drivers/gpu/drm/drm.ko
fafad827c43e34b538aea792cc98ecfd8d387e2f /lib/i386-linux-gnu/ld-2.13.so
0776add23cf3b95b4681e4e875ba17d62d30c7ae /lib/i386-linux-gnu/libdbus-1.so.3.5.4
f22f8e683907b95384c5799b40daa455e44e4076 /lib/i386-linux-gnu/libc-2.13.so
[…]
每次运行结束时,perf record命令都会更新一个build id缓存,其中包含带有样本的ELF镜像的新条目。缓存包含:
给定的build-id是不可变的,它们唯一地标识二进制文件。如果重新编译二进制文件,将生成新的build-id,并在缓存中保存ELF图像的新副本。缓存保存在磁盘上的默认目录$HOME/.debug中。系统管理员可以使用全局配置文件==/etc/perfconfig==为缓存指定备用全局目录:
$ cat /etc/perfconfig
[buildid]
dir = /var/tmp/.debug
在某些情况下,关掉 build-id缓存更新可能时有益的。为此,你需要使用perf record的 -n选项 性能记录
perf record -N dd if=/dev/zero of=/dev/null count=100000
对于某些事件,必须是root才能调用perf工具。本文档假定用户具有root权限。如果您试图在权限不足的情况下运行perf,它将报告
No permission to collect system-wide stats.
此功能显示程序在何处睡眠或等待某物的时间和时间。
第一步是收集数据。我们需要收集sched_stat和sched_switch事件。Sched_stat事件是不够的,因为它们是在任务的上下文中生成的,这会唤醒目标任务(例如释放锁)。我们需要相同的事件,但带有目标任务的调用链。此调用链可以从之前的sched_switch事件中提取。
第二步是合并sched_start和sched_switch事件。这可以通过“perf-inject-s”来完成。
$ ./perf record -e sched:sched_stat_sleep -e sched:sched_switch -e sched:sched_process_exit -g -o ~/perf.data.raw ~/foo
$ ./perf inject -v -s -i ~/perf.data.raw -o ~/perf.data
$ ./perf report –stdio –show-total-period -i ~/perf.data
# Overhead Period Command Shared Object Symbol
# …….. ………… ……. …………….. …………..
#
100.00% 502408738 foo [kernel.kallsyms] [k] __schedule
|
— __schedule
schedule
|
|–79.85%– schedule_hrtimeout_range_clock
| schedule_hrtimeout_range
| poll_schedule_timeout
| do_select
| core_sys_select
| sys_select
| system_call_fastpath
| __select
| __libc_start_main
|
–20.15%– do_nanosleep
hrtimer_nanosleep
sys_nanosleep
system_call_fastpath
__GI___libc_nanosleep
__libc_start_main
$cat foo.c
…
for (i = 0; i < 10; i++) {
ts1.tv_sec = 0;
ts1.tv_nsec = 10000000;
nanosleep(&ts1, NULL);
tv1.tv_sec = 0;
tv1.tv_usec = 40000;
select(0, NULL, NULL, NULL,&tv1);
}
…
参考文档:
Linux kernel profiling with perf
补充,三款Linux平台下主流的热点分析工具,分别是GNU gprof、Valgrind和Google perftools,三款工具的主要特点如下表:
|
工具 |
使用命令 |
是否需要重新编译 |
Profiling速度 |
是否支持多线程热点分析 |
是否支持链接库热点分析 |
|
GNU gprof |
./test; gprof ./test ./gmon.out |
是 |
慢 |
否 |
否 |
|
Valgrind |
Valgrind –tool=callgrind ./test |
否 |
非常慢 |
是 |
是 |
|
Google perftools |
LD_PRELOAD=/usr/lib/libprofiler.so CPUPROFILE=./test.prof ./test |
否 |
快 |
是 |
是 |
#include <vector>
#include <iostream>
#ifdef WITHGPERFTOOLS
#include <gperftools/profiler.h>
#endif
using namespace std;
int foo(vector<int> v) {
int result = 0;
for(auto x: v) {
result += x;
}
return result % 1000;
}
int main() {
#ifdef WITHGPERFTOOLS
ProfilerStart(“profile.log”);
#endif
vector<int> v;
v.push_back(1);
int result = 0;
for (int i=0; i<10000; i++) {
result = foo(v);
v.push_back(result);
}
#ifdef WITHGPERFTOOLS
ProfilerStop();
#endif
cout << result << ”
“;
return 1;
}
是GNU G++自带的热点分析工具,使用方法是:1. 使用-pg选项重新编译代码;2. 执行程序./test,生成热点分析结果gmont.out;3.使用gprof查看结果gprof ./test ./gmon.out。因为gprof要求用-pg重新编译代码,需要在Debug模式下进行Profiling,所以速度较慢。另外gprof不支持多线程的热点分析。这个工具另一个大问题是,不支持链接库的热点分析。很多大型项目为了模块化管理会生成很多动态链接库供其他程序调用,如果要分析每个模块的热点,这个工具就不适用了。
测试脚本如下:
#!/bin/bash
# build the program with profiling support (-gp)
g++ -std=c++11 -pg cpuload.cpp -o cpuload
# run the program; generates the profiling data file (gmon.out)
./cpuload
# print the callgraph
gprof cpuload
是一系列工具的套装,包括内存分析、热点分析等。它的使用非常简单,安装好之后,直接调用Vallgrind中的callgrind工具即可,命令为Valgrind –tool=callgrind ./test。使用该工具Profiling无需重新编译代码,也支持多线程和链接库的热点分析,但是由于Profiling原理的特殊性,其Profiling速度非常之慢,比直接运行程序慢了将近50倍,所以并不适合稍大型程序的热点分析。
测试脚本如下:
#!/bin/bash
# build the program (no special flags are needed)
g++ -std=c++11 cpuload.cpp -o cpuload
# run the program with callgrind; generates a file callgrind.out.12345 that can be viewed with kcachegrind
valgrind –tool=callgrind ./cpuload
# open profile.callgrind with kcachegrind
kcachegrind profile.callgrind
与gprof相反,我们不需要使用任何特殊的编译标志来重建应用程序。我们可以像valgrind一样执行任何可执行文件。当然,执行的程序应该包含调试信息,以获得具有人类可读符号名称的表达性调用图。
下面是一个KCachegrind,其中包含cpuload演示的评测数据:
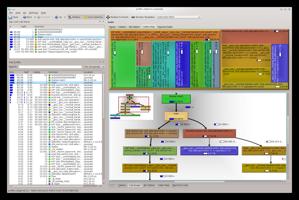
原是Google内部的性能分析工具,后来在Github上开源了,地址是https:///gperftools/gperftools。这套工具提供了CPU探查器、快速线程感知malloc实现、内存泄漏检测器和堆探查器。gperftools 的工作原理为通过定期采样当前正在执行的指令进行性能分析,如果某个函数被采样到的次数越多,则该函数在执行时占用的时间比例越大,很可能就是性能瓶颈。 gperftools 可以在被测软件处于 Release 模式下进行性能分析,所以能最大程度的模拟软件的实际使用情况。这个工具使用起来也非常简单,只需Preload其.so文件并指定生成的Profiling文件路径即可,命令为LD_PRELOAD=/usr/lib/libprofiler.so CPUPROFILE=./test.prof ./test。程序结束之后,使用命令google-pprof –web ./test ./test.prof即可查看热点分析结果。使用该工具Profiling无需重新编译代码,也支持多线程和链接库的热点分析,同时由于其是通过定期采样正在执行的指令进行热点分析,所以Profiling速度非常快,和正常release下执行程序的速度几乎相当。通过试用,发现gperftools的易用性、可视化效果等都是最好的,所以推荐大家使用gperftools。
下面主要介绍一下CPU profiler的使用情况。
使用gperftools创建应用程序选定部分的CPU配置文件需要以下步骤:
编译程序时启用调试符号(以获得有意义的调用图),并链接gperftools profiler.so
#include <gperftools/profiler.h>,并要使用ProfilerStart(“nameOfProfile.log”);和ProfilerStop()包围需要分析的代码块;
执行程序以生成分析数据文件
要分析评测数据,请使用pprof(与gperftools一起分发)或将其转换为与callgrind兼容的格式,然后使用KCachegrind进行分析。
测试脚本如下:
#!/bin/bash
# build the program; For our demo program, we specify -DWITHGPERFTOOLS to enable the gperftools specific #ifdefs
g++ -std=c++11 -DWITHGPERFTOOLS -lprofiler -g ../cpuload.cpp -o cpuload
# run the program; generates the profiling data file (profile.log in our example)
./cpuload
# convert profile.log to patible format
pprof –callgrind ./cpuload profile.log > profile.callgrind
# open profile.callgrind with kcachegrind
kcachegrind profile.callgrind
gprof是经过评估的剖析器中的恐龙——它的起源可以追溯到20世纪80年代。在过去的几十年里,它似乎得到了广泛的应用,是一个很好的解决方案。但它对多线程应用程序的支持有限,无法分析共享库,需要使用兼容的编译器和特殊标志重新编译,这会产生相当大的运行时开销,因此不适合在当今的实际项目中使用它。
Valgrind提供最精确的结果,非常适合多线程应用。它非常容易使用,并且有KCachegrind用于可视化/分析分析分析分析数据,但是被测应用程序的缓慢执行使其无法用于更大、运行时间更长的应用程序。
gperftools CPU profiler的运行时开销很小,提供了一些很好的功能,比如有选择地分析某些感兴趣的领域,并且对多线程应用程序没有问题。KCachegrind可用于分析分析分析数据。与所有基于采样的探查器一样,它存在统计不准确性,因此结果不如Valgrind准确,但实际上这通常不是什么大问题(如果需要更准确的结果,可以随时增加采样频率)。推荐使用它。
当我们用机器人做压力测试, 往往会发现DB队列总是一个痛点.
整个核心思想就是减少每一个包上的编解码消耗(以及产生的垃圾对象),并且在一定程度上实现合批(比如,每个逻辑帧合并一批的网络消息;或者消息累加到一定数量/大小,再合并发出).
合理规划同步消息, 例如:
内存分配情况,需要借助于Visual Studio之类的工具来分析了, 具体可以看前面的文章。 处理方式也比较简单–使用pool,重写内存分配器;找到一个非法使用情况,就fix一个.
比较容易遗漏的小型对象的申请:比如闭包,如闭包在Player处理某个东西时候需要,那么就把闭包和闭包的状态存在Player对象上(闭包也是一个小型对象);临时的容器,这个可以使用threadlocal来优化,每次用的时候clear一下。
还有一个比较关键的是, Linux下native部分的内存分配. 可能服务器在Windows Server下长时间跑, 都没有内存泄漏, 但是在Linux下跑会有内存泄漏, 最后查找原因是非托管部分泄漏了. 可尝试换成jemalloc之后解决。
用profile工具优化性能时,内存申请释放可能会影响部分性能(特别是很多小型对象),比如某些语言的GC(如java,c#),会很耗时;频繁的申请释放内存,即使对c或c++这样的语言来说,也是极力避免的。考虑使用内存池技术,提升申请和释放效率。
当内存/GC问题解决掉了之后,之前提到的很多性能问题都可能会被缓解,包括DB执行更新操作耗时越来越长这样的情况(当然首先得是db本身压力不大)。
物理引擎的耗时,很可能会占用整个逻辑帧30%左右的时间片。比如,用一些高效的碰撞器替代计算复杂的碰撞器,比如球型碰撞器的性能 > Box碰撞器 > Mesh碰撞器。对非必要的高频操作降频处理(如调整物理引擎fixedUpdate)等。另外,物理引擎建议和逻辑功能分开成不同的服务器。
每逻辑帧处理的功能越少,计算量越少,在精度等因素允许的情况下尽可能减少每帧的运算量。可以分帧处理某些复杂逻辑。
多线程/并行化,可以使用线程池或并行库(ppl/tbb)等来提升并发处理能力。
以上就是关于gg修改器对网络游戏有用吗_gg可以修改网游吗的全部内容,希望对大家有帮助。
Gg修改器免root下载,GG修改器免root下载安装最新 大小:4.63MB10,775人安装 不管失败多少次,都要面对生活,充满希望。 大家好,今天小编为大家分享关于Gg修改……
下载
GG修改器app最新版,GG修改器app最新版:让你High到爆 大小:17.03MB9,546人安装 作为一名游戏爱好者,怎么能错过GG修改器app最新版呢?它不仅可以帮你解锁更多的游……
下载
gg修改器专属框架中文版_gg修改器可用的框架 大小:4.28MB10,739人安装 大家好,今天小编为大家分享关于gg修改器专属框架中文版_gg修改器可用的框架的内容……
下载
gg修改器下载中文官方,GG修改器下载中文官方,让你玩游戏更畅快 大小:18.11MB9,394人安装 在玩游戏的时候,我们都希望拥有更好的游戏体验,而GG修改器下载中文官方就是一个能……
下载
gg游戏修改器打开框架,GG游戏修改器:改写游戏规则,玩出不一样的心情 大小:17.71MB9,702人安装 对于很多游戏玩家而言,想要玩得更加畅快、轻松,敢于尝试新的玩法,注重个性体验,……
下载
gg游戏修改器进游戏教程,GG游戏修改器:让游戏更加自由 大小:11.89MB9,586人安装 GG游戏修改器是一个非常实用的游戏修改工具,可以帮助玩家轻松地修改游戏内的各种参……
下载
gg修改器免root版最新下载,GG修改器免ROOT版,为玩家带来崭新体验 大小:5.04MB9,806人安装 如果你是一位游戏爱好者,那么你一定知道GG修改器。作为一款强大的游戏修改软件,GG……
下载
gg免root修改器下载_GG修改器免root版中文下载 大小:13.33MB10,821人安装 大家好,今天小编为大家分享关于gg免root修改器下载_GG修改器免root版中文下载的内……
下载
gg修改器咋用root,GG修改器是什么? 大小:19.81MB9,639人安装 GG修改器是一款必须要root权限的安卓游戏修改软件,它可以让你尝试修改你所喜欢的游……
下载
gg游戏修改器怎样修改网游,gg游戏修改器:改变你的游戏体验 大小:16.84MB9,397人安装 你是否曾经为游戏中遇到的困难而烦恼?是否曾经为游戏中的道具难以获得而感到苦恼?……
下载